‘RL scaling’ tag
- See Also
- Gwern
-
Links
- “Introducing ChatGPT Pro: Broadening Usage of Frontier AI”, OpenAI 2024
- “Data Scaling Laws in Imitation Learning for Robotic Manipulation”, Lin et al 2024
- “AI Alignment via Slow Substrates: Early Empirical Results With StarCraft II”, Leong 2024
- “MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”, Chan et al 2024
- “NAVIX: Scaling MiniGrid Environments With JAX”, Pignatelli et al 2024
- “JEST: Data Curation via Joint Example Selection Further Accelerates Multimodal Learning”, Evans et al 2024
- “AI Search: The Bitter-Er Lesson”, McLaughlin 2024
- “Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
- “Simple and Scalable Strategies to Continually Pre-Train Large Language Models”, Ibrahim et al 2024
- “Robust Agents Learn Causal World Models”, Richens & Everitt 2024
- “Grandmaster-Level Chess Without Search”, Ruoss et al 2024
- “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
- “Vision-Language Models As a Source of Rewards”, Baumli et al 2023
- “JaxMARL: Multi-Agent RL Environments in JAX”, Rutherford et al 2023
- “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, Zahavy et al 2023
- “Deep RL at Scale: Sorting Waste in Office Buildings With a Fleet of Mobile Manipulators”, Herzog et al 2023
- “Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
- “Scaling Laws for Single-Agent Reinforcement Learning”, Hilton et al 2023
- “DreamerV3: Mastering Diverse Domains through World Models”, Hafner et al 2023
- “Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes”, Kumar et al 2022
- “VeLO: Training Versatile Learned Optimizers by Scaling Up”, Metz et al 2022
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “Scaling Laws for Reward Model Overoptimization”, Gao et al 2022
- “SAP: Bidirectional Language Models Are Also Few-Shot Learners”, Patel et al 2022
-
“
g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022 - “Human-Level Atari 200× Faster”, Kapturowski et al 2022
- “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”, Ganguli et al 2022
- “AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”, Soltan et al 2022
- “TextWorldExpress: Simulating Text Games at One Million Steps Per Second”, Jansen & Côté 2022
- “Demis Hassabis: DeepMind—AI, Superintelligence & the Future of Humanity § Turing Test”, Hassabis & Fridman 2022
- “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, Baker et al 2022
- “Multi-Game Decision Transformers”, Lee et al 2022
- “Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)”, Caccia et al 2022
- “CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
- “Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
- “Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
- “Gato: A Generalist Agent”, Reed et al 2022
- “Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
- “Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale”, Ramrakhya et al 2022
- “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
- “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
- “InstructGPT: Training Language Models to Follow Instructions With Human Feedback”, Ouyang et al 2022
- “A Data-Driven Approach for Learning to Control Computers”, Humphreys et al 2022
- “EvoJAX: Hardware-Accelerated Neuroevolution”, Tang et al 2022
- “Accelerated Quality-Diversity for Robotics through Massive Parallelism”, Lim et al 2022
- “Don’t Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning (ExORL)”, Yarats et al 2022
- “Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
- “In Defense of the Unitary Scalarization for Deep Multi-Task Learning”, Kurin et al 2022
- “The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”, Pan et al 2022
- “WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
- “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
- “Acquisition of Chess Knowledge in AlphaZero”, McGrath et al 2021
- “AW-Opt: Learning Robotic Skills With Imitation and Reinforcement at Scale”, Lu et al 2021
- “An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
- “Procedural Generalization by Planning With Self-Supervised World Models”, Anand et al 2021
- “MetaICL: Learning to Learn In Context”, Min et al 2021
- “Collaborating With Humans without Human Data”, Strouse et al 2021
- “T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
- “Bridge Data: Boosting Generalization of Robotic Skills With Cross-Domain Datasets”, Ebert et al 2021
- “Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning”, Rudin et al 2021
- “Recursively Summarizing Books With Human Feedback”, Wu et al 2021
- “FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
- “Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation”, Nair et al 2021
- “WarpDrive: Extremely Fast End-To-End Deep Multi-Agent Reinforcement Learning on a GPU”, Lan et al 2021
- “Multi-Task Self-Training for Learning General Representations”, Ghiasi et al 2021
- “Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning”, Makoviychuk et al 2021
- “Open-Ended Learning Leads to Generally Capable Agents”, Team et al 2021
- “Megaverse: Simulating Embodied Agents at One Million Experiences per Second”, Petrenko et al 2021
- “Evaluating Large Language Models Trained on Code”, Chen et al 2021
- “PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies”, Vicol et al 2021
- “Multimodal Few-Shot Learning With Frozen Language Models”, Tsimpoukelli et al 2021
- “Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, Freeman et al 2021
- “PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World”, Zellers et al 2021
- “From Motor Control to Team Play in Simulated Humanoid Football”, Liu et al 2021
- “Reward Is Enough”, Silver et al 2021
- “Podracer Architectures for Scalable Reinforcement Learning”, Hessel et al 2021
- “MuZero Unplugged: Online and Offline Reinforcement Learning by Planning With a Learned Model”, Schrittwieser et al 2021
- “Scaling Scaling Laws With Board Games”, Jones 2021
- “Large Batch Simulation for Deep Reinforcement Learning”, Shacklett et al 2021
- “Stockfish and Lc0, Test at Different Number of Nodes”, Meloni 2021
- “Training Larger Networks for Deep Reinforcement Learning”, Ota et al 2021
- “Investment vs. Reward in a Competitive Knapsack Problem”, Neumann & Gros 2021
- “NNUE: The Neural Network of the Stockfish Chess Engine”, Goucher 2021
- “Imitating Interactive Intelligence”, Abramson et al 2020
- “Scaling down Deep Learning”, Greydanus 2020
- “Understanding RL Vision: With Diverse Environments, We Can Analyze, Diagnose and Edit Deep Reinforcement Learning Models Using Attribution”, Hilton et al 2020
- “Meta-Trained Agents Implement Bayes-Optimal Agents”, Mikulik et al 2020
- “Measuring Progress in Deep Reinforcement Learning Sample Efficiency”, Anonymous 2020
- “Learning to Summarize from Human Feedback”, Stiennon et al 2020
- “Measuring Hardware Overhang”, hippke 2020
- “Sample Factory: Egocentric 3D Control from Pixels at 100,000 FPS With Asynchronous Reinforcement Learning”, Petrenko et al 2020
- “Real World Games Look Like Spinning Tops”, Czarnecki et al 2020
- “Agent57: Outperforming the Human Atari Benchmark”, Puigdomènech et al 2020
- “Deep Neuroethology of a Virtual Rodent”, Merel et al 2020
- “Near-Perfect Point-Goal Navigation from 2.5 Billion Frames of Experience”, Wijmans & Kadian 2020
- “Procgen Benchmark: We’re Releasing Procgen Benchmark, 16 Simple-To-Use Procedurally-Generated Environments Which Provide a Direct Measure of How Quickly a Reinforcement Learning Agent Learns Generalizable Skills”, Cobbe et al 2019
- “DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames”, Wijmans et al 2019
- “Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning”, Vinyals et al 2019
- “Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
- “Fine-Tuning Language Models from Human Preferences”, Ziegler et al 2019
- “Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior”, Baker et al 2019
- “Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior”, Baker et al 2019
- “Meta Reinforcement Learning”, Weng 2019
- “Human-Level Performance in 3D Multiplayer Games With Population-Based Reinforcement Learning”, Jaderberg et al 2019
- “AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
- “Meta-Learning of Sequential Strategies”, Ortega et al 2019
- “Habitat: A Platform for Embodied AI Research”, Savva et al 2019
- “The Bitter Lesson”, Sutton 2019
- “Benchmarking Classic and Learned Navigation in Complex 3D Environments”, Mishkin et al 2019
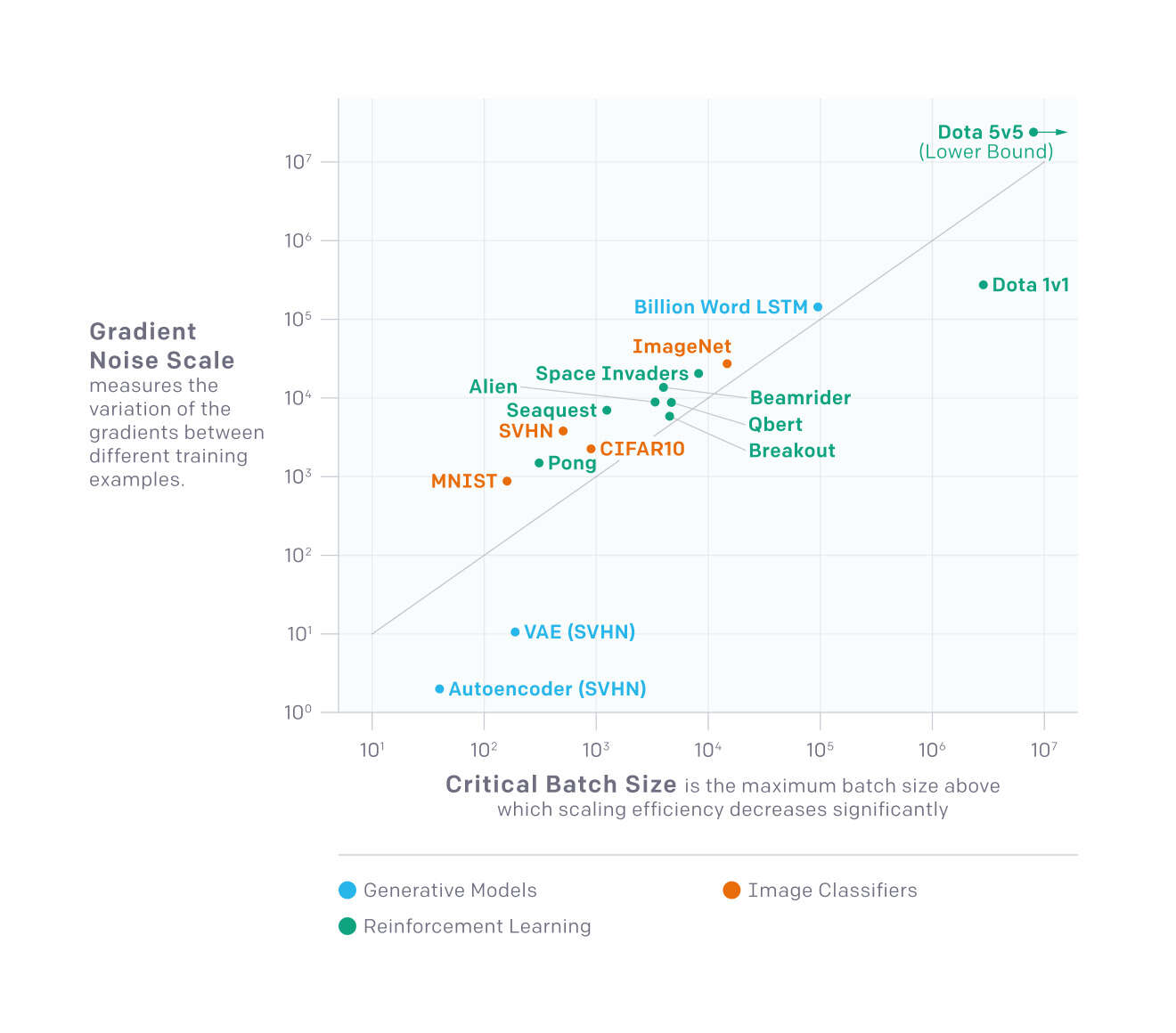
- “Dota 2 With Large Scale Deep Reinforcement Learning: §4.3: Batch Size”, Berner 2019 (page 13)
- “An Empirical Model of Large-Batch Training”, McCandlish et al 2018
- “How AI Training Scales”, McCandlish et al 2018
- “Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
- “Quantifying Generalization in Reinforcement Learning”, Cobbe et al 2018
- “One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets With RL”, Paine et al 2018
- “Robot Learning in Homes: Improving Generalization and Reducing Dataset Bias”, Gupta et al 2018
- “Human-Level Performance in First-Person Multiplayer Games With Population-Based Deep Reinforcement Learning”, Jaderberg et al 2018
- “QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation”, Kalashnikov et al 2018
- “Playing Atari With Six Neurons”, Cuccu et al 2018
- “AI and Compute”, Amodei et al 2018
- “Accelerated Methods for Deep Reinforcement Learning”, Stooke & Abbeel 2018
- “One Big Net For Everything”, Schmidhuber 2018
- “Interactive Grounded Language Acquisition and Generalization in a 2D World”, Yu et al 2018
- “Emergence of Locomotion Behaviors in Rich Environments”, Heess et al 2017
- “Deep Reinforcement Learning from Human Preferences”, Christiano et al 2017
- “Evolution Strategies As a Scalable Alternative to Reinforcement Learning”, Salimans et al 2017
- “On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
- “Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning”, Parisotto et al 2015
- “Gorila: Massively Parallel Methods for Deep Reinforcement Learning”, Nair et al 2015
- “Algorithmic Progress in Six Domains”, Grace 2013
- “Robot Predictions Evolution”, Moravec 2004
- “When Will Computer Hardware Match the Human Brain?”, Moravec 1998
- “Human Window on the World”, Michie 1985
- “Time for AI to Cross the Human Performance Range in Chess”
- “Eric Jang”
- “Trading Off Compute in Training and Inference”
- “Trading Off Compute in Training and Inference § MCTS Scaling”
-
“Submission #6347: Chef Stef’s NES Arkanoid
warplessin 11:11.18” - “[The Addictiveness & Adversarialness of Playing against LeelaQueenOdds]”, Järviniemi 2025
- “Training a CUDA TDS Ant Using C++ ARS Linear Policy: The Video Is Real-Time, After a Few Minutes (in the 30 Million Steps) the Training Curve Is Flat (I Trained Until a Billion Steps). Note That This Ant Is PD Control, and Not Identical to Either MuJoCo or PyBullet Ant, so the Training Curves Are Not Comparable Yet. Will Fix That.”
- “Ilya Sutskever: Deep Learning | AI Podcast #94 With Lex Fridman”
- “Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Video]”
- “If You Want to Solve a Hard Problem in Reinforcement Learning, You Just Scale. It's Just Gonna Work Just like Supervised Learning. It's the Same, the Same Story Exactly. It Was Kind of Hard to Believe That Supervised Learning Can Do All Those Things, but It's Not Just Vision, It's Everything and the Same Thing Seems to Hold for Reinforcement Learning Provided You Have a Lot of Experience.”
- Wikipedia
- Miscellaneous
- Bibliography
See Also
Gwern
“Research Ideas”, Gwern 2017
“It Looks Like You’re Trying To Take Over The World”, Gwern 2022
“The Scaling Hypothesis”, Gwern 2020
“Why Tool AIs Want to Be Agent AIs”, Gwern 2016
Links
“Introducing ChatGPT Pro: Broadening Usage of Frontier AI”, OpenAI 2024
“Data Scaling Laws in Imitation Learning for Robotic Manipulation”, Lin et al 2024
Data Scaling Laws in Imitation Learning for Robotic Manipulation
“AI Alignment via Slow Substrates: Early Empirical Results With StarCraft II”, Leong 2024
AI Alignment via Slow Substrates: Early Empirical Results With StarCraft II:
“MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”, Chan et al 2024
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
“NAVIX: Scaling MiniGrid Environments With JAX”, Pignatelli et al 2024
“JEST: Data Curation via Joint Example Selection Further Accelerates Multimodal Learning”, Evans et al 2024
JEST: Data curation via joint example selection further accelerates multimodal learning
“AI Search: The Bitter-Er Lesson”, McLaughlin 2024
“Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
“Simple and Scalable Strategies to Continually Pre-Train Large Language Models”, Ibrahim et al 2024
Simple and Scalable Strategies to Continually Pre-train Large Language Models
“Robust Agents Learn Causal World Models”, Richens & Everitt 2024
“Grandmaster-Level Chess Without Search”, Ruoss et al 2024
“Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
“Vision-Language Models As a Source of Rewards”, Baumli et al 2023
“JaxMARL: Multi-Agent RL Environments in JAX”, Rutherford et al 2023
“Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, Zahavy et al 2023
Diversifying AI: Towards Creative Chess with AlphaZero (AZdb)
“Deep RL at Scale: Sorting Waste in Office Buildings With a Fleet of Mobile Manipulators”, Herzog et al 2023
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
“Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
Emergence of belief-like representations through reinforcement learning
“Scaling Laws for Single-Agent Reinforcement Learning”, Hilton et al 2023
“DreamerV3: Mastering Diverse Domains through World Models”, Hafner et al 2023
“Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes”, Kumar et al 2022
Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes
“VeLO: Training Versatile Learned Optimizers by Scaling Up”, Metz et al 2022
“Broken Neural Scaling Laws”, Caballero et al 2022
“Scaling Laws for Reward Model Overoptimization”, Gao et al 2022
“SAP: Bidirectional Language Models Are Also Few-Shot Learners”, Patel et al 2022
SAP: Bidirectional Language Models Are Also Few-shot Learners
“g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022
g.pt: Learning to Learn with Generative Models of Neural Network Checkpoints
“Human-Level Atari 200× Faster”, Kapturowski et al 2022
“Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”, Ganguli et al 2022
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
“AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”, Soltan et al 2022
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
“TextWorldExpress: Simulating Text Games at One Million Steps Per Second”, Jansen & Côté 2022
TextWorldExpress: Simulating Text Games at One Million Steps Per Second
“Demis Hassabis: DeepMind—AI, Superintelligence & the Future of Humanity § Turing Test”, Hassabis & Fridman 2022
Demis Hassabis: DeepMind—AI, Superintelligence & the Future of Humanity § Turing Test
“Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, Baker et al 2022
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
“Multi-Game Decision Transformers”, Lee et al 2022
“Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)”, Caccia et al 2022
Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)
“CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
“Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
“Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
Instruction Induction: From Few Examples to Natural Language Task Descriptions
“Gato: A Generalist Agent”, Reed et al 2022
“Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers
“Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale”, Ramrakhya et al 2022
Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale
“Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances
“Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
“InstructGPT: Training Language Models to Follow Instructions With Human Feedback”, Ouyang et al 2022
InstructGPT: Training language models to follow instructions with human feedback
“A Data-Driven Approach for Learning to Control Computers”, Humphreys et al 2022
“EvoJAX: Hardware-Accelerated Neuroevolution”, Tang et al 2022
“Accelerated Quality-Diversity for Robotics through Massive Parallelism”, Lim et al 2022
Accelerated Quality-Diversity for Robotics through Massive Parallelism
“Don’t Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning (ExORL)”, Yarats et al 2022
“Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
“In Defense of the Unitary Scalarization for Deep Multi-Task Learning”, Kurin et al 2022
In Defense of the Unitary Scalarization for Deep Multi-Task Learning
“The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”, Pan et al 2022
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
“WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
WebGPT: Browser-assisted question-answering with human feedback
“WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
WebGPT: Improving the factual accuracy of language models through web browsing
“Acquisition of Chess Knowledge in AlphaZero”, McGrath et al 2021
“AW-Opt: Learning Robotic Skills With Imitation and Reinforcement at Scale”, Lu et al 2021
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
“An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
An Explanation of In-context Learning as Implicit Bayesian Inference
“Procedural Generalization by Planning With Self-Supervised World Models”, Anand et al 2021
Procedural Generalization by Planning with Self-Supervised World Models
“MetaICL: Learning to Learn In Context”, Min et al 2021
“Collaborating With Humans without Human Data”, Strouse et al 2021
“T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
T0: Multitask Prompted Training Enables Zero-Shot Task Generalization
“Bridge Data: Boosting Generalization of Robotic Skills With Cross-Domain Datasets”, Ebert et al 2021
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
“Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning”, Rudin et al 2021
Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
“Recursively Summarizing Books With Human Feedback”, Wu et al 2021
“FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
“Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation”, Nair et al 2021
Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation
“WarpDrive: Extremely Fast End-To-End Deep Multi-Agent Reinforcement Learning on a GPU”, Lan et al 2021
WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
“Multi-Task Self-Training for Learning General Representations”, Ghiasi et al 2021
Multi-Task Self-Training for Learning General Representations
“Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning”, Makoviychuk et al 2021
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
“Open-Ended Learning Leads to Generally Capable Agents”, Team et al 2021
“Megaverse: Simulating Embodied Agents at One Million Experiences per Second”, Petrenko et al 2021
Megaverse: Simulating Embodied Agents at One Million Experiences per Second
“Evaluating Large Language Models Trained on Code”, Chen et al 2021
“PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies”, Vicol et al 2021
“Multimodal Few-Shot Learning With Frozen Language Models”, Tsimpoukelli et al 2021
“Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, Freeman et al 2021
Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation
“PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World”, Zellers et al 2021
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
“From Motor Control to Team Play in Simulated Humanoid Football”, Liu et al 2021
From Motor Control to Team Play in Simulated Humanoid Football
“Reward Is Enough”, Silver et al 2021
“Podracer Architectures for Scalable Reinforcement Learning”, Hessel et al 2021
“MuZero Unplugged: Online and Offline Reinforcement Learning by Planning With a Learned Model”, Schrittwieser et al 2021
MuZero Unplugged: Online and Offline Reinforcement Learning by Planning with a Learned Model
“Scaling Scaling Laws With Board Games”, Jones 2021
“Large Batch Simulation for Deep Reinforcement Learning”, Shacklett et al 2021
“Stockfish and Lc0, Test at Different Number of Nodes”, Meloni 2021
“Training Larger Networks for Deep Reinforcement Learning”, Ota et al 2021
“Investment vs. Reward in a Competitive Knapsack Problem”, Neumann & Gros 2021
“NNUE: The Neural Network of the Stockfish Chess Engine”, Goucher 2021
“Imitating Interactive Intelligence”, Abramson et al 2020
“Scaling down Deep Learning”, Greydanus 2020
“Understanding RL Vision: With Diverse Environments, We Can Analyze, Diagnose and Edit Deep Reinforcement Learning Models Using Attribution”, Hilton et al 2020
“Meta-Trained Agents Implement Bayes-Optimal Agents”, Mikulik et al 2020
“Measuring Progress in Deep Reinforcement Learning Sample Efficiency”, Anonymous 2020
Measuring Progress in Deep Reinforcement Learning Sample Efficiency
“Learning to Summarize from Human Feedback”, Stiennon et al 2020
“Measuring Hardware Overhang”, hippke 2020
“Sample Factory: Egocentric 3D Control from Pixels at 100,000 FPS With Asynchronous Reinforcement Learning”, Petrenko et al 2020
“Real World Games Look Like Spinning Tops”, Czarnecki et al 2020
“Agent57: Outperforming the Human Atari Benchmark”, Puigdomènech et al 2020
“Deep Neuroethology of a Virtual Rodent”, Merel et al 2020
“Near-Perfect Point-Goal Navigation from 2.5 Billion Frames of Experience”, Wijmans & Kadian 2020
Near-perfect point-goal navigation from 2.5 billion frames of experience
“Procgen Benchmark: We’re Releasing Procgen Benchmark, 16 Simple-To-Use Procedurally-Generated Environments Which Provide a Direct Measure of How Quickly a Reinforcement Learning Agent Learns Generalizable Skills”, Cobbe et al 2019
“DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames”, Wijmans et al 2019
DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames
“Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning”, Vinyals et al 2019
Grandmaster level in StarCraft II using multi-agent reinforcement learning
“Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
“Fine-Tuning Language Models from Human Preferences”, Ziegler et al 2019
“Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior”, Baker et al 2019
Emergent Tool Use from Multi-Agent Interaction § Surprising behavior
“Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior”, Baker et al 2019
Emergent Tool Use from Multi-Agent Interaction § Surprising behavior
“Meta Reinforcement Learning”, Weng 2019
“Human-Level Performance in 3D Multiplayer Games With Population-Based Reinforcement Learning”, Jaderberg et al 2019
Human-level performance in 3D multiplayer games with population-based reinforcement learning
“AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
“Meta-Learning of Sequential Strategies”, Ortega et al 2019
“Habitat: A Platform for Embodied AI Research”, Savva et al 2019
“The Bitter Lesson”, Sutton 2019
“Benchmarking Classic and Learned Navigation in Complex 3D Environments”, Mishkin et al 2019
Benchmarking Classic and Learned Navigation in Complex 3D Environments
“Dota 2 With Large Scale Deep Reinforcement Learning: §4.3: Batch Size”, Berner 2019 (page 13)
Dota 2 with Large Scale Deep Reinforcement Learning: §4.3: Batch Size:
“An Empirical Model of Large-Batch Training”, McCandlish et al 2018
“How AI Training Scales”, McCandlish et al 2018
“Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
“Quantifying Generalization in Reinforcement Learning”, Cobbe et al 2018
“One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets With RL”, Paine et al 2018
One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets with RL
“Robot Learning in Homes: Improving Generalization and Reducing Dataset Bias”, Gupta et al 2018
Robot Learning in Homes: Improving Generalization and Reducing Dataset Bias
“Human-Level Performance in First-Person Multiplayer Games With Population-Based Deep Reinforcement Learning”, Jaderberg et al 2018
“QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation”, Kalashnikov et al 2018
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
“Playing Atari With Six Neurons”, Cuccu et al 2018
“AI and Compute”, Amodei et al 2018
“Accelerated Methods for Deep Reinforcement Learning”, Stooke & Abbeel 2018
“One Big Net For Everything”, Schmidhuber 2018
“Interactive Grounded Language Acquisition and Generalization in a 2D World”, Yu et al 2018
Interactive Grounded Language Acquisition and Generalization in a 2D World
“Emergence of Locomotion Behaviors in Rich Environments”, Heess et al 2017
“Deep Reinforcement Learning from Human Preferences”, Christiano et al 2017
“Evolution Strategies As a Scalable Alternative to Reinforcement Learning”, Salimans et al 2017
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
“On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
“Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning”, Parisotto et al 2015
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
“Gorila: Massively Parallel Methods for Deep Reinforcement Learning”, Nair et al 2015
Gorila: Massively Parallel Methods for Deep Reinforcement Learning
“Algorithmic Progress in Six Domains”, Grace 2013
“Robot Predictions Evolution”, Moravec 2004
“When Will Computer Hardware Match the Human Brain?”, Moravec 1998
“Human Window on the World”, Michie 1985
“Time for AI to Cross the Human Performance Range in Chess”
“Eric Jang”
“Trading Off Compute in Training and Inference”
“Trading Off Compute in Training and Inference § MCTS Scaling”
Trading Off Compute in Training and Inference § MCTS scaling
“Submission #6347: Chef Stef’s NES Arkanoid warpless in 11:11.18”
Submission #6347: Chef Stef’s NES Arkanoid warpless in 11:11.18
“[The Addictiveness & Adversarialness of Playing against LeelaQueenOdds]”, Järviniemi 2025
[The addictiveness & adversarialness of playing against LeelaQueenOdds]:
“Training a CUDA TDS Ant Using C++ ARS Linear Policy: The Video Is Real-Time, After a Few Minutes (in the 30 Million Steps) the Training Curve Is Flat (I Trained Until a Billion Steps). Note That This Ant Is PD Control, and Not Identical to Either MuJoCo or PyBullet Ant, so the Training Curves Are Not Comparable Yet. Will Fix That.”
“Ilya Sutskever: Deep Learning | AI Podcast #94 With Lex Fridman”
Ilya Sutskever: Deep Learning | AI Podcast #94 with Lex Fridman
“Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Video]”
Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning [video]
“If You Want to Solve a Hard Problem in Reinforcement Learning, You Just Scale. It's Just Gonna Work Just like Supervised Learning. It's the Same, the Same Story Exactly. It Was Kind of Hard to Believe That Supervised Learning Can Do All Those Things, but It's Not Just Vision, It's Everything and the Same Thing Seems to Hold for Reinforcement Learning Provided You Have a Lot of Experience.”
Wikipedia
Miscellaneous
-
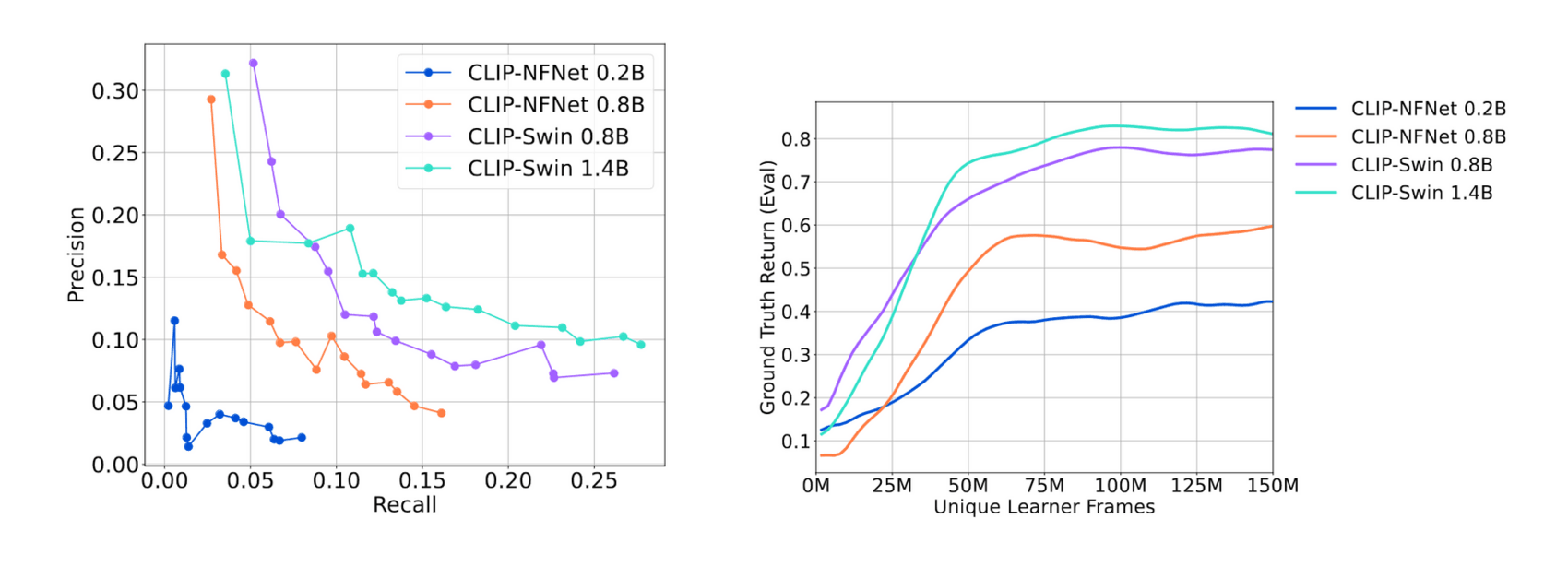
/doc/reinforcement-learning/scaling/2023-baumli-figure4-rewardscalinginclipmodelsize.png: -
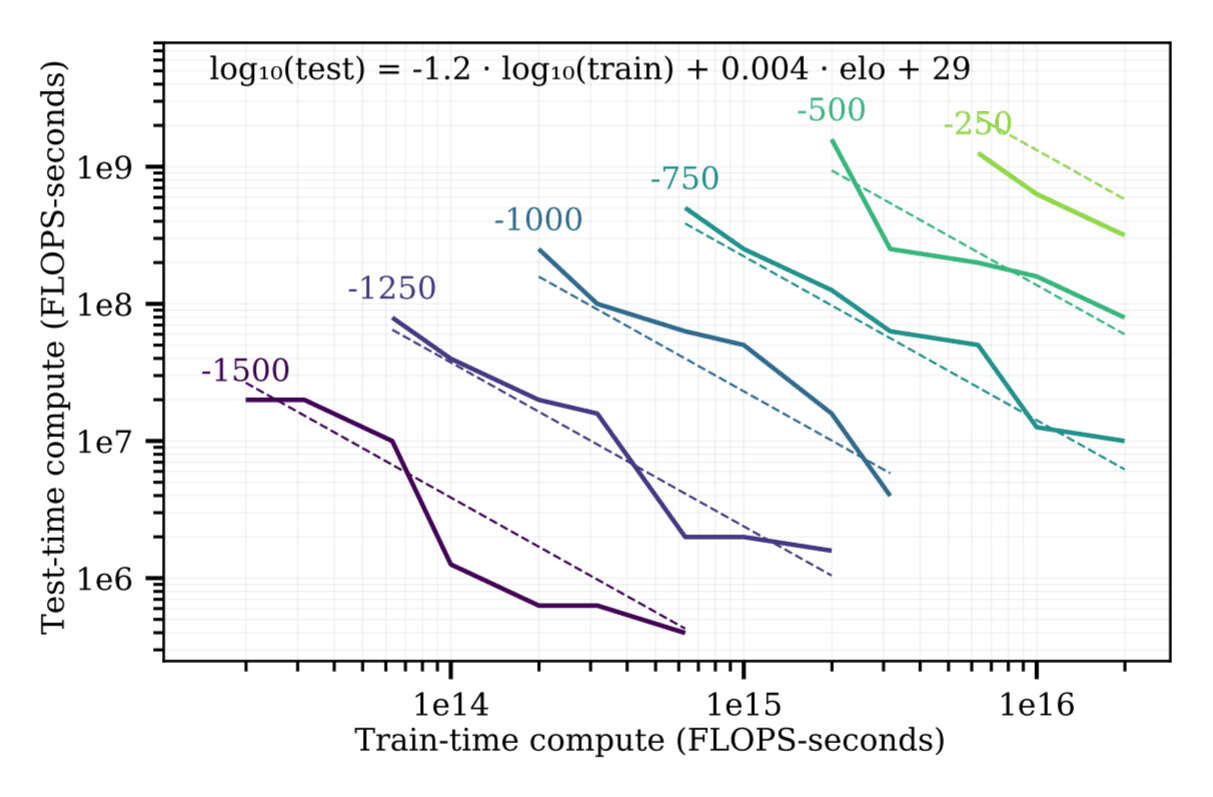
/doc/reinforcement-learning/scaling/2021-jones-figure9-trainvstreesearchamortization.jpg: -
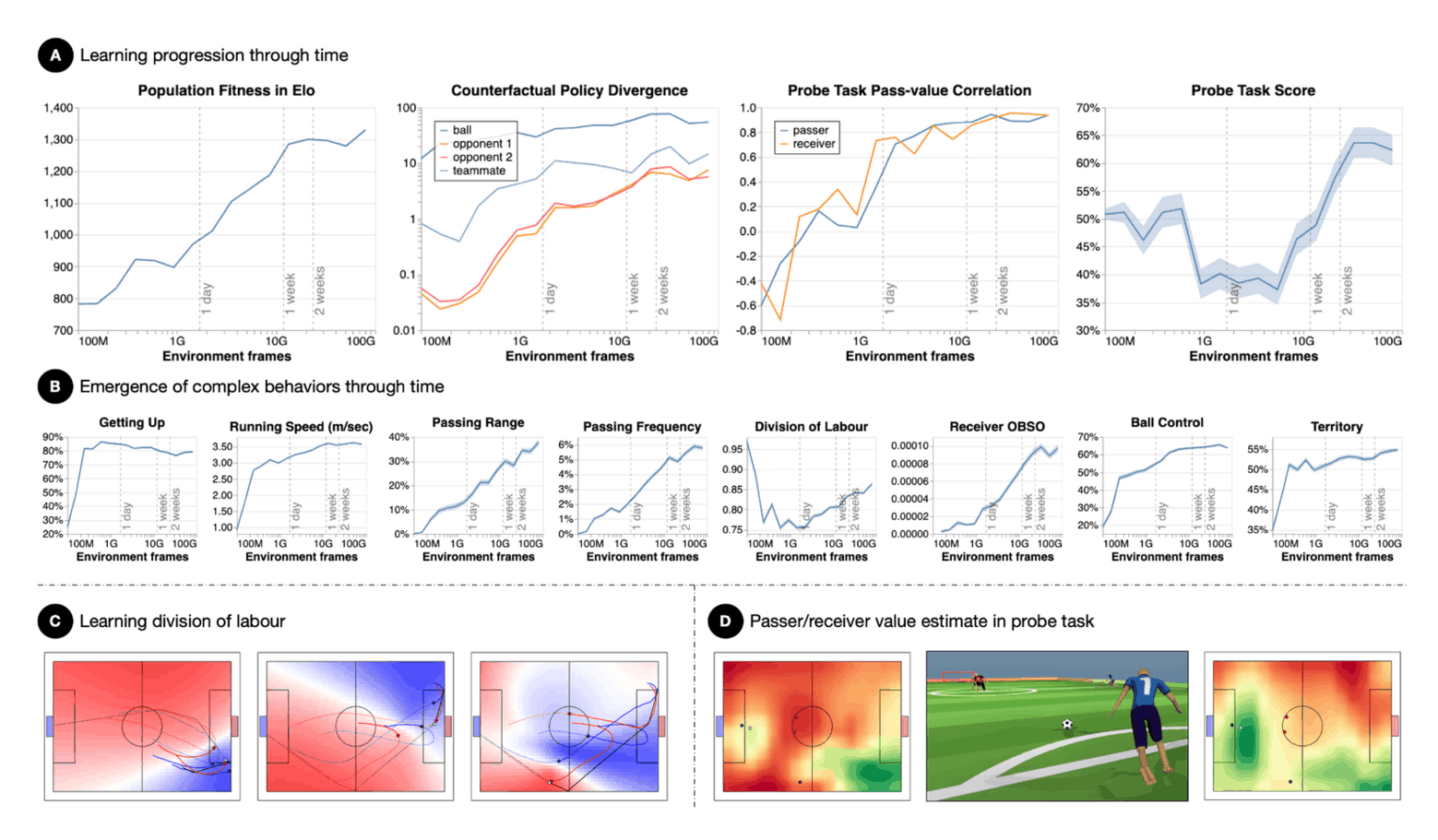
/doc/reinforcement-learning/scaling/2021-liu-figure5-soccerperformancescaling.png: -
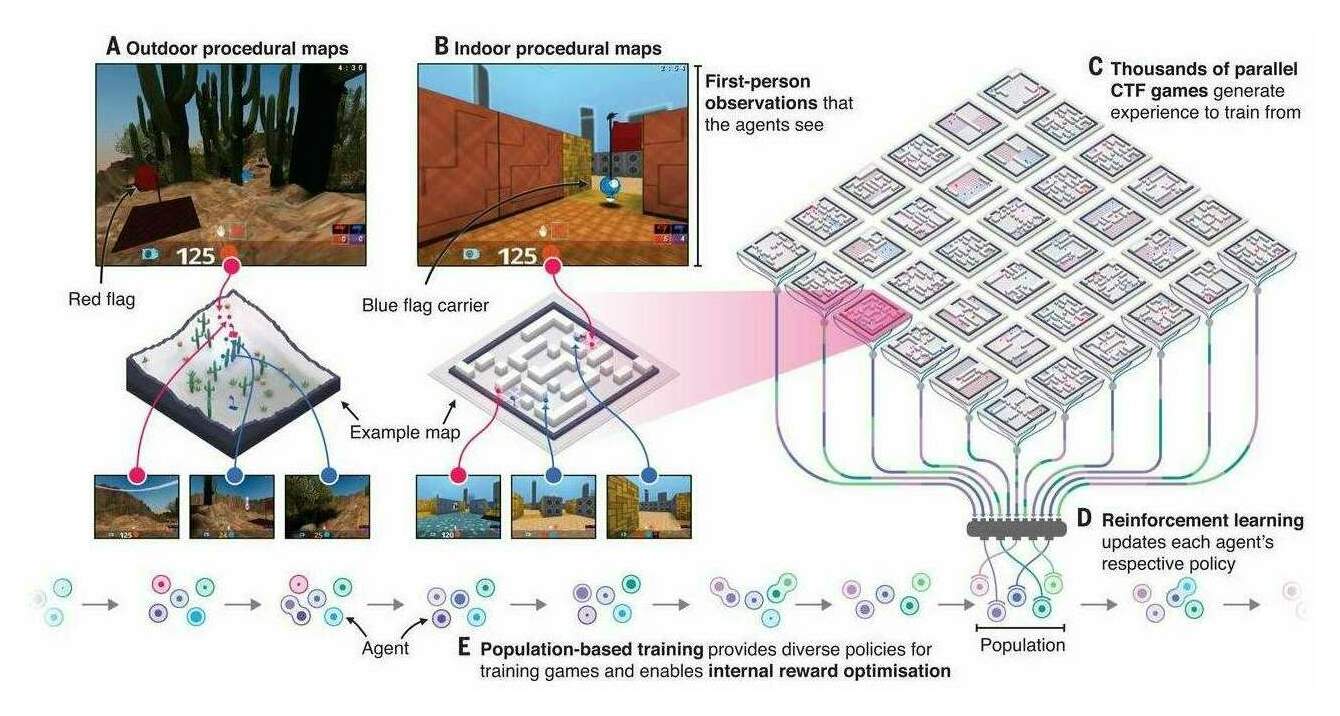
/doc/reinforcement-learning/exploration/2019-jaderberg-figure1-ctftaskandtraining.jpg: -
https://andyljones.com/megastep/:View External Link:
-
https://jdlm.info/articles/2018/03/18/markov-decision-process-2048.html: -
https://research.google/blog/google-research-2022-beyond-language-vision-and-generative-models/ -
https://www.anthropic.com/index/anthropics-responsible-scaling-policy -
https://www.lesswrong.com/posts/65qmEJHDw3vw69tKm/proposal-scaling-laws-for-rl-generalization:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
-
https://arxiv.org/abs/2410.07095#openai: “MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”, -
https://yellow-apartment-148.notion.site/AI-Search-The-Bitter-er-Lesson-44c11acd27294f4495c3de778cd09c8d: “AI Search: The Bitter-Er Lesson”, -
https://arxiv.org/abs/2402.04494#deepmind: “Grandmaster-Level Chess Without Search”, -
https://arxiv.org/abs/2401.05566#anthropic: “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, -
https://arxiv.org/abs/2311.10090: “JaxMARL: Multi-Agent RL Environments in JAX”, -
https://arxiv.org/abs/2308.09175#deepmind: “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, -
https://arxiv.org/abs/2301.04104#deepmind: “DreamerV3: Mastering Diverse Domains through World Models”, -
https://arxiv.org/abs/2210.10760#openai: “Scaling Laws for Reward Model Overoptimization”, -
https://arxiv.org/abs/2209.14500: “SAP: Bidirectional Language Models Are Also Few-Shot Learners”, -
https://arxiv.org/abs/2209.12892: “g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, -
https://arxiv.org/abs/2209.07550#deepmind: “Human-Level Atari 200× Faster”, -
https://www.anthropic.com/red_teaming.pdf: “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”, -
https://arxiv.org/abs/2208.01448#amazon: “AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”, -
https://arxiv.org/abs/2206.11795#openai: “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, -
https://arxiv.org/abs/2205.15241#google: “Multi-Game Decision Transformers”, -
https://arxiv.org/abs/2205.12393: “CT0: Fine-Tuned Language Models Are Continual Learners”, -
https://arxiv.org/abs/2205.06175#deepmind: “Gato: A Generalist Agent”, -
https://arxiv.org/abs/2204.03514#facebook: “Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale”, -
https://arxiv.org/abs/2204.01691#google: “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, -
https://arxiv.org/abs/2204.00598#google: “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, -
https://arxiv.org/abs/2202.05008#google: “EvoJAX: Hardware-Accelerated Neuroevolution”, -
https://arxiv.org/abs/2201.03544: “The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”, -
https://arxiv.org/abs/2112.09332#openai: “WebGPT: Browser-Assisted Question-Answering With Human Feedback”, -
https://openai.com/research/webgpt: “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, -
https://arxiv.org/abs/2111.09259#deepmind: “Acquisition of Chess Knowledge in AlphaZero”, -
https://arxiv.org/abs/2111.01587#deepmind: “Procedural Generalization by Planning With Self-Supervised World Models”, -
https://arxiv.org/abs/2109.10862#openai: “Recursively Summarizing Books With Human Feedback”, -
https://proceedings.mlr.press/v139/vicol21a.html: “PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies”, -
https://arxiv.org/abs/2106.13281#google: “Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, -
https://arxiv.org/abs/2105.12196#deepmind: “From Motor Control to Team Play in Simulated Humanoid Football”, -
https://www.sciencedirect.com/science/article/pii/S0004370221000862#deepmind: “Reward Is Enough”, -
https://arxiv.org/abs/2104.06272#deepmind: “Podracer Architectures for Scalable Reinforcement Learning”, -
https://arxiv.org/abs/2104.06294#deepmind: “MuZero Unplugged: Online and Offline Reinforcement Learning by Planning With a Learned Model”, -
https://arxiv.org/abs/2012.05672#deepmind: “Imitating Interactive Intelligence”, -
https://greydanus.github.io/2020/12/01/scaling-down/: “Scaling down Deep Learning”, -
https://arxiv.org/abs/2102.04881: “Measuring Progress in Deep Reinforcement Learning Sample Efficiency”, -
https://deepmind.google/discover/blog/agent57-outperforming-the-human-atari-benchmark/: “Agent57: Outperforming the Human Atari Benchmark”, -
https://openreview.net/forum?id=SyxrxR4KPS#deepmind: “Deep Neuroethology of a Virtual Rodent”, -
https://openai.com/research/procgen-benchmark: “Procgen Benchmark: We’re Releasing Procgen Benchmark, 16 Simple-To-Use Procedurally-Generated Environments Which Provide a Direct Measure of How Quickly a Reinforcement Learning Agent Learns Generalizable Skills”, -
https://arxiv.org/abs/1911.00357#facebook: “DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames”, -
2019-vinyals.pdf#deepmind: “Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning”, -
https://openai.com/research/emergent-tool-use#surprisingbehaviors: “Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior”, -
2019-jaderberg.pdf#deepmind: “Human-Level Performance in 3D Multiplayer Games With Population-Based Reinforcement Learning”, -
https://arxiv.org/abs/1904.01201#facebook: “Habitat: A Platform for Embodied AI Research”, -
https://openai.com/research/how-ai-training-scales: “How AI Training Scales”, -
https://openai.com/research/ai-and-compute: “AI and Compute”, -
https://web.archive.org/web/20230718144747/https://frc.ri.cmu.edu/~hpm/project.archive/robot.papers/2004/Predictions.html: “Robot Predictions Evolution”,