Machine Learning Scaling
Bibliography of ML scaling papers showing smooth scaling of neural net performance in general with increasingly large parameters, data, & compute.
-
“Do Deep Convolutional Nets Really Need to be Deep and Convolutional?”, et al 2016 (negative result, particularly on scaling—wrong, but why?)
-
“Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, et al 2017
-
“Deep Learning Scaling is Predictable, Empirically”, et al 2017
-
“Learning Visual Features from Large Weakly Supervised Data”, et al 2015; “Exploring the Limits of Weakly Supervised Pretraining”, et al 2018; “Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, et al 2022 (CNNs scale to billions of hashtagged Instagram images)
-
WebVision: “WebVision Challenge: Visual Learning and Understanding With Web Data”, et al 2017a/“WebVision Database: Visual Learning and Understanding from Web Data”, et al 2017b/“CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”, et al 2018
-
“Measuring the Effects of Data Parallelism on Neural Network Training”, et al 2018
-
“Gradient Noise Scale: An Empirical Model of Large-Batch Training”, et al 2018
-
“A Constructive Prediction of the Generalization Error Across Scales”, et al 2019
-
“EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, 2019
-
“Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, et al 2020
-
“Small Data, Big Decisions: Model Selection in the Small-Data Regime”, et al 2020
-
Key GPT papers:
-
“Scaling Laws for Neural Language Models”, et al 2020
-
“Scaling Laws for Autoregressive Generative Modeling”, et al 2020 (noise & resolution); “Broken Neural Scaling Laws”, et al 2022
-
“GPT-3: Language Models are Few-Shot Learners”, et al 2020
-
“Measuring Massive Multitask Language Understanding”, et al 2020; “Measuring Mathematical Problem Solving With the MATH Dataset”, et al 2021
-
“Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers”, et al 2021
-
“Scaling Laws for Transfer”, et al 2021; “Scaling Laws for Language Transfer Learning”, Christina Kim ( et al 2021 followup: smooth scaling for En → De/Es/Zh); “When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, et al 2024
-
“Scaling Laws for Neural Machine Translation”, et al 2021; “Data and Parameter Scaling Laws for Neural Machine Translation”, et al 2021; “Unsupervised Neural Machine Translation with Generative Language Models Only”, et al 2021; “Data Scaling Laws in NMT: The Effect of Noise and Architecture”, et al 2022
-
“Recursively Summarizing Books with Human Feedback”, et al 2021
-
“Codex: Evaluating Large Language Models Trained on Code”, et al 2021 (small versions of GitHub Copilot, solves simple linear algebra/statistics problems too); “Program Synthesis with Large Language Models”, et al 2021; “Show Your Work: Scratchpads for Intermediate Computation with Language Models”, et al 2021; “Few-Shot Self-Rationalization with Natural Language Prompts”, et al 2021
-
“Scarecrow: A Framework for Scrutinizing Machine Text”, et al 2021
-
“A Recipe For Arbitrary Text Style Transfer with Large Language Models”, et al 2021
-
Instruction tuning/multi-task finetuning
-
“M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining”, et al 2021
-
“Training Verifiers to Solve Math Word Problems”, et al 2021
-
“Symbolic Knowledge Distillation: from General Language Models to Commonsense Models”, et al 2021
-
“An Explanation of In-Context Learning as Implicit Bayesian Inference”, et al 2021
-
-
“Blender: Recipes for building an open-domain chatbot”, et al 2020
-
“Big Self-Supervised Models are Strong Semi-Supervised Learners”, et al 2020a
-
“iGPT: Generative Pretraining from Pixels”, et al 2020b
-
“GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding”, et al 2020; “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”, et al 2021; “Exploring Sparse Expert Models and Beyond”, et al 2021
-
“On the Predictability of Pruning Across Scales”, et al 2020 (scaling laws for sparsity: initially large size reductions are free, then power-law worsening, then plateau at tiny but bad models)
-
-
“When Do You Need Billions of Words of Pretraining Data?”, et al 2020; “Learning Which Features Matter: RoBERTa Acquires a Preference forLinguistic Generalizations (Eventually)”, et al 2020; “Probing Across Time: What Does RoBERTa Know and When?”, et al 2021
-
CLIP; “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, et al 2021 (see also CC-12M; EfficientNet trained on 1.8 billion images on a TPUv3-1024); “WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”, et al 2021; “Multimodal Few-Shot Learning with Frozen Language Models”, et al 2021; “GrokNet: Unified Computer Vision Model Trunk and Embeddings For Commerce”, et al 2020; “Billion-Scale (Pinterest) Pretraining with Vision Transformers for Multi-Task Visual Representations”, et al 2021
-
“DALL·E 1: Zero-Shot Text-to-Image Generation”, et al 2021 (blog); “M6: A Chinese Multimodal Pretrainer”, et al 2021 (Chinese DALL·E 1: 1.9TB images/0.29TB text for 10b-parameter dense/100b-parameter MoE Transformer; shockingly fast Chinese replication of DALL·E 1/CLIP)
-
“Improved Denoising Diffusion Probabilistic Models”, 2021 (DDPM scaling laws for FID & likelihood)
-
“Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, et al 2021
-
“Scaling Laws for Acoustic Models”, 2021
-
“XLSR: Unsupervised Cross-lingual Representation Learning for Speech Recognition”, et al 2020
-
“Scaling End-to-End Models for Large-Scale Multilingual ASR”, et al 2021; “Scaling ASR Improves Zero and Few Shot Learning”, et al 2021
-
“VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation”, et al 2021; “wav2vec: Large-Scale Self-Supervised and Semi-Supervised Learning for Speech Translation”, et al 2021 (fMRI); “XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale”, et al 2021
-
“HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units”, et al 2021
-
-
“SEER: Self-supervised Pretraining of Visual Features in the Wild”, et al 2021; “Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision”, et al 2022
-
“Fast and Accurate Model Scaling”, et al 2021; “Revisiting ResNets: Improved Training and Scaling Strategies”, et al 2021
-
“XLM-R: Unsupervised Cross-lingual Representation Learning at Scale”, et al 2019; “XLM-R XL/XLM-R XXL: Larger-Scale Transformers for Multilingual Masked Language Modeling”, et al 2021; “Facebook AI WMT21 News Translation Task Submission”, et al 2021
-
“ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation”, et al 2021
-
“LEMON: Scaling Up Vision-Language Pre-training for Image Captioning”, et al 2021
-
“Flamingo: a Visual Language Model for Few-Shot Learning”, et al 2022
-
“Scaling Vision Transformers”, et al 2021
-
“CoAtNet: Marrying Convolution and Attention for All Data Sizes”, et al 2021
-
“BEiT: BERT Pre-Training of Image Transformers”, et al 2021; “Masked Autoencoders Are Scalable Vision Learners”, et al 2021
-
“A Universal Law of Robustness via Isoperimetry”, 2021; “Exploring the Limits of Out-of-Distribution Detection”, et al 2021; “Partial success in closing the gap between human and machine vision”, et al 2021
-
“Effect of scale on catastrophic forgetting in neural networks”, 2021
-
“On the Opportunities and Risks of Foundation Models”, et al 2021 (review)
-
“Exploring the Limits of Large Scale Pre-training”, et al 2021
-
“Scaling Laws for the Few-Shot Adaptation of Pre-trained Image Classifiers”, et al 2021
-
“E(3)-Equivariant Graph Neural Networks for Data-Efficient and Accurate Interatomic Potentials”, et al 2021
-
Face recognition: “WebFace260M: A Benchmark for Million-Scale Deep Face Recognition”, et al 2022
-
“Fine-tuned Language Models are Continual Learners”, Scialom at al 2022
-
Embeddings: “DynamicEmbedding: Extending TensorFlow for Colossal-Scale Applications”, et al 2020; “DLRM: High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models”, et al 2021; “Make Every feature Binary (MEB): A 135b-parameter sparse neural network for massively improved search relevance”; “Persia: A Hybrid System Scaling Deep Learning Based Recommenders up to 100 Trillion Parameters”, et al 2021 (Kuaisho)
-
MLPs/FCs: from the “Fully-Connected Neural Nets” bibliography: et al 2016; “MLP-Mixer: An all-MLP Architecture for Vision”, et al 2021; “gMLP: Pay Attention to MLPs”, et al 2021
-
Reinforcement Learning:
-
“Fine-Tuning Language Models from Human Preferences”, et al 2019; “Learning to summarize from human feedback”, et al 2020
-
“Measuring hardware overhang”, hippke (the curves cross: “with today’s [trained] algorithms, computers would have beat the world chess champion already in 199431ya on a contemporary desk computer”)
-
“Scaling Scaling Laws with Board Games”, 2021 (AlphaZero/Hex: highly-optimized GPU implementation enables showing smooth scaling across 6 OOM of compute—2× FLOPS = 66% victory; amortization of training → runtime tree-search, where 10× training = 15× runtime)
-
“MuZero Unplugged: Online and Offline Reinforcement Learning by Planning with a Learned Model”, et al 2021
-
“From Motor Control to Team Play in Simulated Humanoid Football”, et al 2021
-
“Open-Ended Learning Leads to Generally Capable Agents”, Open Ended Learning et al 2021; “Procedural Generalization by Planning with Self-Supervised World Models”, et al 2021
-
“Fictitious Co-Play: Collaborating with Humans without Human Data”, et al 2021
-
“Gato: A Generalist Agent”, et al 2022 (small Decision Transformer can learn >500 tasks; scaling smoothly)
-
“Multi-Game Decision Transformers”, et al 2022 (near-human offline single-checkpoint ALE agent with scaling & rapid transfer)
-
-
Theory:
-
“Does Learning Require Memorization? A Short Tale about a Long Tail”, 2019
-
“Generalization bounds for deep learning”, Valle-2020
-
“The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers”, et al 2020
-
“Explaining Neural Scaling Laws”, et al 2021
-
“Learning Curve Theory”, 2021 (Rohin Shah commentary; more on the manifold hypothesis)
-
“A mathematical theory of semantic development in deep neural networks”, et al 2019 (are jumps in NN capabilities to be expected when scaling? see also 2021’s discussion of phase transitions & averaging of exponentials giving power-laws, human “vocabulary spurts”, and “Acquisition of Chess Knowledge in AlphaZero”, et al 2021 §6 “Rapid increase of basic knowledge”); sequential learning in OpenFold
-
“A Farewell to the Bias-Variance Tradeoff? An Overview of the Theory of Overparameterized Machine Learning”, et al 2021
-
-
Historical:
-
“Toward A Universal Law Of Generalization For Psychological Science”, 1987
-
“Scaling to Very Very Large Corpora for Natural Language Disambiguation”, 2001
-
“Large Scale Online Learning”, Bottou & LeCun 200322ya (“We argue that suitably designed online learning algorithms asymptotically outperform any batch learning algorithm.”)
-
“Tree Induction vs. Logistic Regression: A Learning-Curve Analysis”, et al 2003
-
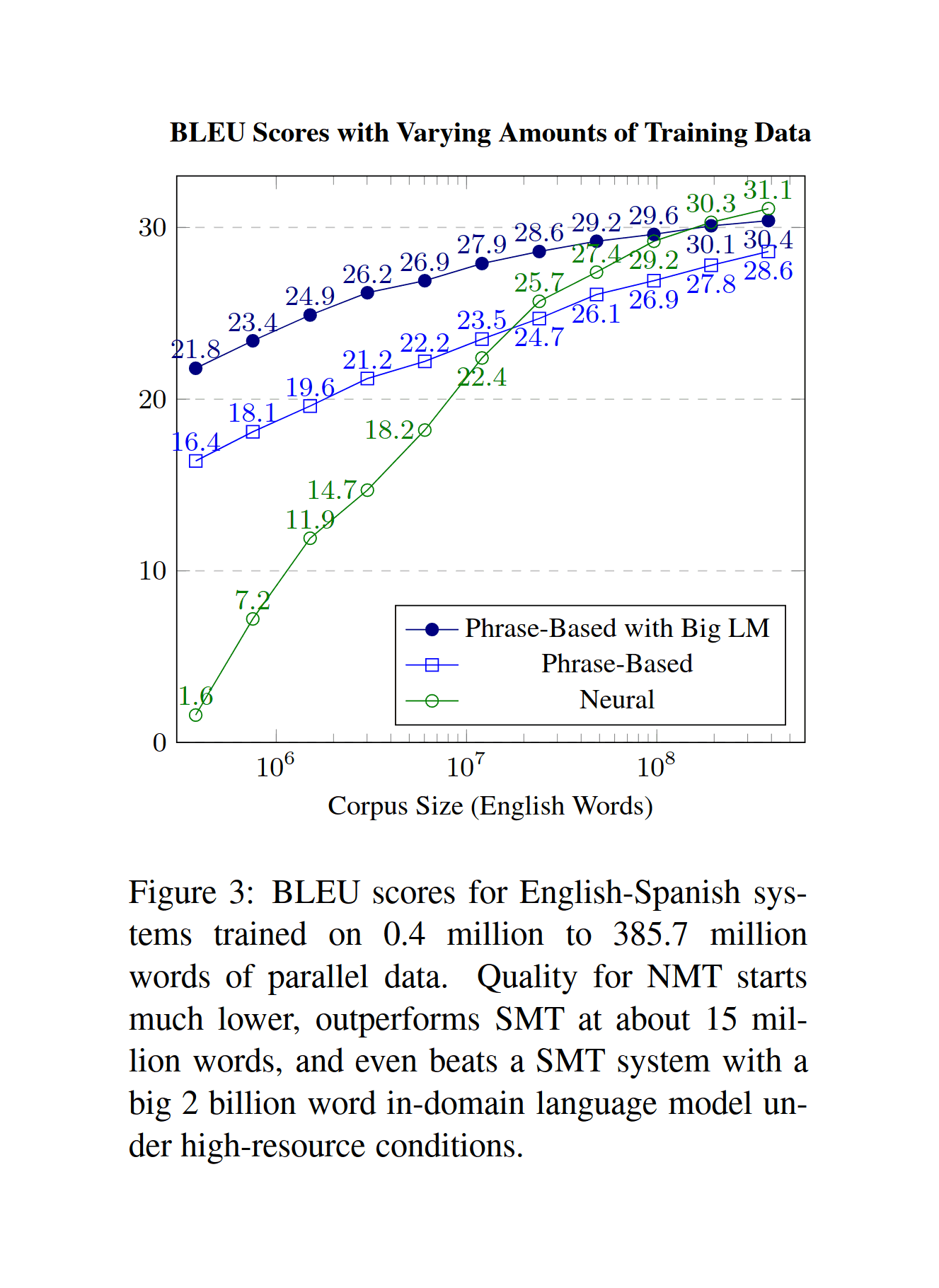
“Large Language Models in Machine Translation”, Brants et al 200718ya; 2017 (Figure 3)
-
“The Unreasonable Effectiveness of Data”, et al 2009
-
“The Tradeoffs of Large-Scale Learning”, Bottou & Bousquet 200718ya/201213ya; “Large-Scale Machine Learning Revisited [slides]”, 2013
-
-
See Also: For more ML scaling research, follow the /r/MLScaling subreddit; “It Looks Like You’re Trying To Take Over The World”
{kind=link}