‘AlphaGo’ tag
- See Also
-
Links
- “Free Process Rewards without Process Labels”, Yuan et al 2024
- “Learning Formal Mathematics From Intrinsic Motivation”, Poesia et al 2024
- “Can Go AIs Be Adversarially Robust?”, Tseng et al 2024
- “Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge”, Strieth-Kalthoff et al 2024
- “Gold-Medalist Coders Build an AI That Can Do Their Job for Them: A New Startup Called Cognition AI Can Turn a User’s Prompt into a Website or Video Game”, Vance 2024
- “Beyond A✱: Better Planning With Transformers via Search Dynamics Bootstrapping (Searchformer)”, Lehnert et al 2024
- “Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation”, Ding et al 2023
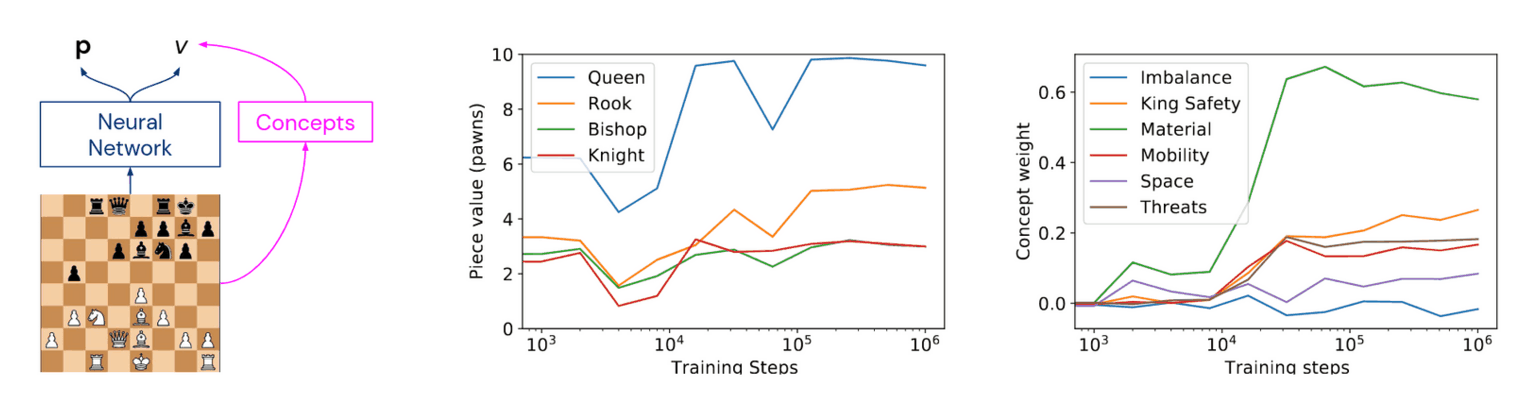
- “Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero”, Schut et al 2023
- “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, Zahavy et al 2023
- “Self-Play Reinforcement Learning Guides Protein Engineering”, Wang et al 2023c
- “Evaluating Superhuman Models With Consistency Checks”, Fluri et al 2023
- “BetaZero: Belief-State Planning for Long-Horizon POMDPs Using Learned Approximations”, Moss et al 2023
- “Who Will You Be After ChatGPT Takes Your Job? Generative AI Is Coming for White-Collar Roles. If Your Sense of worth Comes from Work—What’s Left to Hold on To?”, Thomas 2023
- “AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong”, Blüml et al 2023
- “Solving Math Word Problems With Process & Outcome-Based Feedback”, Uesato et al 2022
- “Are AlphaZero-Like Agents Robust to Adversarial Perturbations?”, Lan et al 2022
- “Adversarial Policies Beat Superhuman Go AIs”, Wang et al 2022
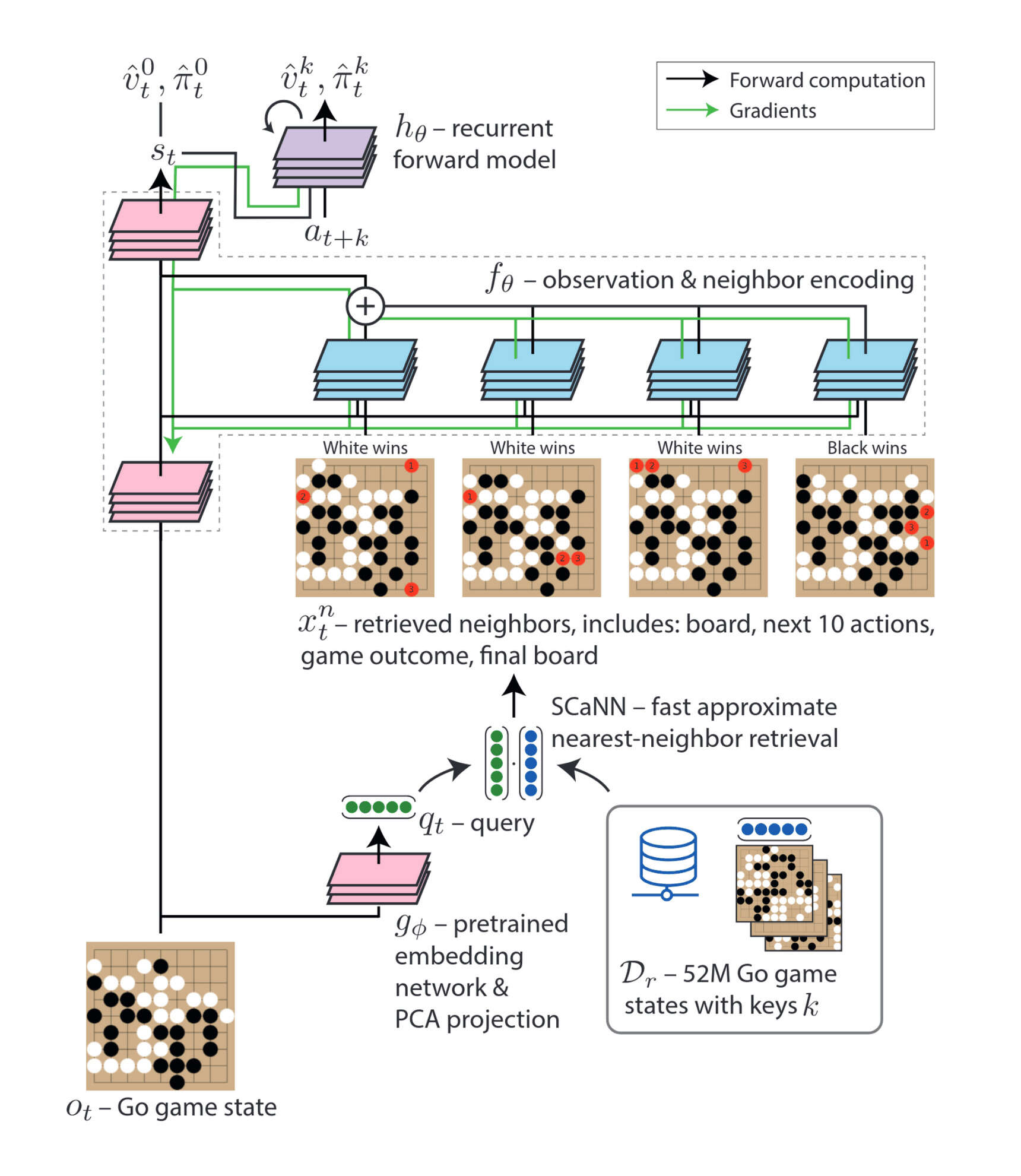
- “Large-Scale Retrieval for Reinforcement Learning”, Humphreys et al 2022
- “Newton’s Method for Reinforcement Learning and Model Predictive Control”, Bertsekas 2022
- “HTPS: HyperTree Proof Search for Neural Theorem Proving”, Lample et al 2022
- “CrossBeam: Learning to Search in Bottom-Up Program Synthesis”, Shi et al 2022
- “Policy Improvement by Planning With Gumbel”, Danihelka et al 2022
- “Formal Mathematics Statement Curriculum Learning”, Polu et al 2022
- “Player of Games”, Schmid et al 2021
- “Ν-SDDP: Neural Stochastic Dual Dynamic Programming”, Dai et al 2021
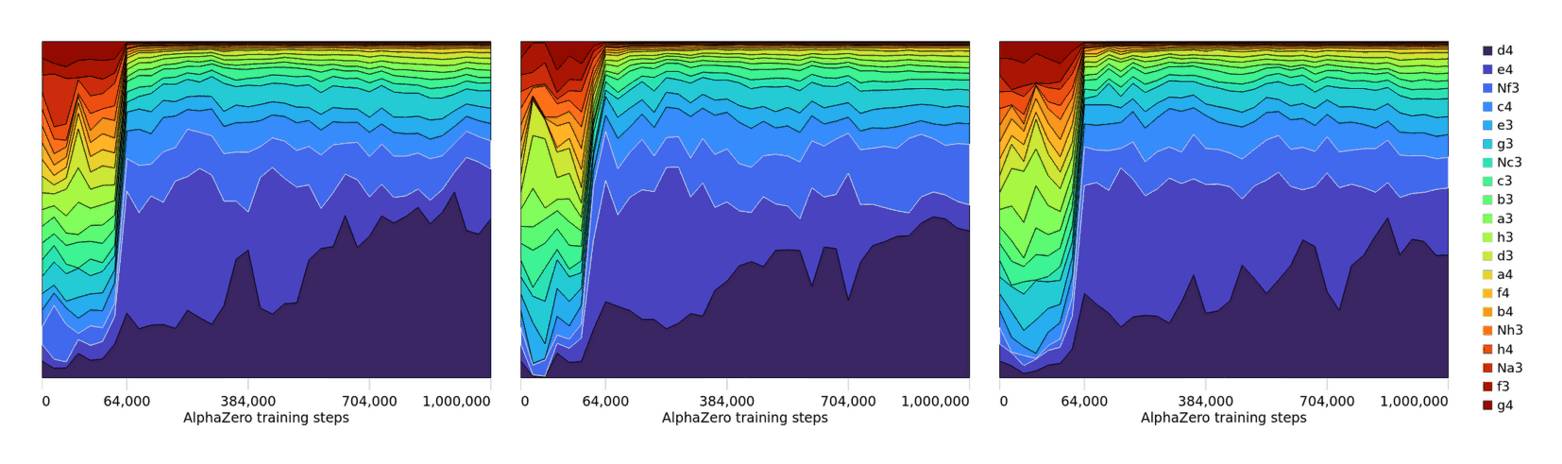
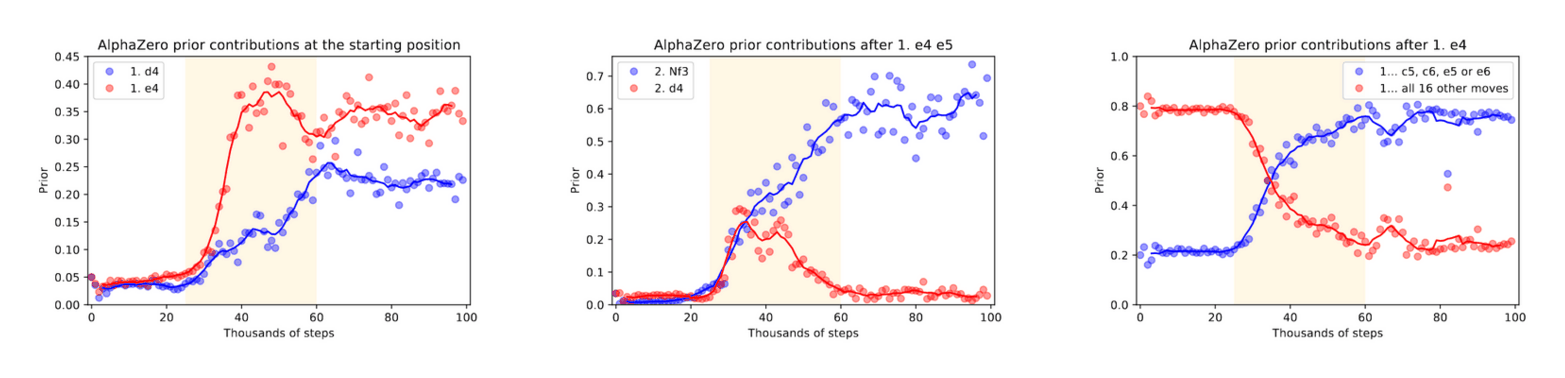
- “Acquisition of Chess Knowledge in AlphaZero”, McGrath et al 2021
- “Evaluating Model-Based Planning and Planner Amortization for Continuous Control”, Byravan et al 2021
- “Scalable Online Planning via Reinforcement Learning Fine-Tuning”, Fickinger et al 2021
- “Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control”, Bertsekas 2021
- “How Does AI Improve Human Decision-Making? Evidence from the AI-Powered Go Program”, Choi et al 2021
- “Train on Small, Play the Large: Scaling Up Board Games With AlphaZero and GNN”, Ben-Assayag & El-Yaniv 2021
- “Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments”, Riviere et al 2021
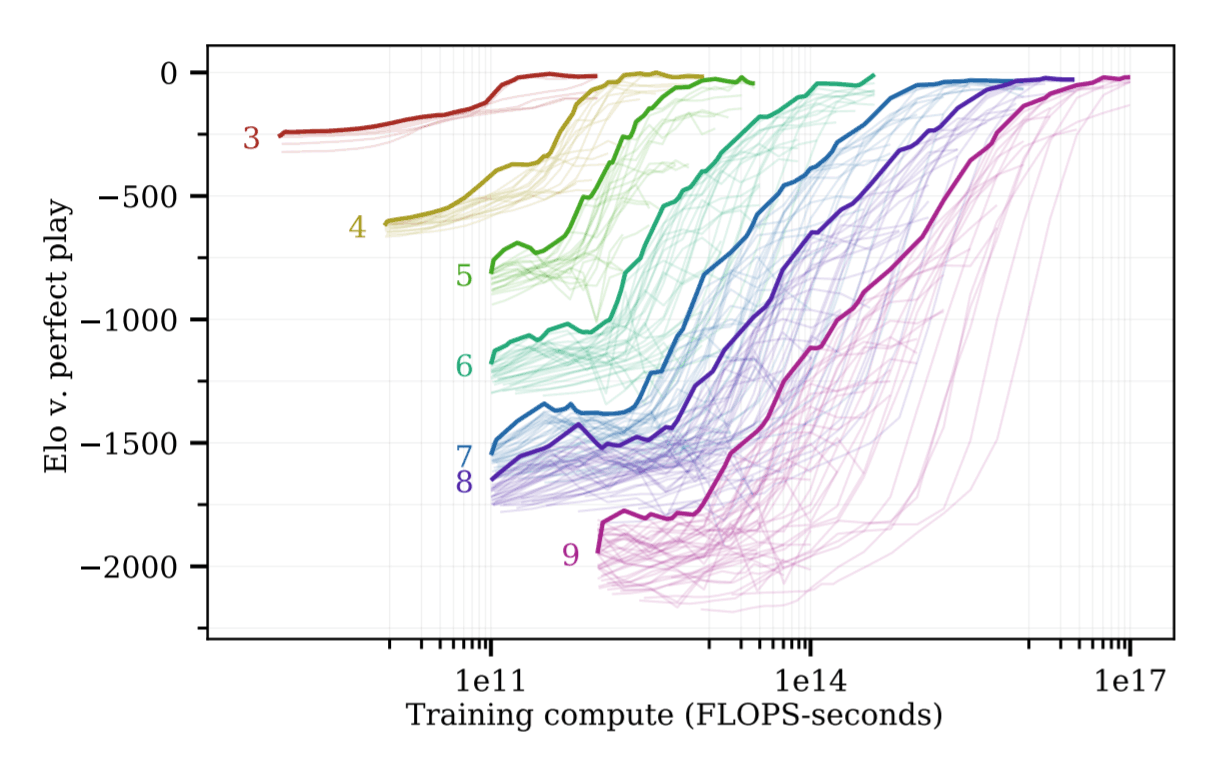
- “Scaling Scaling Laws With Board Games”, Jones 2021
- “OLIVAW: Mastering Othello without Human Knowledge, nor a Fortune”, Norelli & Panconesi 2021
- “Transfer of Fully Convolutional Policy-Value Networks Between Games and Game Variants”, Soemers et al 2021
- “Investment vs. Reward in a Competitive Knapsack Problem”, Neumann & Gros 2021
- “Solving Mixed Integer Programs Using Neural Networks”, Nair et al 2020
- “Monte-Carlo Graph Search for AlphaZero”, Czech et al 2020
- “Learning to Stop: Dynamic Simulation Monte-Carlo Tree Search”, Lan et al 2020
- “Assessing Game Balance With AlphaZero: Exploring Alternative Rule Sets in Chess”, Tomašev et al 2020
- “Learning Personalized Models of Human Behavior in Chess”, McIlroy-Young et al 2020
- “Learning Compositional Neural Programs for Continuous Control”, Pierrot et al 2020
- “ReBeL: Combining Deep Reinforcement Learning and Search for Imperfect-Information Games”, Brown et al 2020
- “Monte-Carlo Tree Search As Regularized Policy Optimization”, Grill et al 2020
- “Tackling Morpion Solitaire With AlphaZero-Like Ranked Reward Reinforcement Learning”, Wang et al 2020
- “Aligning Superhuman AI With Human Behavior: Chess As a Model System”, McIlroy-Young et al 2020
- “Neural Machine Translation With Monte-Carlo Tree Search”, Parker & Chen 2020
- “Real World Games Look Like Spinning Tops”, Czarnecki et al 2020
- “Approximate Exploitability: Learning a Best Response in Large Games”, Timbers et al 2020
- “Accelerating and Improving AlphaZero Using Population Based Training”, Wu et al 2020
- “Self-Play Learning Without a Reward Metric”, Schmidt et al 2019
- “(Yonhap Interview) Go Master Lee Says He Quits—Unable to Win over AI Go Players”, Agency 2019
- “MuZero: Mastering Atari, Go, Chess and Shogi by Planning With a Learned Model”, Schrittwieser et al 2019
- “Multiplayer AlphaZero”, Petosa & Balch 2019
- “Global Optimization of Quantum Dynamics With AlphaZero Deep Exploration”, Dalgaard et al 2019
- “Learning Compositional Neural Programs With Recursive Tree Search and Planning”, Pierrot et al 2019
- “Π-IW: Deep Policies for Width-Based Planning in Pixel Domains”, Junyent et al 2019
- “Policy Gradient Search: Online Planning and Expert Iteration without Search Trees”, Anthony et al 2019
- “AlphaX: EXploring Neural Architectures With Deep Neural Networks and Monte Carlo Tree Search”, Wang et al 2019
- “Minigo: A Case Study in Reproducing Reinforcement Learning Research”, Anonymous 2019
- “Α-Rank: Multi-Agent Evaluation by Evolution”, Omidshafiei et al 2019
- “Accelerating Self-Play Learning in Go”, Wu 2019
- “ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero”, Tian et al 2019
- “Bayesian Optimization in AlphaGo”, Chen et al 2018
- “A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go through Self-Play”, Silver et al 2018
- “Deep Reinforcement Learning”, Li 2018
- “AlphaSeq: Sequence Discovery With Deep Reinforcement Learning”, Shao et al 2018
- “ExIt-OOS: Towards Learning from Planning in Imperfect Information Games”, Kitchen & Benedetti 2018
- “Has Dynamic Programming Improved Decision Making?”, Rust 2018
- “Surprising Negative Results for Generative Adversarial Tree Search”, Azizzadenesheli et al 2018
- “Improving Width-Based Planning With Compact Policies”, Junyent et al 2018
- “Dual Policy Iteration”, Sun et al 2018
- “Solving the Rubik’s Cube Without Human Knowledge”, McAleer et al 2018
- “Feedback-Based Tree Search for Reinforcement Learning”, Jiang et al 2018
- “A Tree Search Algorithm for Sequence Labeling”, Lao et al 2018
- “Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations”, Bertsekas 2018
- “Sim-To-Real Optimization of Complex Real World Mobile Network With Imperfect Information via Deep Reinforcement Learning from Self-Play”, Tan et al 2018
- “Learning to Search With MCTSnets”, Guez et al 2018
- “M-Walk: Learning to Walk over Graphs Using Monte Carlo Tree Search”, Shen et al 2018
- “Mastering Chess and Shogi by Self-Play With a General Reinforcement Learning Algorithm”, Silver et al 2017
- “AlphaGo Zero: Mastering the Game of Go without Human Knowledge”, Silver et al 2017
- “Self-Taught AI Is Best yet at Strategy Game Go”, Gibney 2017
- “DeepMind’s Latest AI Breakthrough Is Its Most Important Yet: Google-Owned DeepMind’s Go-Playing Artificial Intelligence Can Now Learn without Human Help… or Data”, Burgess 2017
- “Learning Generalized Reactive Policies Using Deep Neural Networks”, Groshev et al 2017
- “Learning to Plan Chemical Syntheses”, Segler et al 2017
- “Thinking Fast and Slow With Deep Learning and Tree Search”, Anthony et al 2017
- “DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker”, Moravčík et al 2017
- “Mastering the Game of Go With Deep Neural Networks and Tree Search”, Silver et al 2016
- “Giraffe: Using Deep Reinforcement Learning to Play Chess”, Lai 2015
- “Algorithmic Progress in Six Domains”, Grace 2013
- “Reinforcement Learning As Classification: Leveraging Modern Classifiers”, Lagoudakis & Parr 2003
- “Deep-Learning the Hardest Go Problem in the World”
- “Learning From Scratch by Thinking Fast and Slow With Deep Learning and Tree Search”
- “Acquisition of Chess Knowledge in AlphaZero”
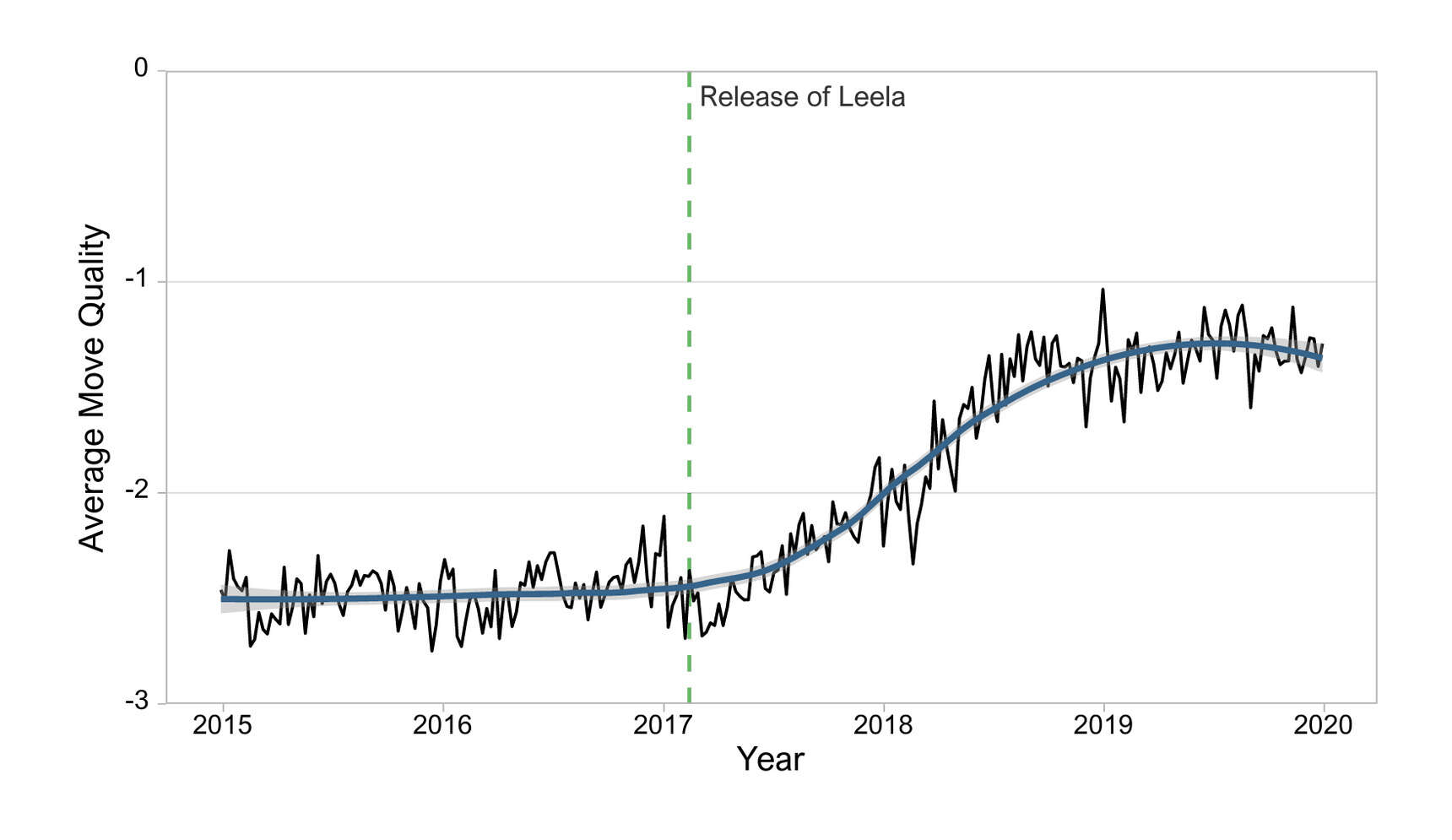
- “Leela Chess Zero: AlphaZero for the PC”
- “The Future Is Here – AlphaZero Learns Chess”
- “Trading Off Compute in Training and Inference”
- “Trading Off Compute in Training and Inference § MCTS Scaling”
- “Beyond the Board: Exploring AI Robustness Through Go”
- “Monte Carlo Tree Search in JAX”
- “An Open-Source Implementation of the AlphaGoZero Algorithm”
- “Adversarial Policies in Go”
- “The 3 Tricks That Made AlphaGo Zero Work”
- “AlphaGo Zero and the Foom Debate”
- “How to Build Your Own AlphaZero AI Using Python and Keras”, Foster 2025
- “Reading the Tea Leaves: Expert End-Users Explaining the Unexplainable”
- Sort By Magic
- Wikipedia
- Miscellaneous
- Bibliography
See Also
Links
“Free Process Rewards without Process Labels”, Yuan et al 2024
“Learning Formal Mathematics From Intrinsic Motivation”, Poesia et al 2024
“Can Go AIs Be Adversarially Robust?”, Tseng et al 2024
“Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge”, Strieth-Kalthoff et al 2024
Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge
“Gold-Medalist Coders Build an AI That Can Do Their Job for Them: A New Startup Called Cognition AI Can Turn a User’s Prompt into a Website or Video Game”, Vance 2024
“Beyond A✱: Better Planning With Transformers via Search Dynamics Bootstrapping (Searchformer)”, Lehnert et al 2024
Beyond A✱: Better Planning with Transformers via Search Dynamics Bootstrapping (Searchformer)
“Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation”, Ding et al 2023
Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
“Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero”, Schut et al 2023
Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero
“Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, Zahavy et al 2023
Diversifying AI: Towards Creative Chess with AlphaZero (AZdb)
“Self-Play Reinforcement Learning Guides Protein Engineering”, Wang et al 2023c
“Evaluating Superhuman Models With Consistency Checks”, Fluri et al 2023
“BetaZero: Belief-State Planning for Long-Horizon POMDPs Using Learned Approximations”, Moss et al 2023
BetaZero: Belief-State Planning for Long-Horizon POMDPs using Learned Approximations
“Who Will You Be After ChatGPT Takes Your Job? Generative AI Is Coming for White-Collar Roles. If Your Sense of worth Comes from Work—What’s Left to Hold on To?”, Thomas 2023
“AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong”, Blüml et al 2023
AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong
“Solving Math Word Problems With Process & Outcome-Based Feedback”, Uesato et al 2022
Solving math word problems with process & outcome-based feedback
“Are AlphaZero-Like Agents Robust to Adversarial Perturbations?”, Lan et al 2022
Are AlphaZero-like Agents Robust to Adversarial Perturbations?
“Adversarial Policies Beat Superhuman Go AIs”, Wang et al 2022
“Large-Scale Retrieval for Reinforcement Learning”, Humphreys et al 2022
“Newton’s Method for Reinforcement Learning and Model Predictive Control”, Bertsekas 2022
Newton’s method for reinforcement learning and model predictive control
“HTPS: HyperTree Proof Search for Neural Theorem Proving”, Lample et al 2022
“CrossBeam: Learning to Search in Bottom-Up Program Synthesis”, Shi et al 2022
CrossBeam: Learning to Search in Bottom-Up Program Synthesis
“Policy Improvement by Planning With Gumbel”, Danihelka et al 2022
“Formal Mathematics Statement Curriculum Learning”, Polu et al 2022
“Player of Games”, Schmid et al 2021
“Ν-SDDP: Neural Stochastic Dual Dynamic Programming”, Dai et al 2021
“Acquisition of Chess Knowledge in AlphaZero”, McGrath et al 2021
“Evaluating Model-Based Planning and Planner Amortization for Continuous Control”, Byravan et al 2021
Evaluating model-based planning and planner amortization for continuous control
“Scalable Online Planning via Reinforcement Learning Fine-Tuning”, Fickinger et al 2021
Scalable Online Planning via Reinforcement Learning Fine-Tuning
“Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control”, Bertsekas 2021
Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control
“How Does AI Improve Human Decision-Making? Evidence from the AI-Powered Go Program”, Choi et al 2021
How Does AI Improve Human Decision-Making? Evidence from the AI-Powered Go Program
“Train on Small, Play the Large: Scaling Up Board Games With AlphaZero and GNN”, Ben-Assayag & El-Yaniv 2021
Train on Small, Play the Large: Scaling Up Board Games with AlphaZero and GNN
“Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments”, Riviere et al 2021
Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments
“Scaling Scaling Laws With Board Games”, Jones 2021
“OLIVAW: Mastering Othello without Human Knowledge, nor a Fortune”, Norelli & Panconesi 2021
OLIVAW: Mastering Othello without Human Knowledge, nor a Fortune
“Transfer of Fully Convolutional Policy-Value Networks Between Games and Game Variants”, Soemers et al 2021
Transfer of Fully Convolutional Policy-Value Networks Between Games and Game Variants
“Investment vs. Reward in a Competitive Knapsack Problem”, Neumann & Gros 2021
“Solving Mixed Integer Programs Using Neural Networks”, Nair et al 2020
“Monte-Carlo Graph Search for AlphaZero”, Czech et al 2020
“Learning to Stop: Dynamic Simulation Monte-Carlo Tree Search”, Lan et al 2020
Learning to Stop: Dynamic Simulation Monte-Carlo Tree Search
“Assessing Game Balance With AlphaZero: Exploring Alternative Rule Sets in Chess”, Tomašev et al 2020
Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess
“Learning Personalized Models of Human Behavior in Chess”, McIlroy-Young et al 2020
“Learning Compositional Neural Programs for Continuous Control”, Pierrot et al 2020
Learning Compositional Neural Programs for Continuous Control
“ReBeL: Combining Deep Reinforcement Learning and Search for Imperfect-Information Games”, Brown et al 2020
ReBeL: Combining Deep Reinforcement Learning and Search for Imperfect-Information Games
“Monte-Carlo Tree Search As Regularized Policy Optimization”, Grill et al 2020
“Tackling Morpion Solitaire With AlphaZero-Like Ranked Reward Reinforcement Learning”, Wang et al 2020
Tackling Morpion Solitaire with AlphaZero-like Ranked Reward Reinforcement Learning
“Aligning Superhuman AI With Human Behavior: Chess As a Model System”, McIlroy-Young et al 2020
Aligning Superhuman AI with Human Behavior: Chess as a Model System
“Neural Machine Translation With Monte-Carlo Tree Search”, Parker & Chen 2020
“Real World Games Look Like Spinning Tops”, Czarnecki et al 2020
“Approximate Exploitability: Learning a Best Response in Large Games”, Timbers et al 2020
Approximate exploitability: Learning a best response in large games
“Accelerating and Improving AlphaZero Using Population Based Training”, Wu et al 2020
Accelerating and Improving AlphaZero Using Population Based Training
“Self-Play Learning Without a Reward Metric”, Schmidt et al 2019
“(Yonhap Interview) Go Master Lee Says He Quits—Unable to Win over AI Go Players”, Agency 2019
(Yonhap Interview) Go master Lee says he quits—unable to win over AI Go players
“MuZero: Mastering Atari, Go, Chess and Shogi by Planning With a Learned Model”, Schrittwieser et al 2019
MuZero: Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
“Multiplayer AlphaZero”, Petosa & Balch 2019
“Global Optimization of Quantum Dynamics With AlphaZero Deep Exploration”, Dalgaard et al 2019
Global optimization of quantum dynamics with AlphaZero deep exploration
“Learning Compositional Neural Programs With Recursive Tree Search and Planning”, Pierrot et al 2019
Learning Compositional Neural Programs with Recursive Tree Search and Planning
“Π-IW: Deep Policies for Width-Based Planning in Pixel Domains”, Junyent et al 2019
π-IW: Deep Policies for Width-Based Planning in Pixel Domains
“Policy Gradient Search: Online Planning and Expert Iteration without Search Trees”, Anthony et al 2019
Policy Gradient Search: Online Planning and Expert Iteration without Search Trees
“AlphaX: EXploring Neural Architectures With Deep Neural Networks and Monte Carlo Tree Search”, Wang et al 2019
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
“Minigo: A Case Study in Reproducing Reinforcement Learning Research”, Anonymous 2019
Minigo: A Case Study in Reproducing Reinforcement Learning Research
“Α-Rank: Multi-Agent Evaluation by Evolution”, Omidshafiei et al 2019
“Accelerating Self-Play Learning in Go”, Wu 2019
“ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero”, Tian et al 2019
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
“Bayesian Optimization in AlphaGo”, Chen et al 2018
“A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go through Self-Play”, Silver et al 2018
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
“Deep Reinforcement Learning”, Li 2018
“AlphaSeq: Sequence Discovery With Deep Reinforcement Learning”, Shao et al 2018
AlphaSeq: Sequence Discovery with Deep Reinforcement Learning
“ExIt-OOS: Towards Learning from Planning in Imperfect Information Games”, Kitchen & Benedetti 2018
ExIt-OOS: Towards Learning from Planning in Imperfect Information Games
“Has Dynamic Programming Improved Decision Making?”, Rust 2018
“Surprising Negative Results for Generative Adversarial Tree Search”, Azizzadenesheli et al 2018
Surprising Negative Results for Generative Adversarial Tree Search
“Improving Width-Based Planning With Compact Policies”, Junyent et al 2018
“Dual Policy Iteration”, Sun et al 2018
“Solving the Rubik’s Cube Without Human Knowledge”, McAleer et al 2018
“Feedback-Based Tree Search for Reinforcement Learning”, Jiang et al 2018
“A Tree Search Algorithm for Sequence Labeling”, Lao et al 2018
“Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations”, Bertsekas 2018
Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations
“Sim-To-Real Optimization of Complex Real World Mobile Network With Imperfect Information via Deep Reinforcement Learning from Self-Play”, Tan et al 2018
“Learning to Search With MCTSnets”, Guez et al 2018
“M-Walk: Learning to Walk over Graphs Using Monte Carlo Tree Search”, Shen et al 2018
M-Walk: Learning to Walk over Graphs using Monte Carlo Tree Search
“Mastering Chess and Shogi by Self-Play With a General Reinforcement Learning Algorithm”, Silver et al 2017
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
“AlphaGo Zero: Mastering the Game of Go without Human Knowledge”, Silver et al 2017
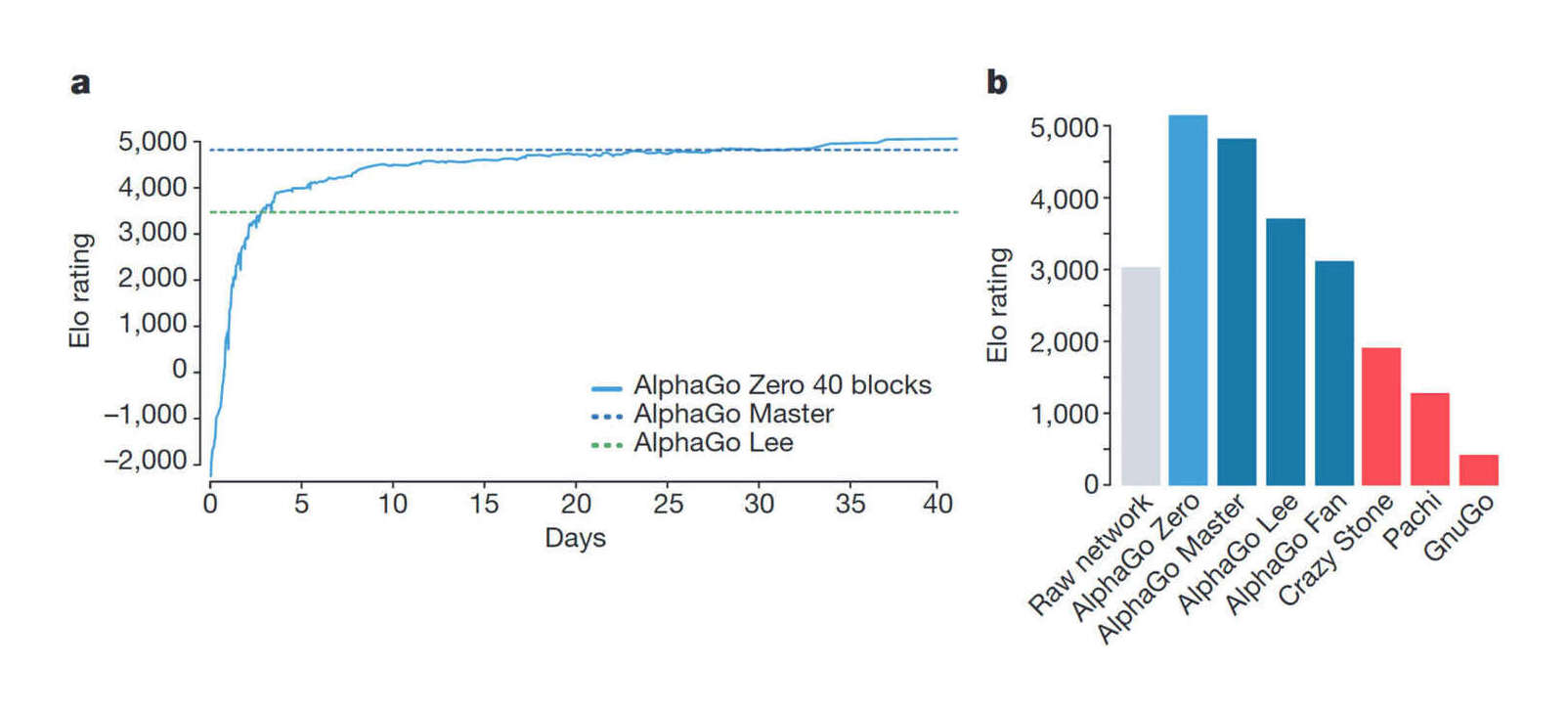
AlphaGo Zero: Mastering the game of Go without human knowledge
“Self-Taught AI Is Best yet at Strategy Game Go”, Gibney 2017
“DeepMind’s Latest AI Breakthrough Is Its Most Important Yet: Google-Owned DeepMind’s Go-Playing Artificial Intelligence Can Now Learn without Human Help… or Data”, Burgess 2017
“Learning Generalized Reactive Policies Using Deep Neural Networks”, Groshev et al 2017
Learning Generalized Reactive Policies using Deep Neural Networks
“Learning to Plan Chemical Syntheses”, Segler et al 2017
“Thinking Fast and Slow With Deep Learning and Tree Search”, Anthony et al 2017
“DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker”, Moravčík et al 2017
DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker
“Mastering the Game of Go With Deep Neural Networks and Tree Search”, Silver et al 2016
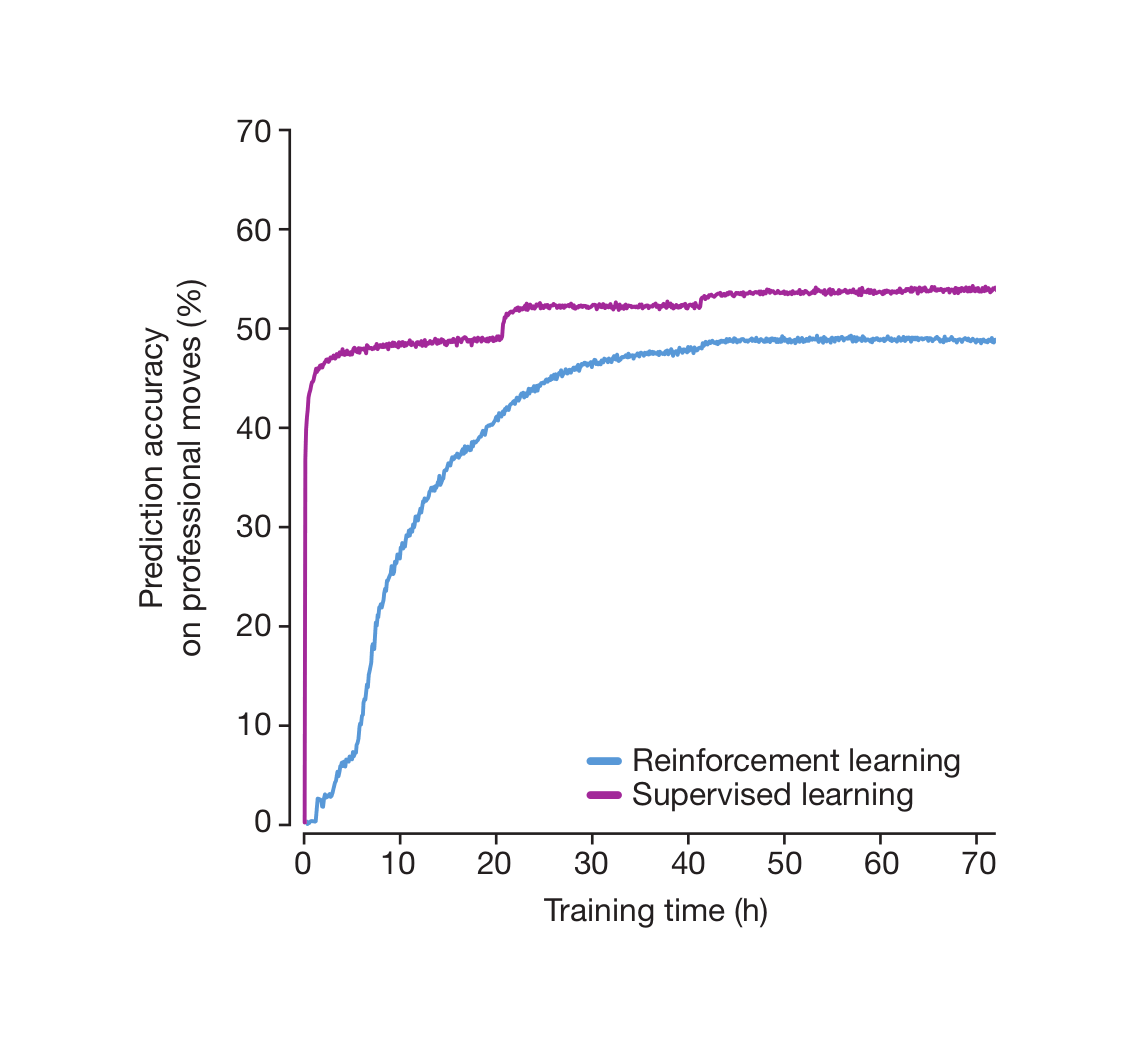
Mastering the game of Go with deep neural networks and tree search
“Giraffe: Using Deep Reinforcement Learning to Play Chess”, Lai 2015
“Algorithmic Progress in Six Domains”, Grace 2013
“Reinforcement Learning As Classification: Leveraging Modern Classifiers”, Lagoudakis & Parr 2003
Reinforcement Learning as Classification: Leveraging Modern Classifiers:
“Deep-Learning the Hardest Go Problem in the World”
“Learning From Scratch by Thinking Fast and Slow With Deep Learning and Tree Search”
Learning From Scratch by Thinking Fast and Slow with Deep Learning and Tree Search:
“Acquisition of Chess Knowledge in AlphaZero”
“Leela Chess Zero: AlphaZero for the PC”
“The Future Is Here – AlphaZero Learns Chess”
“Trading Off Compute in Training and Inference”
“Trading Off Compute in Training and Inference § MCTS Scaling”
Trading Off Compute in Training and Inference § MCTS scaling
“Beyond the Board: Exploring AI Robustness Through Go”
“Monte Carlo Tree Search in JAX”
“An Open-Source Implementation of the AlphaGoZero Algorithm”
“Adversarial Policies in Go”
“The 3 Tricks That Made AlphaGo Zero Work”
“AlphaGo Zero and the Foom Debate”
AlphaGo Zero and the Foom Debate:
View External Link:
“How to Build Your Own AlphaZero AI Using Python and Keras”, Foster 2025
“Reading the Tea Leaves: Expert End-Users Explaining the Unexplainable”
Reading the Tea Leaves: Expert End-Users Explaining the Unexplainable
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
evaluate-models
mathematical-reasoning
chess-ai
monte-carlo-search
game-mastery
Wikipedia
Miscellaneous
-
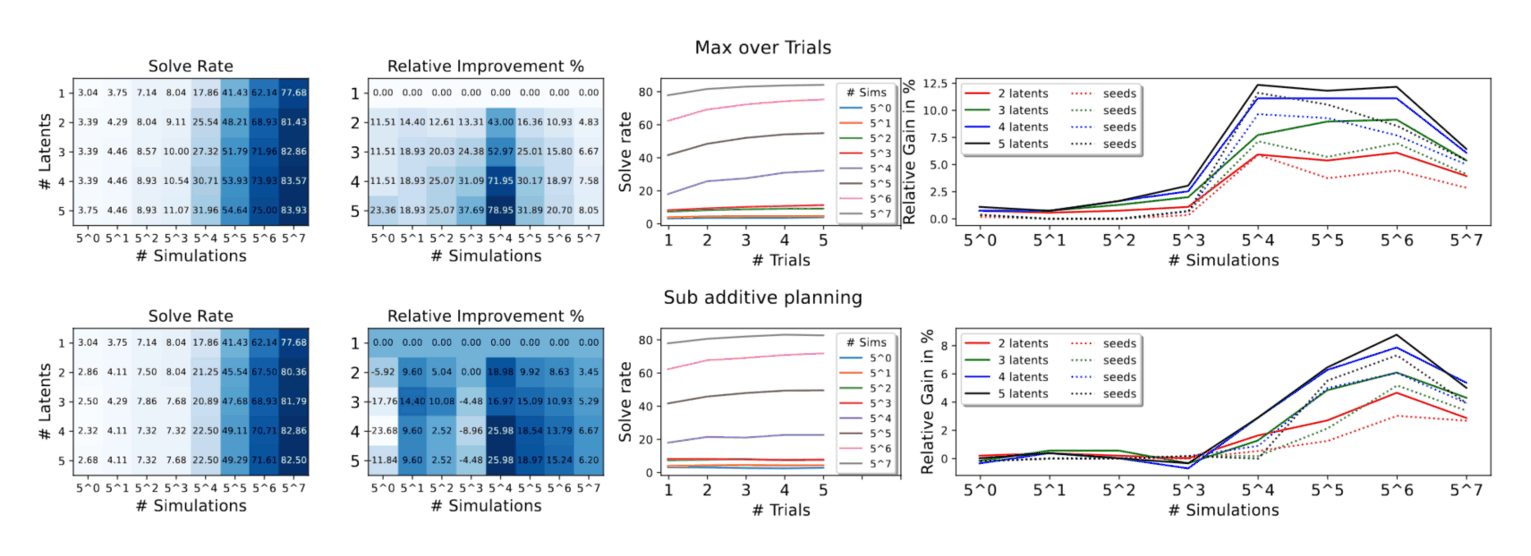
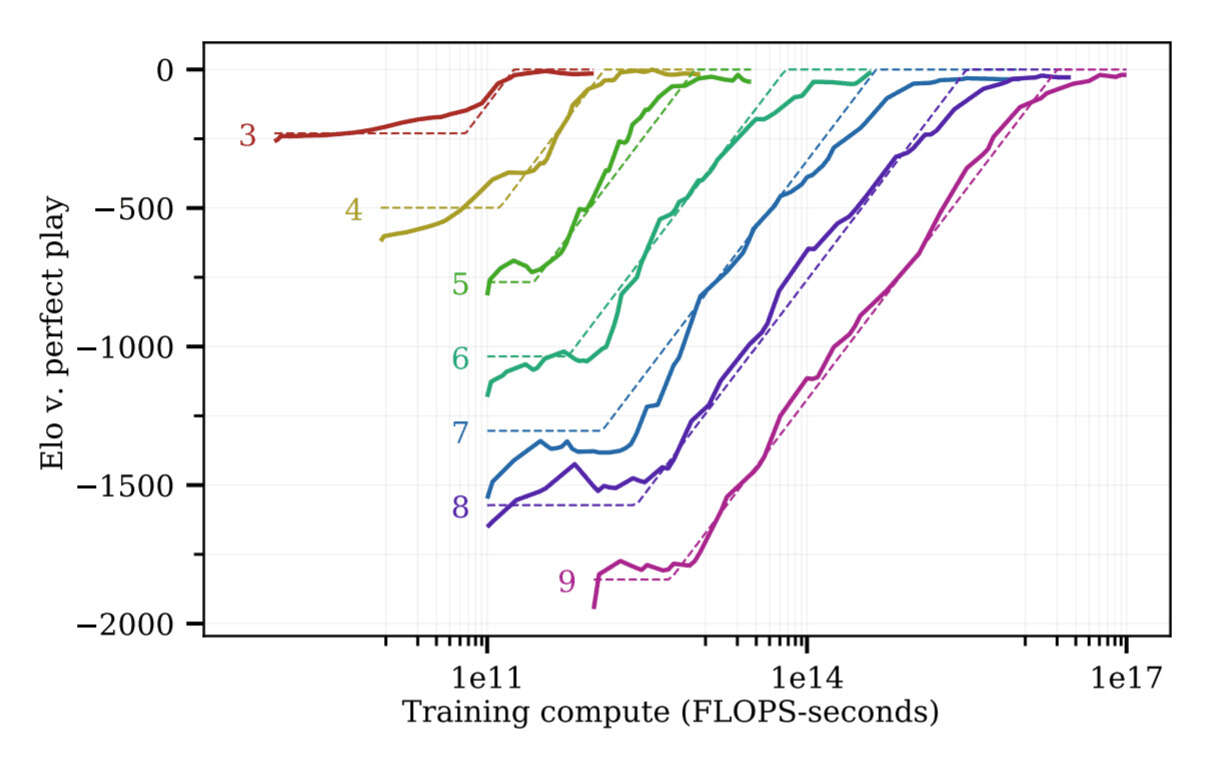
/doc/reinforcement-learning/model/alphago/2021-jones-figure5-alphazerohexscalinglaws.png: -
/doc/reinforcement-learning/model/alphago/2021-jones-figure6-computerfrontierbyboardsize.jpg: -
http://cl-informatik.uibk.ac.at/cek/holstep/ckfccs-holstep-submitted.pdf: -
https://cacm.acm.org/magazines/2021/9/255049-playing-with-and-against-computers/abstract: -
https://conversationswithtyler.com/episodes/vishy-anand/:View External Link:
-
https://proceedings.neurips.cc/paper/2014/file/8bb88f80d334b1869781beb89f7b73be-Paper.pdf: -
https://research.google/blog/leveraging-machine-learning-for-game-development/ -
https://www.deepmind.com/blog/alphazero-shedding-new-light-grand-games-chess-shogi-and-go/ -
https://www.reddit.com/r/baduk/comments/qqjw64/shin_jinseo_ai_difference_shrinking/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
-
https://arxiv.org/abs/2412.01981: “Free Process Rewards without Process Labels”, -
2024-striethkalthoff.pdf: “Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge”, -
https://www.bloomberg.com/news/articles/2024-03-12/cognition-ai-is-a-peter-thiel-backed-coding-assistant: “Gold-Medalist Coders Build an AI That Can Do Their Job for Them: A New Startup Called Cognition AI Can Turn a User’s Prompt into a Website or Video Game”, -
https://arxiv.org/abs/2310.16410#deepmind: “Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero”, -
https://arxiv.org/abs/2308.09175#deepmind: “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, -
https://www.wired.com/story/status-work-generative-artificial-intelligence/: “Who Will You Be After ChatGPT Takes Your Job? Generative AI Is Coming for White-Collar Roles. If Your Sense of worth Comes from Work—What’s Left to Hold on To?”, -
https://arxiv.org/abs/2211.03769: “Are AlphaZero-Like Agents Robust to Adversarial Perturbations?”, -
https://arxiv.org/abs/2211.00241: “Adversarial Policies Beat Superhuman Go AIs”, -
https://arxiv.org/abs/2206.05314#deepmind: “Large-Scale Retrieval for Reinforcement Learning”, -
https://arxiv.org/abs/2205.11491#facebook: “HTPS: HyperTree Proof Search for Neural Theorem Proving”, -
https://openreview.net/forum?id=bERaNdoegnO#deepmind: “Policy Improvement by Planning With Gumbel”, -
https://arxiv.org/abs/2202.01344#openai: “Formal Mathematics Statement Curriculum Learning”, -
https://arxiv.org/abs/2112.03178#deepmind: “Player of Games”, -
https://arxiv.org/abs/2111.09259#deepmind: “Acquisition of Chess Knowledge in AlphaZero”, -
https://arxiv.org/abs/2009.04374#deepmind: “Assessing Game Balance With AlphaZero: Exploring Alternative Rule Sets in Chess”, -
https://arxiv.org/abs/2003.06212: “Accelerating and Improving AlphaZero Using Population Based Training”, -
https://arxiv.org/abs/1806.05898: “Improving Width-Based Planning With Compact Policies”, -
2017-silver.pdf#deepmind: “AlphaGo Zero: Mastering the Game of Go without Human Knowledge”,