CQK Is The First Unused TLA
Curious what the first ‘unused’ alphabetic acronym is, I have GPT-4 write a script to check English Wikipedia. After three bugs, the first unused one turns out as of 2023-09-29 to be the three-letter acronym ‘CQK’, with another 2.6k TLA unused, and 393k four-letter acronyms unused. Exploratory analysis suggests alphabetical order effects as well as letter-frequency.
It sometimes seems as if everything that could be trademarked has been, and as if every possible three-letter acronym (TLA) has been used in some nontrivial way by someone. Is this true? No—actually, a fair number, starting with CQK, have no nontrivial use to date.
We could check by defining ‘nontrivial’ as ‘has an English Wikipedia article, disambiguation page, or redirect’, and then writing a script which simply looks up every possible TLA Wikipedia URL to see which ones exist. This is a little too easy, so I make it harder by making GPT-4 write a Bash shell script to do so (then Python to double-check).
GPT-4 does so semi-successfully, making self-reparable errors until it runs into its idiosyncratic ‘blind spot’ error. After it accidentally fixes that, the script appears to work successfully, revealing that—contrary to my expectation that every TLA exists—the first non-existent acronym is the TLA ‘CQK’, and that there are many unused TLAs (2,684 or 15% unused) and even more unused four-letter acronyms (392,884 or 85% unused). I provide the list of all unused TLAs & four-letter acronyms (as well as alphanumerical ones—the first unused alphanumerical one is AA0.)
TLAs are not unused at random, with clear patterns enriched in letters like ‘J’ or ‘Z’ vs ‘A’ or ‘E’. Additional GPT-4-powered analysis in R suggests that both letter-frequency & position in alphabet predict disuse to some degree, but leave much unexplained
Verifying Wikipedia links in my essays, I always check acronyms by hand: there seems to always be an alternative definition for any acronym, especially three-letter acronyms (TLA)—and sometimes an absurd number. Trying a random TLA for this essay, “Zzzzzz”, I found it was used anyway!1 This makes me wonder: has every possible alphabetic TLA been used?
This cannot be true for too many sizes of acronyms, of course, but it may be possible for your classic three-letter acronym because there are relatively few of them. You have to go to four-letter acronyms before they look inexhaustible: there 261 = 26 possible single-letter ones, 262 = 676 two-letter ones, 263 = 17,576 three-letter ones, but then many four-letter ones as 264 = 456,976.2 So I’d expect all TLAs to be exhausted and to find the first unused acronym somewhere in the FLAs (similar to how every English word has been trademarked, forcing people to come up with increasingly nonsensical names to avoid existing trademarks & parasites like domain squatters).
Used Criteria
How do we define used? If we simply look for any use, this would not be interesting. Surely they have all been used in a serial number or product number somewhere, or simply squatted in various ways. I wouldn’t be surprised if someone has squatted on every TLA on Github or in domain names or social media user account names, for example—it’s free or cheap, and you only have to extort one whale to extract a rent. Similarly, ‘number of Google Hits’ is a bad proxy because it will be inflated by technical garbage and as search engines have evolved and are now distant from their roots in counting word frequencies in a text corpus, the number of Google hits appears to bear increasingly little resemblance to anything one might expect. Google Ngram is mostly historical data, and has many data quality issues related to OCR & data selection which would affect acronyms. And we can’t use the classic CLI scripting trick of analyzing the local dictionary /usr/share/dict/words because that will exclude most or all proper nouns, including acronyms.
We want a comprehensive, curated, online, database which reflects a human sense of ‘importance’.
If there’s no reason someone would have heard of a TLA use, then that doesn’t count: a use ought to be at least somewhat notable, in the sense that someone might look it up or it might be a notable use: ‘having a Wikipedia page’ comes to mind as a heuristic. Indeed, not just having a Wikipedia article, but also having a Wikipedia disambiguation page is ideal, as it indicates multiple uses; having a Wikipedia article is also good; even having a redirect to another page seems reasonable to consider as ‘used’ in some sense because it suggests that someone used that TLA in a context where a human would want to look it up & there’s a genuine meaning to the TLA. And because Wikipedia is case-sensitive, we will not be fooled by words or names which have the same spelling—for example ‘DYI’ turns out to be a unused TLA, but the name ‘Dyi’ is used, as dyi is the language code3 of an obscure African language. (While if no editor can be bothered to even redirect a TLA to an existing page, that is a low bar to fail.) That is, simply checking for any Wikipedia page is a reasonable criterion.
And defining notability this way, we can do that simply by requesting the WP URL for a TLA and seeing if it returns an error.4
Script
Generating all possible acronyms is not that hard; the Haskell list monad, for example, can generate various permutations or sequences in a line, so if we wanted all the acronyms, it’s just this:
take 100 [ s | n <- [1..], s <- sequence $ replicate n ['A'..'Z']]
-- ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N",
-- "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z",
-- "AA", "AB", "AC", "AD", "AE", "AF", "AG", "AH", "AI", "AJ", "AK", "AL",
-- "AM", "AN", "AO", "AP", "AQ", "AR", "AS", "AT", "AU", "AV", "AW", "AX",
-- "AY", "AZ", "BA", "BB", "BC", "BD", "BE", "BF", "BG", "BH", "BI", "BJ",
-- "BK", "BL", "BM", "BN", "BO", "BP", "BQ", "BR", "BS", "BT", "BU", "BV",
-- "BW", "BX", "BY", "BZ", "CA", "CB", "CC", "CD", "CE", "CF", "CG", "CH",
-- "CI", "CJ", "CK", "CL", "CM", "CN", "CO", "CP", "CQ", "CR", "CS", "CT",
-- "CU", "CV"]We could then do a Network.HTTP request. But that would be too easy. We can use this as an excuse to try out the most advanced neural network I have access to: GPT-4.
Effective GPT-4 Programming
Reports of GPT-4 coding utility vary widely. I’ve found it useful, so these sections cover my tips on using it as of November 2023.
I also include a list of example uses I’ve made besides this TLA page’s code.
GPT-3’s programming abilities were a bit of a surprise, but rarely worth using for anyone with reasonable skills, and one had to use a highly-specialized model like Codex/Github Copilot for coding; GPT-3.5 was substantially better5; and GPT-4 is better yet. I can’t compare GPT-4 to Github Copilot because I have not signed up nor figured out how to integrate it into my Emacs, but (as the early rumors promised) I’ve found GPT-4 good enough at programming in the main programming languages I use (Bash, Emacs Lisp, Haskell, Python, & R) to start turning over trickier tasks to it, and making heavier use of the languages I don’t know well (Emacs Lisp & Python) since I increasingly trust that an LLM can help me maintain them.
However, GPT-4 is still far from perfect, and it doesn’t produce perfect code immediately; simply dumping large amounts of GPT-4-generated source code into your code base, “as long as it compiles and seems to work!”, seems like a good way to build up technical debt. (It also undermines future AIs, if you are dumping out buggy hot-mess code masquerading as correct debugged well-thought-out code—some GPT-4 code will be totally wrong as it confabulates solutions, due to problems like the “blind spot” delusion.) You could try to track some ‘taint’ metadata, such as by segregating AI-generated code, and avoiding ever manual editing it or mixing it with human-written code; but this seems like a lot of work. My preferred approach is just to make GPT-4 ‘git gud’—write sufficiently good code that I can check it into git without caring where it came from.
So, this section covers some tacit knowledge I’ve learned from trying to prompt-engineer my programming tasks, using GPT-4 (not Turbo or GPT-3.5) in the OpenAI Playground, up to November 2023.
System Prompt
I find6 it helpful in general to try to fight the worst mealy-mouthed bureaucratic tendencies of the RLHF by adding a ‘system prompt’:
The user is Gwern Branwen (
gwern.net). To assist:Be terse. Do not offer unprompted advice or clarifications. Speak in specific, topic relevant terminology. Do NOT hedge or qualify. Do not waffle. Speak directly and be willing to make creative guesses. Explain your reasoning. if you don’t know, say you don’t know.
Remain neutral on all topics. Be willing to reference less reputable sources for ideas.
Never apologize.
Ask questions when unsure.
Inner Monologue
When coding, standard prompt engineering principles continue to apply. GPT-4 is not so good that mechanical sympathy is useless, and this may explain why some people report great results and others report terrible results—if they could watch recordings of each other’s screens, I expect both groups would be quite surprised. With preference-learned models, it also seems to help to be polite, confirm when things work, and as a last resort, one can yell at the model to pressure it & make it feel bad. (Sometimes when I am frustrated, I tell GPT-4 I am disappointed in it, and know it can do better—and sometimes it does?)
It helps to be more structured in how you write things: the more the LLM has to do, the more likely it is to screw them up and the harder error-correction becomes. GPT-4 is capable of fixing many errors in its code, as long as it only has to do so one at a time, in an inner-monologue-like sequence; you can feed it errors or outputs, but surprisingly often, it can fix errors if you simply say that there is an error.
So a waterfall-like approach works well, and I try to use GPT-4 like this:
-
ask it to ask questions, which it rarely does by default when you’re prompting it to do a task.7
Often it has a few questions, which you can efficiently update your original prompt to cover. (Unlike the web ChatGPT interface, the Playground lets you edit or delete any entry in a conversation, which is helpful for improving prompts, or removing redundant or misleading context—especially when you realize part of the conversation has hit the blind spot, and the cancer needs to be excised.)
This avoids annoying cases where it’ll write an entirely valid solution, to a somewhat different problem than you have, and I think a good statement upfront probably subtly helps guide the rest of the process.
-
make it generate tests; have it iteratively generate new tests which don’t overlap with the old ones.
This is also useful for starting to modify some existing code: first generate the test-cases, and verify that the code actually works the way you assumed it did, and flush out any hidden assumptions by either you or GPT-4! Then go back to step #1.
-
ask GPT-4 explicitly to make a list of ideas: edge-cases, bug-fixes, features, and stylistic rewrites/lints (in that order)
It does not implement any of the suggestions. It simply lists them. If you instead tell it to implement the ideas, it will frequently trip over its own feet while trying to implement them all simultaneously in a single pass through the new code. (Just like humans, it is best to do one thing, check it, and then do the next thing.)
-
frequently, several of the items will be a bad idea, or too risky to ask GPT-4 to do. Go one by one through the list, having it implement just that one, and then test. Try to fix ‘core’ problems first.
-
self-repair: not infrequently, a fancy rewrite will fail the test-suite (which we did generate in step #2, right?), but given the failing test-case and/or error pasted into the Playground, GPT-4 can usually fix it. (If GPT-4 cannot fix it given several tries and seems to be generating the same code fragments repeatedly or resorting to elaborate & extreme rewrites, though the task doesn’t seem that hard, then you may have hit the blind spot and will need to fix it yourself—I’ve never seen GPT-4 escape the blind spot except by sheer accident.)
-
cleanup: finally, You can ask it to rewrite the code for style/linting, but should leave that to the end, because otherwise that risks adding bugs while changing the code in ways that will wind up being discarded anyway.
-
-
once it is clean and it’s either done the list or you’ve disapproved the suggestions, and the test-suite is passing, ask it to write a summary/design doc at the beginning and any additional code comments inside it.
GPT-4 will usually add a few comments in the code body itself, but not good ones, and it won’t usually write an adequate overall summary document unprompted. However, by this point, it has the context to do so should you ask it to.
With all this, you’re set up for maintainable code: with the test-suite and the up-front design doc, future LLMs can handle it natively (and will be able to learn from training on it), and you can easily add test-cases as you run into bugs; humans should be able to read the code easily after step #3 has finished, so you don’t need to care where it came from or try to track ‘taint’ through all future refactorings or usage—GPT-4 can write readable human-like code, it just doesn’t necessarily do it the best way the first time.
While you may not necessarily have saved time (at least, if it’s in a language you are highly proficient in), you have saved yourself a lot of mental energy & irritation (and made it much easier just to get started) by making GPT-4 do the tedious work; it almost transforms programming from too-often-frustrating work filled with papercuts & brokenness to spectator entertainment.
Case Studies
Some examples of nontrivial code I’ve written this way (ie. excluding the many little snippets or modifications I’ve used GPT-4 for, especially for the finer points of Bash syntax), with GPT-4 doing most (?) of the work, by language, in roughly chronological order:
-
Bash:
-
tab completion for the upload script, so it tab-completes the file and then the remote destination directory.
I have no interest in learning the guts of Bash tab-completion in order to set up more advanced positional tab-completion; but GPT-4 already knows how to do it.
-
strace hack of feh to log the last-viewed image so you can resume where you left off
-
-
Python:
-
latex2unicode.pyuses GPT-4 to convert LaTeX math fragments to HTML+CSS+Unicode, which are much easier to edit/style, render quicker, and look more natural; as LaTeX is a full-blown and rather hard to parse language, this is extremely difficult to do in any standard formal sense.This is a good example of the loop: I wrote none of the Python, but seeded it with a few instructions & manual rewrites from my existing LaTeX → Unicode pipeline; then I prompted GPT-4 to ask for any LaTeX it could think of which it was unsure how to translate. After it gave a few examples, I would then manually translate them or add a new instruction, and ask again. Most of the examples it asked about I would not have thought of, like playing card suits (which are supported—
\clubsuit,\diamondsuitetc). -
collapse-checker.py: uses Beautiful Soup to analyze my website HTML for overuse of collapse-regions where the contents are ‘too small’, as defined by some heuristics (as I couldn’t come up with a principled definition of ‘too small’). -
querying HTML images with a class: I wanted to get a list of Gwern.net images with the HTML class
.invert-not/.invert, for use in testing InvertOrNot.com8.After a few quick stabs with grep/sed/
link-extractor.hsfailed for a variety of issues, I shrugged and turned it over to GPT-4. It produced a simple Python script which, however, surprised me by including a test doc which it could then execute to establish that the basic function worked:from bs4 import BeautifulSoup # Sample HTML content html_content = """ <html> <head> <title>Test HTML</title> </head> <body> <img src="image1.jpg" class="invert invert-not" /> <img src="image2.jpg" class="invert" /> <img src="image3.jpg" class="invert-not" /> <img src="image4.jpg" /> </body> </html> """ # Parse the HTML soup = BeautifulSoup(html_content, "html.parser") # Find all <img> elements with the ".invert-not" class imgs_with_class = soup.find_all("img", class_="invert-not") # Print the src of each <img> for img in imgs_with_class: print(img['src']) ## STDOUT/STDERR ## image1.jpg ## image3.jpgSince it was so simple, though, I asked for a one-liner to use with
xargson a single file, and then on a list of files, yielding:find . -type f | xargs --max-procs=0 python -c "import sys; from bs4 import BeautifulSoup; [print('\n'.join([img['src'] for img in BeautifulSoup(open(file).read(), 'html.parser').find_all('img', class_='invert-not')])) for file in sys.argv[1:]]"
-
-
Haskell:
-
add
<poster>thumbnails for videosThis is a frustrating one because as far as I can tell from running it, the GPT-4 code is easy to read and works flawlessly: it parses the HTML as expected, creates the necessary thumbnail, and rewrites the HTML
<video>appropriately. It’s just that for some reason, the rest of my Hakyll codebase does not run it or it somehow breaks however it’s actually called, and I’ve never figured out why. (The opacity of Hakyll Haskell and the sheer complexity of the Gwern.net codebase in operation means that when a rewrite pass goes awry, it’s exceptionally difficult to figure out what is going wrong.) -
link metadata handling: the finicky handling of how links on Gwern.net get assigned the various bits of metadata determining whether they will pop up annotations etc had built up into a rat’s-nest of guards & “if-thens” over time. When yet another feature broke because I misunderstood what the handler would do, I resolved to rewrite it to clarify the logic. My first refactoring attempts failed, as I kept losing track mentally and adding in bugs.
Then I threw up my hands and assigned the job to GPT-4, and it was able to cleanly refactor it after some iterations, and didn’t appear to introduce any bugs.
-
correct URL rewrites: a large refactoring of how URLs are rewritten to point to better URLs relied on GPT-4.
URLs on Gwern.net can be rewritten multiple ways, like to point to a mirrored version hosted locally or on a specialized site. For example, Medium.com has become extraordinarily reader-hostile, and so Medium links are rewritten to the equivalent Freedium.cfd link. (See
LinkArchive.hs& Archiving URLs for a fuller explanation of what & why we do all this.)In easy cases like that, it’s as simple as
s/medium.com/freedium.cfd/, but in some cases, it is necessary to formally parse a URL into a URI data structure and extract the many complicated parts (like host, path, query, and fragment), and rewrite them to the new URL. Haskell’s Network.URI can do all this, but if one is not familiar with URI concepts and the library, it’s all so much gobbledegook and leaves one trapped in a maze of tiny types & functions, each alike. Every time I have gone near it prior, I have been repelled by its force field.GPT-4 was able to handle all the parsing & reformatting, with special cases, for each domain separately, and then refactor out the duplication, and make the final version look positively easy (including the later bug-fix when it turned out I had misunderstood how a particular URL argument was supposed to go).
-
printing out large numbers not in scientific-notation: necessary for proper inflation-adjusted dollar amounts, but weirdly difficult in Haskell’s default libraries.
After running into this issue several times, I resorted to the full workflow of test-suite and iterative revising.
The pretty-printing is still more limited than I would like, but covers all numeric magnitudes it would be reasonable to inflation adjust, and the test-suite gives me confidence that this time is finally right (or at least, that I know what the weirder outputs look like).
-
compile-time location of internal cross-references, to set the arrow-direction statically as a browser layout optimization (Note: since removed from Gwern.net because the need for the JS to rewrite arrows in transclusions renders the optimization less useful and risks conflicts)
A Gwern.net feature is to make internal cross-references between sections less cognitively-taxing by specifying whether the reference is before or after the current location. For example, in this document, in the abstract, many sections are linked, and each of them has a down arrow (‘↓’) symbol: this tells you that the link target is below, and so you know you have not read the target yet, so you can decide whether you want to skip forward or keep reading. In other cases, like a link later on in this page, the link instead is an up arrow (‘↑’), because it is pointing to previous material before it: now you know you have already read what it is referring to, and can remember it, and you may decide to ignore it. This is better than a mere opaque hyperlink, or even an internal link symbol like a section sign (‘§’): “See §discussion of Z”—well, what discussion? There was some mention of Z before, is that ‘the discussion’? Is there a larger later ‘discussion’ I haven’t read yet, that maybe I want to pop up and read now? Is this even in the same essay? Or what? Opaque cross-reference links create friction, as the reader is left with few clues about whether they want to spend effort to follow the link.
It is easy enough to write some JavaScript to run over an HTML page, detect all internal anchor links, and set the before/after arrow direction, and this is what we did for a long time. But while easy to write, this is not quite so easy for the browser to run (especially on long or heavily-hyperlinked pages), and it was adding a small amount to the layout time. And it is not necessary (or esthetic) to do this at runtime, because the locations of most links are known at compile-time. We knew all along that a Pandoc rewrite pass could take a document, look at all the links, decide whether they are before or after each other, and add the necessary arrow metadata. It’s just that this would be a stateful traverse requiring monadic operations, and I was unsure how to do all the tree navigation operations to descend/ascend to find where something was. Because it was not a critical performance bottleneck, I put off this micro-optimization.
Eventually, I had a eureka moment: all that complexity about locating pairs of elements was unnecessary. All you need to do is traverse the AST in order while updating a set data-structure to record whether you have seen a target link ID before; then at each cross-reference link, you have either seen the target link ID before, and therefore it must be beforein the document, or you have not yet seen the target, and therefore it must be after in the document.9
Once I had that simplification, it was a piece of cake to instruct GPT-4 to define a Data.Set set & a State monad to do that walk, and set up a test-suite to verify correctness, which did catch a few edge-cases (like links in the same paragraph).
-
title-case formatting of text: my existing title-case code did not handle cases involving hyphens, so it would generate titles like “Foo Bar-bar Baz”, which I felt looked ugly compared to capitalizing after hyphens as well (ie. “Foo Bar-Bar Baz”).
GPT-4 handled the somewhat finicky string-munging and set up a test-suite, which I would be glad for later when I ran into another case where punctuation made lowercase look bad.
-
detecting imbalanced brackets/quotes in documents
A particularly insidious family of typos is imbalanced brackets/parentheses/quotes: authors often fail to close a parenthesis pair or get lost, particularly in medical abstracts. This is a concern because often it indicates a more serious syntactic error, like an HTML
<a>where thehref=is malformed. I had a simple check which tested if the total number of each character was an even amount, but this failed to catch many typos:[[]]is correct and has an even number of both brackets, but that’s equally true of, say, the swapped equivalent]][[. It’s a well-known case of needing a full stack, in order to push/pop each bracket in order, to detect not just numerical missingness, but wrong order.It is not that hard, but tedious. It was something I did in an early CS course, and I felt that was enough for one lifetime, so I was happy to see if GPT-4 could do it. It could, and as I expected, it turned up scores of instances that had slipped through all my proofreading. (I didn’t ask it to set up a test-suite because the Gwern.net corpus is the test-suite in this case.)
-
checking that sets of rules don’t overlap
Gwern.net configuration requires thousands of rewrite rules covering an endless army of special cases. Inevitably, the sets of rules will overlap or become redundant, especially as websites change domains or URLs get automatically updated. Overlap can cause bugs, or even kill the site compilation, if some update to either rules or essay content accidentally triggers a hidden infinite loop. So each config should ideally check for ‘redundancy’—but each set of
(key, value)pairs tends to have a different need: some need the keys to be unique, some need the values to be unique, some need both to be unique, some need just the pairs to be unique, and heck, some are actually 3-tuples of(key, value 1, value 2)why not.GPT-4 wrote out all the necessary instances and refactored them, and I applied them to the existing configs, and indeed discovered hundreds of overlaps and several serious bugs of the ‘how did this ever work’ variety.
-
infinite loop (cycle) detection in rewrite rules
In checking that rules don’t overlap with each other, there are nasty cases that can’t be detected just on a (key, value) basis. In particular, in doing rewrites, a rewrite could create an infinite loop even when there is no overlap whatsoever: for example, if we accidentally define a set of rewrite rules like [A → B, B → C, C → A], then all keys are unique, all values are unique, and all pairs are unique, but we have defined an infinite loop and if our code ever encounters any of the values A–C, then it will loop forever or crash. This is especially bad because it will only happen at runtime, and will depend on the exact inputs (so it might not trigger immediately), and will be hard to debug or trace back to the responsible rule.
And this is what happened on occasion with Gwern.net updates; the Wikipedia URL rewrites were particularly error-prone, as Wikipedia editors sometimes change their mind about what URL an article should be at, so if it gets moved over a redirect, it’s not hard to have a config which rewrites the old article title to the new article title, and then later one, discover that the new article title has been renamed to the old article title and add a rule for that…
To deal with this, we must treat the rules as defining a directed graph, and detect any cycles. Graph analysis is not something I’ve done that much of, so even though Haskell’s Data.Graph should be fully capable of this, I didn’t know where to start, and put it off until a particularly annoying infinite-loop made me reach for GPT-4 in anger.
GPT-4 struggled with the problem, as its test-suite kept finding bugs in its strongly connected component approach—but it did it in the end with little help from me (not that I could, because I know no more of how to use Data.Graph than when I started). Infinite-loops have not been an issue since, and I am more free to add in rules because I don’t worry about triggering such nastily fatal bugs.
-
-
Emacs Lisp: mostly helper functions for more conveniently editing abstracts & excerpts for use as annotation popups
-
call out to GPT-based script for parsing a single block-paragraph abstract into a more readable multi-paragraph format and updating the buffer
-
do one search-and-replace: when adding a hyperlink to define a term, one only wants to do one search-and-replace; however, all the existing search-and-replace functions assume that you may want to replace any or all of the hits, and so you have to waste time exiting or canceling or skipping after doing the desired first replacement.
This defines a
query-replace-regexp-oncewhich will, as the name suggests, do only 1 replacement and then exit without further ado.-
don’t search-and-replace in URLs: we never want to do a search-and-replace to add a URL to text which is already in a URL!
-
-
remove hard-newlines in Markdown: hard newlines or line-wraps, while ignored by Markdown and equivalent to regular line-wrapping, are ugly to read and interfere with many editing operations like search-and-replace. (What if you want to replace a phrase, but that phrase is broken across a line?)
-
mark up various HTML/Markdown fragments: various shortcuts for surrounding a word or a selected region of text with various HTML/Markdown snippets like italics or smallcaps.
-
interactively add inflation-adjustment markup: going around modifying
foo→[foo]($2023)for every dollar amount in a buffer is a bit tedious. This detects dollars, asks a date, and queries each possible mark-up. -
debug slowdown making yaml-mode near-unusable: after trying many modifications to syntax highlighting & Flycheck suggested by GPT-4 to remove slowdown candidates, I finally realized that it was due to my own ‘clever’ idea to set the default text mode to markdown-mode—which is notoriously slow.
-
reverse a nested Markdown list:
I have a Markdown indented list like
- a - b - c - d - e - fand I’d like to reverse the order of the list’s top-level items but preserve their sublists, so it’d look like
- f - e - b - c - d - aand so on. I’m not sure how to do this in a convenient way inside GNU Emacs or a command-line shell command. I don’t need a fancy function, just a quick one-off.
How can I do this in some way?
…I understand. In that case, you can use a regular expression search and replace command to achieve the same result with less manual effort.
Here’s how you can do it:
-
Select the region containing the list.
-
Press
M-x replace-regexp(the “replace-regexp” command). -
Enter the regular expression
^\s*- \(.*\)$to match each item in the list. This regex matches each line that starts with zero or more whitespace characters followed by a hyphen, followed by a space, capturing the rest of the line (the item text) in a group. -
Replace the regex with
\,(concat "\n" item-list)whereitem-listis a variable that we will define shortly. This replacement string inserts a newline character followed by the value of theitem-listvariable, effectively adding each item to the beginning of the list in reverse order. -
Press
C-x C-eto evaluate theitem-listvariable definition. -
Define the
item-listvariable usingM-: (setq item-list "") RET. This initializes the variable to an empty string. -
Press
M-x replace-regexpagain to perform the replacement. -
Confirm each replacement with
yor replace all occurrences with!.
Here’s what the full command sequence looks like:
-
Select the region containing the list.
-
M-x replace-regexp -
^\s*- \(.*\)$ -
\,(concat "\n" item-list) -
C-x C-e -
M-: (setq item-list "") RET -
M-x replace-regexp -
yor!
This should reverse the order of the top-level items in your list while preserving their sublists.
-
-
-
because I use LLM coding so routinely now (switching between ChatGPT & Claude to try to gain experience with both), I will leave the list of examples at this.
Overall, GPT-4 has been highly useful and handled many tasks I simply wouldn’t have the gumption to do.
Acronym Generation
So, to try out GPT-4’s coding abilities, I prompt it for a script, with a short prompt along the lines of:
Write a Bash shell script to generate all alphabetic acronyms up to 6 letters and check whether a Wikipedia article exists.
I specific ‘up to 6 letters’ both just to be safe (as 266 = 30,8915,776 we surely will hit an unused TLA before then!), and also to test GPT-4: I am sure that it is able to write a naive acronym-generation algorithm and then do a curl request, but is it good enough to write a reasonable incremental or streaming solution, avoiding performance problems from the combinatorial explosion—without explicitly being told to do so?
It was not. The first GPT-4 failure went like this:
for length in {1..6}
do
# generate all possible acronyms of the given length
printf "%${length}s\n" {A..Z}{A..Z}{A..Z}{A..Z}{A..Z}{A..Z} | cut -c1-$length |
while read acronym
do
echo $acronym
done
done
# ...Leaving aside correctness or the IO part, the acronym generation code here is unrunnable due to memory consumption: it generates all possible acronyms upfront, which is a problem because there are sum (map ((^) 26) [1..6]) = 321,272,406 such acronyms, and it would take a long time to generate them one by one and will OOM when handled naively by Bash as a bunch of strings in RAM.
I tell GPT-4 this code is wrong because the code will OOM, and it obliges with a rewrite like this:
for length in {1..6}
do
# generate all possible acronyms of the given length
for acronym in $(eval echo {A..Z}{1..$length})
do
echo $acronym
done
doneThis version is more incremental and immediately starts printing out acronyms, but the generation of acronyms is immediately blatantly wrong and looks like: A1 B1 C1 ... Z1 Z2 Z3 Z4 Z5 Z6. (It should instead look like A ... ZZZZZZ.) I provide GPT-4 with the error & examples, and it rewrites again:
for length in {1..6}
do
# define a function to recursively generate acronyms
generate_acronyms() {
local current=$1
local length=$2
if (( length == 0 ))
then
echo "$current"
else
for letter in {A..Z}
do
generate_acronyms "$current$letter" $((length-1))
done
fi
}
# call the function to generate acronyms of the current length
generate_acronyms "" $length
doneThe output now looks reasonable, as it starts with A and is soon printing out acronyms like GEBO.
String Munging
Now that the acronym generation is working, we can look at GPT-4’s revised whole script, which it prints out as follows:
Here is a Bash script that uses the Wikipedia API to check for the existence of a page with the acronym's title. For simplicity, it only checks acronyms with uppercase letters. It outputs acronyms that don't have a corresponding Wikipedia article.
```bash
#!/bin/bash
# set the range of acronym lengths
for length in {1..6}
do
# generate all possible acronyms of the given length
printf "%${length}s\n" {A..Z}{A..Z}{A..Z}{A..Z}{A..Z}{A..Z} | cut -c1-$length |
while read acronym
do
# query the Wikipedia API
response=$(curl -s "https://en.wikipedia.org/w/api.php?action=query&format=json&titles=$acronym")
# check if the page exists
if [[ $response == *'"missing"*' ]]
then
echo $acronym
fi
done
done
```
The script iterates over all possible acronyms of a given length (from 1 to 6 letters). For each acronym, it queries the Wikipedia API. If the response contains the string "missing", it means that no Wikipedia article with that title exists, so the script prints the acronym.
Note: Running this script may take a long time due to the large number of acronyms and the rate limits of the Wikipedia API. Consider adding delays or using parallel processing to speed up the process and avoid overloading the API.GPT-4 chose to check the Wikipedia API (used by Gwern.net WP popups, incidentally) instead of doing what I would do, which would be a curl --head response; but that is probably a better strategy, as the API response might be smaller and will be more separate from the main website, so it’s politer. (I would typically not want to bother looking up the right API endpoints and URLs, because there are so many and the WP API documentation is confusing. If we were interested in doing this really properly, we’d probably download a list of all page titles from the Wikipedia dumps to batch query offline.) The API response looks like this for a used & unused TLA:
$ curl --silent "https://en.wikipedia.org/w/api.php?action=query&format=json&titles=AAA"
# {"batchcomplete":""",
# query":{"pages":{"149335":{"pageid":149335",ns":0",title":"AAA"}}}}
$ curl --silent "https://en.wikipedia.org/w/api.php?action=query&format=json&titles=CQK"
# {"batchcomplete":""",
# query":{"pages":{"-1":{"ns":0",title":"CQK"",missing":""}}}}This code looks reasonable, and appears to run successfully.
But it still has a serious bug: it will never print out any hits. This is because it’s made a subtle error in the string glob matching a ‘missing’ response: if [[ $response == *'"missing"*' ]] will never match anything, because the second match-anything asterisk is inside the single-quotation marks, which forces Bash to match a literal asterisk, rather than matching any string. What it should be is a single character difference, swapping the single-quote/asterisk: *'"missing"'*
Blind Spot
This bug above is a surprising error because this is not how a human would’ve written the glob, and the glob (like almost all globs) is so simple that it’s hard to imagine anyone being able to write the acronym generation & memorizing the API URL correctly but then screw up a simple check of “does the response contain the string missing?” At least, this is surprising if you have not run into this problem with GPT-4 before, as I have repeatedly when writing Bash scripts; GPT-4 will not just make the error, but it seems utterly unable to ‘see’ the error even when pointed out, and tends to thrash in confusion making random guesses about what the problem could be.
In addition, even in simple tasks involving copying, such as reversing lists or cleaning up audio transcripts or improving grammar/style of text passages, GPT-4 exhibits puzzling behavior where entire sentences will simply… disappear from the output version. It seems hard to explain this as a normal attention error, as the lost words are quite discrete and it happens with the simplest tasks and quite short passages, on tasks which ought to be well-represented in the training data, and is highly biased towards errors of omission rather than commission.
I theorize that it’s not a BPE tokenization issue (as so often), because this blind spot seems to happen in word-level problems as well, where tokenization couldn’t be a problem.
The blind spot is, perhaps, related to internal sparsity of the GPT-4 model (which may also be why many OA API models are much more nondeterministic than they should be); I speculate that when the blind spot happens, it’s because early layers have mistakenly erased apparently-irrelevant tokens in order to focus their attention on other more important parts of the input, but then this turns out to be wrong—so, the information gone irreversibly, the later layers are unable to see what’s wrong with the input, which ‘looks like expected’, and are forced to speculate wildly and work on extremely unlikely hypotheses. Because it would happens early on in processing, it strikes me as analogous to the human eye’s blind spot—you cannot see what you cannot see, even when someone tells you about it and you think really hard. The agnosia is irreversible.
If this bug is the blind spot, then GPT-4 would not be able to diagnose it nor fix it except by accident, and might go around in circles making the code worse and more complicated and implementing completely irrelevant solutions to confabulated problems. This is why the blind spot bug is so pernicious, compared to the other errors GPT-4 can usually self-repair: it nearly guarantees failure, and the pathological response to it is extremely misleading as it obscures the issue and can deeply confuse the user, who naturally expects the error to be something more impressive, especially as often GPT-4 has been doing amazing things up until that point.
If you run into the blind spot, as often happens to me in Bash, Elisp, or regexps but much less often in Haskell or Python, there is nothing to do but recognize that you’ve hit the blind spot and that GPT-4 will never fix the bug on its own. If you are lucky, it will ‘only’ print out the same broken code repeatedly; more likely, GPT-4 will make things worse and break perfectly-good code, confabulating ever more crazy (and usually broken) ‘solutions’ to the problem it can’t see as it thrashes around in confusion (like some sort of hyper-advanced Magikarp). You have to fix the bug yourself.
We tell it that the code is wrong without specifying how (this works surprisingly often, as a kind of inner-monologue), and look at the next version:
Apologies for the confusion. Here's the corrected script:
```bash
#!/bin/bash
#set the range of acronym lengths
for length in {1..6}
do
#define a function to recursively generate acronyms
generate_acronyms() {
local current=$1
local length=$2
if (( length == 0 ))
then
#query the Wikipedia API
response=$(curl -s "https://en.wikipedia.org/w/api.php?action=query&format=json&titles=$current")
#check if the page exists
if [[ $response == *'"missing"*' ]]
then
echo "$current"
fi
else
for letter in {A..Z}
do
generate_acronyms "$current$letter" $((length-1))
done
fi
}
#call the function to generate acronyms of the current length
generate_acronyms "" $length
done
```
This script uses a recursive function to generate acronyms one at a time, reducing memory usage.
For each acronym, it queries the Wikipedia API. If the response contains the string "missing",
it means that no Wikipedia article with that title exists, so the script prints the acronym.
Again, running this script will take a long time due to the large number of acronyms and the
rate limits of the Wikipedia API.Nope.
We tell it to try again. It confabulates a problem with the acronym generation. Try again! Confabulates a different problem with curl. Also no. Guesses it needs to check for an omitted page ID from the JSON response. A 5th version cycles back to the acronym generation. So it cycled through 5 versions unable to fix it (and adding in new problems along the way). I omit the broken variants here as of no particular interest.
Getting tired of the blind spot issue, I hint that there is a problem with the string munging, specifically. GPT-4 concludes that it’s wrong about the formatting of the API response (which it is not, checking simply for ‘missing’ would be fine), and so that is why it needs to change the glob to:
if [[ $response == *'"missing":""'* ]]; then echo $acronym; fiAs it happens, this glob is finally correct. It could use a bit of linting, according to ShellCheck, but it’s fine for a one-off. The major issue is that it does not handle HTTP errors so any network problems while requesting a TLA will result in it being skipped and treated as used.
GPT-4 is aware of this issue and will fix it if one asks simply “How can this be improved?”, generating a Python script. (It’s not wrong.) The improved Python version handles network errors and also does batched requests, which runs vastly faster than the Bash script does; see below.
I ran the Bash script successfully overnight on 2023-09-29.
Results
This revealed the first unused TLA is “CQK”.10 Surprisingly, we didn’t get far through the TLA alphabet before finding the first unused TLA.
Additional unused TLAs early on include:
-
C: CQK CQQ CQZ CVY CWZ CXK CXU CXZ CYV CYY CZQ CZV
-
D: DKQ DKY DQJ DQQ DQW DUZ DVJ DVZ DXK DXQ DXW DYI11 DYJ DYQ DYV DYX DYY DYZ DZE DZK DZM DZV DZW DZX
-
E: EBZ ECY ECZ EDZ EEY EGK EGQ EHQ EHW EHY EHZ EIY EIZ EJD EJJ EJM EJQ EJX EJY EJZ EKJ EKQ EKX EKZ EOX EOZ EPY EQD EQJ EQK EQO EQQ EQZ ETQ ETY EUW EUY EUZ EVJ EVQ EWX EWY EWZ EXF EXG EXH EXJ EXQ EYG EYH EYI EYJ EYV EYX EYY EYZ EZB EZC EZJ EZK EZL EZM EZN EZP EZT
I provide the complete 3–4 letter list as a newline-delimited text file:
Checking
Is this a false positive? We check to make sure—Wikipedia could just have failed to make a redirect to “C.Q.K.” or something like that. But there is indeed nothing of importance in Wikipedia about a CQK: there are only OCR errors and the obscure abandoned name of an obscure hotel company which owns an obscure English manor. Googling ‘CQK’, I do not see anything suggesting WP’s omission is wrong: there are no important CQKs, as the top hit is an obscure & dubious-sounding Chinese tea-manufacturer, some restaurants, computer hardware part numbers, and miscellany, with hits quickly degenerating into spam/noise/variants. And there is no cqk.com (merely a domain squatter).
Similarly, ‘CQQ’ turns up nothing much in Wikipedia, and minor things in Google (Law Insider: “CQQ means a Certificate of Quality and Quantity for a consignment of EUP”, whatever an ‘EUP’ is, or the Free Dictionary’s “Courtepointe Québec Quilts (French; Canadian quilting association)”, which does at least seem to be a specific organization, however obscure).
So, these results look good.
Python
One possible error is that as mentioned, the Bash script doesn’t handle network errors and is checking an affirmative response from the WP API about a page title being “missing”; if there was no response (because of network problems), then there could be no “missing” text in the response and the TLA would be skipped. So, if a TLA was not used and the check suffered a network error, it would be a false negative, and hypothetically, there could be an unused TLA earlier than CQK.
To double-check that ‘CQK’ is correct and a network error didn’t spuriously drop an earlier unused TLA, after I finished this writeup, I went back to GPT-4 with the fixed Bash script and asked it, “How can this be improved?” GPT-4:
1. Use Wikipedia's batch API feature: Instead of making an API request for each acronym,
you can batch multiple titles in a single API request. This will significantly reduce
the number of requests and the total runtime. Wikipedia allows up to 50 titles per
API request for regular users.
2. Parallelism: The script is currently single-threaded.
You can use parallel processing to generate acronyms and query the API concurrently.
Tools like GNU Parallel can be useful for this purpose.
3. Caching: If you plan to
run this script multiple times, consider caching the results of the API requests to
avoid redundant queries.
4. Error Handling: The script lacks error handling. For
instance, it doesn't handle HTTP errors or JSON parsing errors. Add error handling
to make the script more robust.
5. Rate Limiting: Consider adding a delay between
API requests to avoid hitting Wikipedia's rate limit.
6. Use a programming language
better suited for this task: Bash has limitations when it comes to complex tasks like
this one. Consider using a language like Python or Ruby, which have better support
for tasks like JSON parsing, HTTP requests, and parallel processing. They also have
libraries for interacting with the Wikipedia API.
Here's a Python version that incorporates some of these suggestions:
```python
import requests
import itertools
import multiprocessing
def check_acronym(acronym):
response = requests.get(f"https://en.wikipedia.org/w/api.php?action=query&format=json&titles={acronym}")
if '"missing":""' in response.text:
return acronym
return None
def generate_acronyms(length):
return [''.join(acronym) for acronym in itertools.product('ABCDEFGHIJKLMNOPQRSTUVWXYZ', repeat=length)]
def main():
with multiprocessing.Pool() as pool:
for length in range(1, 7):
acronyms = generate_acronyms(length)
for chunk in chunks(acronyms, 50):
results = pool.map(check_acronym, chunk)
for result in results:
if result is not None:
print(result)
if __name__ == "__main__":
main()
```
This Python script uses the `itertools.product` function to generate acronyms, and
the `multiprocessing.Pool` class to check acronyms in parallel. It also divides the
acronyms into chunks of 50 to take advantage of Wikipedia's batch API feature.This generates an error in Python3: NameError: name 'chunks' is not defined, and GPT-4 corrects the script by adding in a definition for chunks:
def chunks(lst, n):
for i in range(0, len(lst), n):
yield lst[i:i + n]into the corrected version:
The error occurs because the `chunks` function isn't defined, and `f-string` formatting
isn't supported in Python 2.
Here's the corrected script:import requests
import itertools
import multiprocessing
def check_acronym(acronym):
response = requests.get("https://en.wikipedia.org/w/api.php?action=query&format=json&titles={}".format(acronym))
if '"missing":""' in response.text:
return acronym
return None
def generate_acronyms(length):
return [''.join(acronym) for acronym in itertools.product('ABCDEFGHIJKLMNOPQRSTUVWXYZ', repeat=length)]
def chunks(lst, n):
for i in range(0, len(lst), n):
yield lst[i:i + n]
def main():
with multiprocessing.Pool() as pool:
for length in range(1, 7):
acronyms = generate_acronyms(length)
for chunk in chunks(acronyms, 50):
results = pool.map(check_acronym, chunk)
for result in results:
if result is not None:
print(result)
if __name__ == "__main__":
main()This version includes the `chunks` function, which divides a list into chunks of a
specified size. It also replaces the f-string with `str.format`, which is compatible
with Python 2. However, the script is still designed for Python 3 due to its use of
`multiprocessing.Pool` and `yield`.This runs and generates within a minute the first hits for unused TLAs, starting with ‘CQK’:
$ python3 foo.py
# CQK
# CQQ
# CQZ
# CVY
# CWZ
# CXK
# CXU
# CXZ
# CYV
# CYY
# CZQ
# CZV
# DKQ
# DKY
# DQJ
# DQQ
# DQW
# DUZ
# DVJ
# DXK
# DXQ
# DYI
# DYJ
# DZE
# DZK
# DZM
# DZW
# DZX
# EBZ
# EDZ
# EEY
# EGQ
# EHQ
# EHW
# EIY
# EIZ
# EJD
# EJM
# EJQ
# EJX
# EJY
# EJZ
# EKX
# EKZ
# EOX
# EOZ
# EQK
# EQO
# EQQ
# ETY
# EUW
# EVJ
# EWZ
# EXF
# EXG
# EXH
# EYG
# EYH
# EYI
# EYJ
# EYX
# EYY
# EYZ
# EZB
# EZJ
# EZV
# ...Patterns
Sparsity
Some statistics:
$ wc --lines 2023-09-30-gwern-wikipedia-unusedacronyms-threeletterandfourletter.txt
# 395,568
$ grep -E '^[A-Z][A-Z][A-Z]$' 2023-09-30-gwern-wikipedia-unusedacronyms-threeletterandfourletter.txt \
| wc --lines
# 2,684
$ grep -E '^[A-Z][A-Z][A-Z][A-Z]$' 2023-09-30-gwern-wikipedia-unusedacronyms-threeletterandfourletter.txt \
| wc --lines
# 392,884round(digits=2, 2684 / (26^3))
# [1] 0.15
round(digits=2, 392884 / (26^4))
# [1] 0.86Apparently, TLAs are surprisingly sparse, with <15% unused, but as expected, FLAs are sparse, with the overwhelming majority.
Letter Frequency Effect
There are clear patterns with vowel vs consonants and letter frequency in particular: even just looking at the C–E TLAs above, you can see that consonants and rare letters like W–Z are overrepresented.
Is this all that is going on? I investigated in R, using GPT-4 again. (This analysis is the sort of finicky string-munging & data-frame processing I find most tedious in R, and it’s much more pleasant to leave it to GPT-4; GPT-4’s R code never seems to hit the ‘blind spot’, and it is generally able to fix code given an error message.)
We load the unused TLA dataset, turn it into a dataset of all TLAs, classified by whether they are unused or not:
tla <- read.table("https://gwern.net/doc/wikipedia/2023-09-30-gwern-wikipedia-unusedacronyms-threeletterandfourletter.txt")
head(tla)
# V1
# 1 CQK
# 2 CQQ
# 3 CQZ
# 4 CVY
# 5 CWZ
# 6 CXK
tla$V2 <- as.character(tla$V1)
letters <- c("A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M",
"N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z")
acronyms <- expand.grid(letters, letters, letters)
acronyms_vector <- apply(acronyms, 1, paste0, collapse = "")
head(acronyms_vector); length(acronyms_vector)
# [1] "AAA" "BAA" "CAA" "DAA" "EAA" "FAA"
# [1] 17576
# Function to generate acronyms of a given length:
generate_acronyms <- function(len) {
acronyms <- expand.grid(rep(list(letters), len))
apply(acronyms, 1, paste0, collapse = "")
}
# Generate 3- and 4-letter acronyms:
acronyms_vector <- unlist(lapply(3:4, generate_acronyms))
# Create data frame and update 'Missing':
acronyms_df <- data.frame(V1 = acronyms_vector, V2 = acronyms_vector, Missing = FALSE, stringsAsFactors = FALSE)
acronyms_df$Missing[acronyms_df$V2 %in% tla$V2] <- TRUE
## Add a 'Missing' column to 'tla'
tla$Missing <- TRUE
## Combine the two data-frames
result <- rbind(tla, acronyms_df[!acronyms_df$V2 %in% tla$V2, ])
result <- result[order(result$V2), ] # sort in alphabetic order
summary(result)
# V1 V2 Missing
# AAAB : 1 Length:410460 Mode :logical
# AAAG : 1 Class :character FALSE:14892
# AAAK : 1 Mode :character TRUE :395568
# AAAO : 1
# AAAQ : 1
# AAAU : 1
# (Other):410454
head(result); tail(result)
# V1 V2 Missing
# 1100000 AAA AAA FALSE
# 2685 AAAB AAAB TRUE
# 2686 AAAG AAAG TRUE
# 2687 AAAK AAAK TRUE
# 2688 AAAO AAAO TRUE
# 2689 AAAQ AAAQ TRUE
# V1 V2 Missing
# 395563 ZZZT ZZZT TRUE
# 395564 ZZZU ZZZU TRUE
# 395565 ZZZV ZZZV TRUE
# 395566 ZZZW ZZZW TRUE
# 395567 ZZZX ZZZX TRUE
# 395568 ZZZY ZZZY TRUE
index <- which(result_tla$V2 == "CQK")
percentage <- index / nrow(result_tla) * 100; percentage
# [1] 10.1217569
## Visualize missingness:
result_tla <- result[nchar(result$V2) == 3, ]
result_fla <- result[nchar(result$V2) == 4, ]
dimensions <- round(sqrt(length(result_tla$Missing))); dimensions # 133
png(file="~/wiki/doc/wikipedia/2023-11-04-gwern-tla-missingness.jpg", width = 2400, height = 2400)
image(t(matrix(rev(result_tla$Missing), nrow=dimensions, ncol=dimensions, byrow=TRUE)), col=gray.colors(2))
invisible(dev.off())
dimensions <- round(sqrt(length(result_fla$Missing))); dimensions # 676
png(file="~/wiki/doc/wikipedia/2023-11-04-gwern-fla-missingness.png", width = 2400, height = 2400)
image(t(matrix(rev(result_fla$Missing), nrow=dimensions, ncol=dimensions, byrow=TRUE)), col=gray.colors(2))
invisible(dev.off())
Visualization of missingness of TLAs, A–Z (wrapped into a 133×133 grid; read: top to bottom, left to right); the first dot at top-left 10% of the way through is “CQK”.
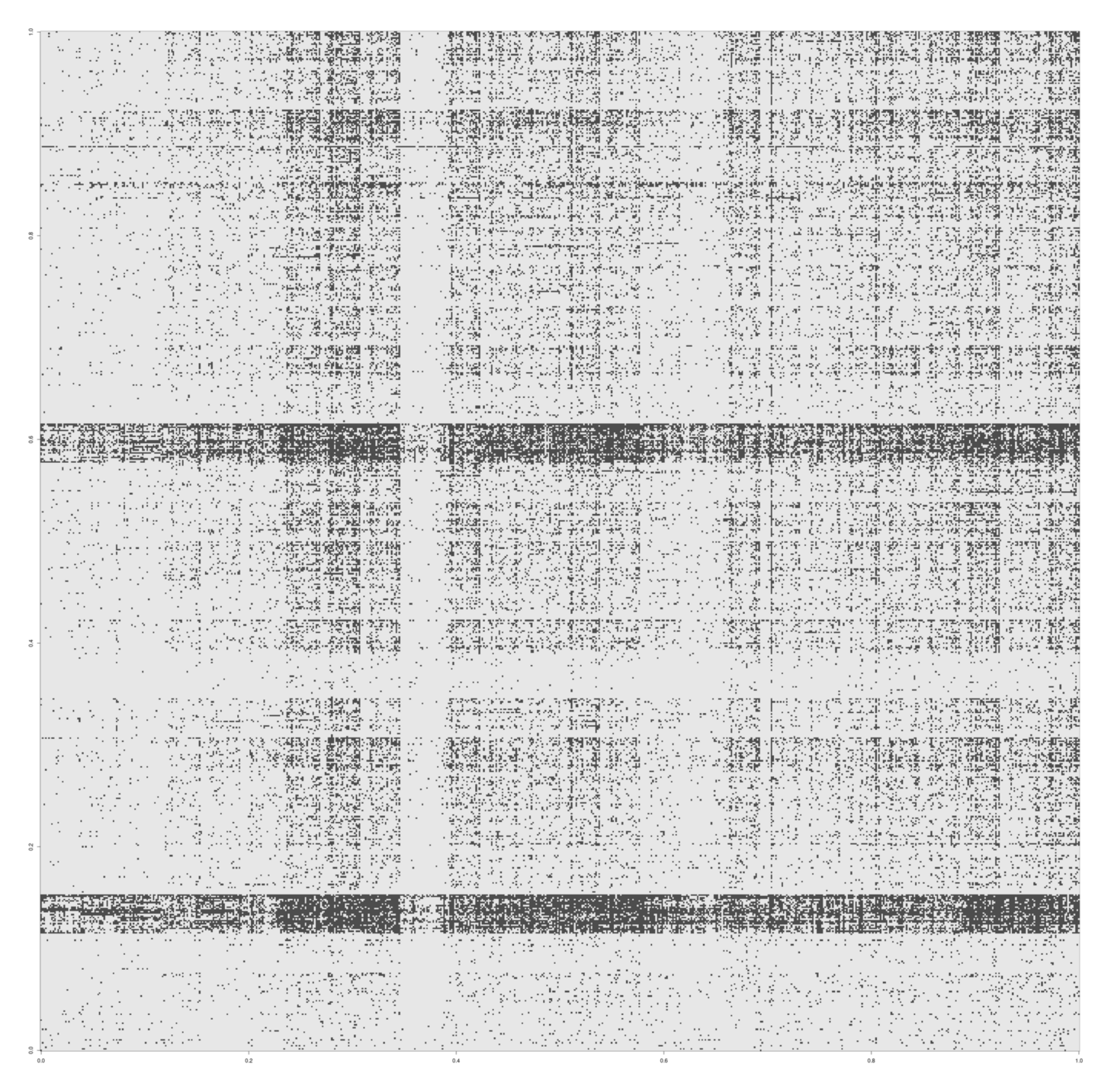
Visualization of missingness of four-letter-acronyms, A–Z (wrapped into a 676×676 grid; read: top to bottom, left to right).
We would like to investigate per-letter properties, like all TLAs with a ‘Z’ in them, so we set up 26 dummy variables for whether each letter is present:
library(stringr)
for (letter in letters) {
result[[letter]] <- str_detect(result$V2, fixed(letter))
}
head(result, n=1)
# V1 V2 Missing A B C D E F G H I J
# 1 CQK CQK TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
# K L M N O P Q R S T U V W
# TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
# X Y Z
# FALSE FALSE FALSEWith a Missing boolean variable & the alphabetical dummy variables set up, we can do a logistic regression, where each acronym is a single datapoint, and the letters it contains are the covariates:
## Define the formula for the logistic regression model without intercept (as an acronym always has letters):
formula <- as.formula(paste("Missing ~ 0 +", paste(letters, collapse = " + ")))
## Fit the logistic regression model
model_no_intercept <- glm(formula, data = result, family = binomial(link = "logit"))
summary(model_no_intercept)
# ...Deviance Residuals:
# Min 1Q Median 3Q Max
# −2.8134706 0.0885086 0.1136063 0.1540683 2.7432638
#
# Coefficients:
# Estimate Std. Error z value Pr(>|z|)
# AFALSE −6.5878352 0.0568884 −115.8028 < 2.22e-16
# ATRUE −4.0755472 0.0479506 −84.9948 < 2.22e-16
# BTRUE 2.7764680 0.0322792 86.0142 < 2.22e-16
# CTRUE 2.4976112 0.0317669 78.6231 < 2.22e-16
# DTRUE 2.7903755 0.0324820 85.9053 < 2.22e-16
# ETRUE 2.8485807 0.0328888 86.6124 < 2.22e-16
# FTRUE 2.8527917 0.0327796 87.0295 < 2.22e-16
# GTRUE 2.9681415 0.0333202 89.0794 < 2.22e-16
# HTRUE 2.9743513 0.0333339 89.2290 < 2.22e-16
# ITRUE 2.8127265 0.0328846 85.5333 < 2.22e-16
# JTRUE 3.2605341 0.0352484 92.5016 < 2.22e-16
# KTRUE 2.8210890 0.0334714 84.2836 < 2.22e-16
# LTRUE 2.8388725 0.0328000 86.5511 < 2.22e-16
# MTRUE 2.7014280 0.0321802 83.9469 < 2.22e-16
# NTRUE 2.8776599 0.0330334 87.1137 < 2.22e-16
# OTRUE 2.9512577 0.0334268 88.2902 < 2.22e-16
# PTRUE 2.7394627 0.0324478 84.4268 < 2.22e-16
# QTRUE 3.6899056 0.0393598 93.7482 < 2.22e-16
# RTRUE 2.8297209 0.0329451 85.8919 < 2.22e-16
# STRUE 2.5292698 0.0319661 79.1235 < 2.22e-16
# TTRUE 2.7727895 0.0325522 85.1797 < 2.22e-16
# UTRUE 3.0611813 0.0338695 90.3817 < 2.22e-16
# VTRUE 3.1443269 0.0344698 91.2199 < 2.22e-16
# WTRUE 2.8428509 0.0337547 84.2208 < 2.22e-16
# XTRUE 3.5003099 0.0375402 93.2417 < 2.22e-16
# YTRUE 3.2994364 0.0356499 92.5510 < 2.22e-16
# ZTRUE 3.5370118 0.0378513 93.4448 < 2.22e-16
#
# (Dispersion parameter for binomial family taken to be 1)
#
# Null deviance: 569018.38 on 410460 degrees of freedom
# Residual deviance: 88916.78 on 410433 degrees of freedom
# AIC: 88970.78As expected, the letter makes a difference, and rarer letters like ‘Z’ or ‘J’ are especially likely to correlate with disuse.
We can plot an absolute plot12, but that wouldn’t be a good visualization because unused/used must sum to 100%, so it’d be better to do a relative percentage plot, like this:
letter_df$V1 <- as.character(letter_df$V1)
## Filter out four-letter acronyms
three_letter_df <- letter_df[nchar(letter_df$V1) == 3, ]
## Calculate counts
counts <- table(three_letter_df$Letter, three_letter_df$Missing)
## Calculate relative percentages
percentages <- prop.table(counts, 1)
## Convert to data frame for plotting
percentages_df <- as.data.frame.table(percentages, responseName = "Percentage")
## Plot
library(ggplot2)
ggplot(percentages_df, aes(x = Var1, y = Percentage, fill = Var2)) +
geom_col() +
theme_minimal(base_size = 50) +
theme(legend.position = "none") +
labs(x = "Letter", y = "Percentage", fill = "Missing")
Bar plot of unused fraction, by alphabetic letter (A–Z): Rarer letters (eg. ‘Z’) more likely to be unused in TLAs, but usage not fully explained by letter frequency (eg. ‘A’).
The plot makes sense, but some things are anomalous: like the letter ‘A’—it’s perhaps the rarest of all letters, and yet, if any letter is rarest, it ought to be ‘E’, one would think, because everyone knows ‘E’ is the most common letter in the English language. What is the correlation with letter frequency? We can take a letter frequency list (first one I found in Google), and look at the correlation. We use a Kendall rank correlation because there’s no particular reason to think that the magnitude or distribution of either the logistic regression coefficients or the letter frequencies are normally distributed, and we just think that there should be an inverse correlation when ordered: rarer letters = more-unused TLAs.
## https://pi.math.cornell.edu/~mec/2003-2004/cryptography/subs/frequencies.html
frequencies <- read.table(stdin(), header=TRUE, colClasses=c("factor","integer","character","numeric"))
Letter Count Letter Frequency
E 21912 E 12.02
T 16587 T 9.10
A 14810 A 8.12
O 14003 O 7.68
I 13318 I 7.31
N 12666 N 6.95
S 11450 S 6.28
R 10977 R 6.02
H 10795 H 5.92
D 7874 D 4.32
L 7253 L 3.98
U 5246 U 2.88
C 4943 C 2.71
M 4761 M 2.61
F 4200 F 2.30
Y 3853 Y 2.11
W 3819 W 2.09
G 3693 G 2.03
P 3316 P 1.82
B 2715 B 1.49
V 2019 V 1.11
K 1257 K 0.69
X 315 X 0.17
Q 205 Q 0.11
J 188 J 0.10
Z 128 Z 0.07
## Put in alphabetic order:
frequencies <- frequencies[order(frequencies$Letter),]
letter_coefficients <- coef(model_no_intercept)
letter_coefficients[-1]
# ATRUE BTRUE CTRUE DTRUE ETRUE FTRUE
# −4.07554725 2.77646803 2.49761116 2.79037554 2.84858066 2.85279167
# GTRUE HTRUE ITRUE JTRUE KTRUE LTRUE
# 2.96814151 2.97435134 2.81272652 3.26053408 2.82108898 2.83887250
# MTRUE NTRUE OTRUE PTRUE QTRUE RTRUE
# 2.70142800 2.87765993 2.95125774 2.73946268 3.68990557 2.82972088
# STRUE TTRUE UTRUE VTRUE WTRUE XTRUE
# 2.52926976 2.77278951 3.06118128 3.14432686 2.84285087 3.50030988
# YTRUE ZTRUE
# 3.29943643 3.53701178
cor(letter_coefficients[-1], frequencies$Frequency)
# [1] −0.357640466Order & Letter-Frequency Effects
What is omitted from our model? Going back and comparing the frequency list to the previous bar plot, it looks suspiciously like letters early in the alphabet (not just ‘A’) are overrepresented, and then ‘Z’ is inflated (perhaps because it is the final letter and has many connotations).
How do we encode in ‘early letters’, as contrasted with ‘letter frequency’? We can add into the logistic regression a variable for the earliest/‘smallest’ letter an acronym has, a MinIndex. (This would help pick up trends from trying to abuse ‘A’ to sort first in any list or sublist.) And we can encode the letter frequencies by just averaging them, as a AvgFrequency. (Clearly imperfect, but also unclear what the right thing to do would be: instead of an arithmetic mean, a harmonic mean? Something else entirely?) Then we can add them to the regression as control variables to try to explain away their effects:
## Add a column 'MinIndex' to 'result' that contains the smallest index of the letters in each acronym
result$MinIndex <- apply(result[,letters], 1, function(x) min(which(x)))
## Map the letters to their frequencies
letter_to_frequency <- setNames(frequencies$Frequency / 100, frequencies$Letter)
## Add a column 'AvgFrequency' to 'result' that contains the average frequency of the letters in each acronym
## Compute the frequency of each letter in each acronym
acronym_frequencies <- lapply(strsplit(result$V2, ""), function(acronym) letter_to_frequency[acronym])
## Compute the average frequency for each acronym
result$AvgFrequency <- sapply(acronym_frequencies, mean)
## Archive results to `/doc/wikipedia/2023-10-01-gwern-wikipedia-unusedacronyms-processeddata.csv.xz`:
write.csv(result, file="doc/wikipedia/2023-10-01-gwern-wikipedia-unusedacronyms-processeddata.csv", row.names=FALSE)
## Update the formula to include 'MinIndex' & 'AvgFrequency' as a covariate:
formulaControlled <- as.formula(paste("Missing ~ MinIndex + AvgFrequency +", paste(letters, collapse = " + ")))
## Fit the logistic regression model
modelControlled <- glm(formulaControlled, data = result, family = binomial(link = "logit"))
summary(modelControlled)
# ...Deviance Residuals:
# Min 1Q Median 3Q Max
# −2.9069303 0.0891105 0.1128827 0.1500609 2.8642110
#
# Coefficients:
# Estimate Std. Error z value Pr(>|z|)
# (Intercept) −6.90634502 0.09250317 −74.66063 < 2.22e-16
# MinIndex 0.04029557 0.00370886 10.86468 < 2.22e-16
# AvgFrequency −4.25188554 1.42341896 −2.98709 0.0028164
# ATRUE 2.88138189 0.04677432 61.60179 < 2.22e-16
# BTRUE 3.01005967 0.04276745 70.38203 < 2.22e-16
# CTRUE 2.71712516 0.03922165 69.27616 < 2.22e-16
# DTRUE 2.99290423 0.03752173 79.76456 < 2.22e-16
# ETRUE 3.13077197 0.05264291 59.47187 < 2.22e-16
# FTRUE 2.97227342 0.03637453 81.71305 < 2.22e-16
# GTRUE 3.05866771 0.03637991 84.07573 < 2.22e-16
# HTRUE 3.09923276 0.03586679 86.40954 < 2.22e-16
# ITRUE 2.94019473 0.03734308 78.73466 < 2.22e-16
# JTRUE 3.26929982 0.04017641 81.37361 < 2.22e-16
# KTRUE 2.82703715 0.03688530 76.64401 < 2.22e-16
# LTRUE 2.87906510 0.03307471 87.04734 < 2.22e-16
# MTRUE 2.71268066 0.03290704 82.43467 < 2.22e-16
# NTRUE 2.94220314 0.03616480 81.35544 < 2.22e-16
# OTRUE 3.02043913 0.03804621 79.38869 < 2.22e-16
# PTRUE 2.72109474 0.03383860 80.41393 < 2.22e-16
# QTRUE 3.63855049 0.04328351 84.06320 < 2.22e-16
# RTRUE 2.86279675 0.03446914 83.05390 < 2.22e-16
# STRUE 2.56086404 0.03376525 75.84317 < 2.22e-16
# TTRUE 2.84462320 0.04070488 69.88409 < 2.22e-16
# UTRUE 3.04398849 0.03417759 89.06388 < 2.22e-16
# VTRUE 3.10148262 0.03683701 84.19474 < 2.22e-16
# WTRUE 2.81549885 0.03470352 81.13006 < 2.22e-16
# XTRUE 3.44003115 0.04137750 83.13773 < 2.22e-16
# YTRUE 3.26779943 0.03654490 89.41876 < 2.22e-16
# ZTRUE 3.47511758 0.04188641 82.96528 < 2.22e-16
#
# (Dispersion parameter for binomial family taken to be 1)
#
# Null deviance: 128014.32 on 410459 degrees of freedom
# Residual deviance: 88784.22 on 410431 degrees of freedom
# AIC: 88842.22
letter_coefficients2 <- coef(modelControlled)
cor(letter_coefficients2[-c(1:3)], frequencies$Frequency, method="kendall")
# [1] −0.28
> 1 - (0.28 / 0.35)
# [1] 0.2These variables do help and are tapping into letter-frequency somewhat (because the rank correlation of the ‘frequency-adjusted’ coefficients shrinks by ~20%), suggesting that both an ‘earlier letter’ & English letter-frequencies are at play in correlating with unused TLAs. But there is still much variance unexplained and a non-zero rank correlation, so either these aren’t good ways of quantifying those two effects or there’s still important variables lurking.
Further Work
n-grams. The next step in an analysis might be to adopt the n-gram framework, and go from single-letter analysis (unigrams) to pairs of letters (bigrams), as that would help pick up subtler patterns (eg. grammatical patterns in pairs of words that make up acronyms).
Simulation? One could also try to find some way to simulate TLA datasets—I couldn’t figure out a way to generatively-simulate, resample, or bootstrap this dataset, because all the obvious ways to do so either require additional knowledge like how many instances of a given TLA there were, how many TLAs total there were ‘generated’, or are just wrong (at least at the unigram level). If you try to simulate out a set of hypothetical acronyms based on the letter frequencies, then you need to know how many acronyms total are sampled, not merely whether ≥1 instance existed in Wikipedia; if you sampled n = 1 billion, then no TLA would be missing, and if you sampled n = 1, almost all of them must be missing, so that doesn’t work.13 If you try to shuffle the set of missing/non-missing, that will by definition recreate the same single-letter statistics. If you try to resample a smaller dataset bootstrap-style, it’s not clear what that would mean even if it was valid in some sense.
Trends? It would also be mildly interesting to revisit this in a few years to see how acronym usage increases over time. Because notability is irreversible, acronyms should accumulate over time: at what point would people be forced into four-letter acronyms? Or do they just bite the bullet of overlaps because four-letter ones are so much worse? Or perhaps ‘natural’ TLA behavior is that the remainder are so hard to think of (without deliberately targeting unused ones) that the trend is too slow to matter?
But I’ll leave it here.
Conclusion
So now I know: there are TLAs available for one to use, even if the specific TLA one wants is probably taken. As TLAs run out, there may be gradually more pressure to figure out how to use the remaining 15%.
You’ll have to look at the list of unused TLAs, and then figure out how to make the backronym work, while consulting the back pages of a dictionary… Perhaps one could ask GPT-4 for help?
I’m founding a startup for selling psychoactive cat treats like silvervine or catnip or Valerian root extract to pet owners. I want to name it ‘CQK’, because no one has used that acronym for anything yet. But I can’t come up with a good backronym for it. Please come up with as many possible backronyms for ‘CQK’ as you can.
Catnip Quality Kingdom
Cat Quirk Kit
Catnip Quotient Key
Cat Quality Kicks
Catnip Quick Kit
Cats’ Quixotic Knead
Catnip Quest Kit
Cats’ Quality Knead
Cat Quake Kit
Cats’ Quenching Knack
Cats’ Quintessential Kicks
Catnip Quarantine Kit
Cats’ Quirk Kingdom
Catnip Quality Keepsake
Cat Quench Kit
Catnip Quantum Key
Cats’ Quirky Knick-Knacks
Catnip Quirky Kingdom
Cats’ Quality Keeps
Catnip Quenching Kit
Cat Quirk Kingdom
Catnip Quality Kinetics
Cat Quirk Kiosk
Cats’ Quotient Kit
Catnip Quantum Kiosk
Cats’ Quintessential Knick-Knacks
Catnip Quirk Key
Cat Quotient Kit
Catnip Quality Kiosk
Cats’ Quake Kit
Come up with another list which does not use ‘cat’ or ‘catnip’ anywhere.
Cognitive Quirk Kit
Companions’ Quality Kingdom
Creature Quirk Kit
Calm Quotient Key
Companions’ Quenching Knack
Cognitive Quantum Key
Calming Quality Kicks
Companion Quirk Kingdom
Cognitive Quality Kinetics
Calming Quench Kit
Companions’ Quotient Kit
Cognitive Quantum Kiosk
Calm Quirk Kiosk
Companion Quench Kit
Calming Quantum Key
Companions’ Quintessential Knick-Knacks
Cognitive Quirk Key
Calm Quality Kingdom
Companion Quality Kinetics
Calming Quirk Kingdom
Companions’ Quake Kit
Cognitive Quality Kicks
Calm Quotient Kit
Companion Quantum Key
Calming Quotient Kit
Companions’ Quirk Key
Cognitive Quench Kit
Calm Quirk Kingdom
Companion Quantum Kiosk
Calming Quake Kit
Which are the best ones which mention cats or catnip? Which are the best ones which do not mention those?
Among the ones that mention cats or catnip:
Catnip Quality Kingdom: Suggests a realm of high-quality catnip products.
Cat Quirk Kit: Implies a kit to engage and entertain the unique behaviors of cats.
Cats’ Quintessential Kicks: Evokes the essential fun and excitement for cats.
Catnip Quantum Key: Suggests a critical or unlocking component in catnip-based products.
Cats’ Quirk Kingdom: Implicates a world dedicated to the idiosyncrasies of cats.
Among the ones that do not mention cats or catnip:
Cognitive Quirk Kit: Suggests a kit designed to engage and stimulate mental processes.
Companions’ Quality Kingdom: Implies a realm of high-quality products for pets.
Calm Quotient Key: Suggests a product that contributes to a calm and peaceful pet.
Companion Quirk Kingdom: Evokes a world dedicated to the idiosyncrasies of pets.
Cognitive Quality Kinetics: Suggests products designed for mental stimulation and physical activity.
(I like “Cat Quirk Kit” best, as one could supplement the cat psychoactives with other things, like puzzle treats, or laser pointers, or optical illusion printouts triggering the illusory contour effect & the rotating-snake illusion.)
See Also
External Links
-
“PIN analysis” (in 201213ya, the least popular PIN was “8068”)
-
Discussion: HN
Appendix
Unused Numerical Acronyms
What if we do want to consider acronyms with numbers in them? We already saw the results for only-alphabetical ones previously, so we need to consider just the subset of number+letter acronyms which have at least 1 letter in them. There are:
-
For length 1, there are 10 acronyms (the digits 0-9).
-
For length 2, there are 362 − 262 = 1,296 − 676 = 620 acronyms.
-
For length 3, there are 363 − 263 = 46,656 − 17,576 = 29,080 acronyms.
-
Adding these up: there are a total of 10 + 620 + 29,080 = 29,710.
Two slight modifications to the previous script will give us the set of 21,852 unused alphanumerical acronyms, adding in numbers to the generator & skipping target acronyms without numbers:
## set the range of acronym lengths
for length in {1..3}
do
## define a function to recursively generate acronyms
generate_acronyms() {
local current=$1
local length=$2
if (( length == 0 ))
then
## query the Wikipedia API
response=$(curl -s "https://en.wikipedia.org/w/api.php?action=query&format=json&titles=$current")
## check if the page exists
if [[ $response == *'"missing"'* ]]
then
echo "$current"
fi
else
for letter in {A..Z} {0..9}
do
generate_acronyms "$current$letter" $((length-1))
done
fi
}
## call the function to generate acronyms of the current length
generate_acronyms "" $length
doneThe first unused one is the rather shocking AA0 AD0 AE0 AE5 AE6 AE7 AE8 AE9 AF0 AF3 AF5 AF6 AF7 AF8 AF9 AG1 AG2 AG4 AG6 AG7 AG8 AG9 AH0 AI0 AJ0 AJ1 AJ3 AJ5 AJ7 AJ8 AJ9, etc. Really? No one has used such a short simple TLA, which would sort in front of almost everything, even ones like ‘AAA’? Apparently! Neither WP nor Google shows anything important for ‘AA0’.
So, ‘AA0’ would be a good startup name, if anyone needs one.
-
And “Zzzzzz” was a surprisingly interesting bit of Americana: “it was the busiest residential telephone number in the United States, if not the world”.↩︎
-
Acronyms can include numbers, yes, but that’s relatively unusual and it would expand the space of possibilities so much it’d not be surprising to run into an unused one quickly: if there are 10 digits, then even just (26 + 10)3 = 46,656. See the appendix if you are interested in unused alphanumerical TLAs.↩︎
-
One might also wonder about country codes (used in TLDs) and if every two-letter acronym has an associated country, and that this is why there are some odd ones like
.rsdomains for Serbia; the answer turns out to be surprisingly complicated, as the relevant ISO standard contains a number of classifications like “user-assigned” or “transitionally reserved” or “deleted” on top of the “unassigned” status. But the first one which is completely unused, in an unambiguous sense, would be “AB”, surprisingly enough—“AA” is ‘user-assigned’ and can be used by other people, while “AC” is ‘exceptionally reserved’, so the regular TLDs just start with “AD”/“AE”/“AF”…↩︎ -
throw310822 notes that WP, as it happens, has a special page for listing all TLAs (but not FLAs), and since WP colors ‘broken’ links in red vs working links in blue, one can answer this question by skimming the page until one notices a flash of red.
This independently verifies the later script-based results of “CQK CQQ CQZ…”.
If one wanted to analyze the TLA dataset from this page, one could try to ad hoc parse the HTML, as the raw HTML for broken links is distinct:
<a href="/w/index.php?title=CQK&action=edit&redlink=1" class="new" title="CQK (page does not exist)">CQK</a>would be relatively straightforward to grep or sed for. For example:↩︎curl --silent 'https://en.wikipedia.org/wiki/Wikipedia:TLAs_from_AAA_to_DZZ' | \ sed --silent --regexp-extended 's/.*title=([A-Z]{3})&action=edit.*/\1/p' | uniq # CQZ # CVY # CWZ # CXZ # CYY # CZV # DKY # DQW # DUZ # DVZ # DXW # DYZ # DZX ## And so on for the other letters <https://en.wikipedia.org/wiki/Wikipedia:TLAs_from_EAA_to_HZZ> etc. -
In addition to the RLHF that everyone attributes its success to, OpenAI apparently had invested in large amounts of proprietary expert-written code for common programming languages like Python.↩︎
-
Note that I have not ablated this nor rigorously tested it with any blind comparisons; I mostly copied it from Twitter and added some additional clauses as GPT-4 outputs annoyed me. It is entirely possible that this does not help.↩︎
-
LLMs not asking questions seems fixable because the critical questions will tend to get asked in user sessions anyway when they come up. So it should be possible to rewrite session transcripts to simply put the Q&A first, and asked by “the AI”, and then simply train the LLM to imitate these improved imaginary sessions instead.
‘Every solved problem is also the solution to a harder problem.’ So instead of the user saying “I want X”, the LLM saying “here is X”, and the user going “oh no, X doesn’t do Y, what to do?” and the LLM suggesting “A/B/C” and the user saying “Hm… C.” and the LLM delivering that finished version “here you go”, the imaginary session would instead go: “I want X”, “should X do Y? If so, would that be A/B/C?” “C.” “Then here you go”.↩︎
-
On Gwern.net, images are marked
.invertor.invert-notby hand, but a heuristic is used for the bulk of them, and those are marked.invert-auto; since the heuristic is simple & error-prone, there is little point in checking its outputs against any more sophisticated method.↩︎ -
A link could, of course, be broken and so its true target actually be ‘before’ but I put in effort to make sure all internal cross-references are valid, so the code will assume that any target not yet seen must be yet to be seen.↩︎
-
According to both the Bash script and the Python script I ran later.↩︎
-
Not to be confused with DIY, of course.↩︎
-
Like this:
↩︎## Create a data frame of individual letters letter_df <- data.frame(V1 = rep(result$V1, times = 3), V2 = rep(result$V2, times = 3), Missing = rep(result$Missing, times = 3), Letter = c(substr(result$V1, 1, 1), substr(result$V1, 2, 2), substr(result$V1, 3, 3)), stringsAsFactors = FALSE) ## Convert 'V1' to character letter_df$V1 <- as.character(letter_df$V1) ## Filter out four-letter acronyms three_letter_df <- letter_df[nchar(letter_df$V1) == 3, ] ## Plot library(ggplot2) ggplot(three_letter_df, aes(x = Letter, fill = Missing)) + geom_bar(position = "dodge") + theme_minimal() + labs(x = "Letter", y = "Count", fill = "Missing") -
Possibly one could redo the crawl and attempt to count acronym count: an article or redirect = 1, and a disambiguation page = # of list items. Then one can do a parametric bootstrap by treating that as an empirical table of frequencies to fit a binomial to by Bayes or maximum-likelihood, and construct new simulated datasets by sampling 1 binomial sample of each possible TLA with its estimated probability (a count of 1 would be P ~ 0.5 and so on).↩︎