‘Transformer’ tag
- See Also
-
Links
- “Learning to Move Like Professional Counter-Strike Players”, Durst et al 2024
- “Gemma 2: Improving Open Language Models at a Practical Size”, Riviere et al 2024
- “Investigating the Ability of LLMs to Recognize Their Own Writing”, Ackerman & Panickssery 2024
- “CARTE: toward Table Foundation Models”, Varoquaux 2024
- “Questionable Practices in Machine Learning”, Leech et al 2024
- “Revealing Fine-Grained Values and Opinions in Large Language Models”, Wright et al 2024
- “Linguistics-Based Formalization of the Antibody Language As a Basis for Antibody Language Models”, Vu et al 2024
- “BERTs Are Generative In-Context Learners”, Samuel 2024
- “Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks”, He et al 2024
- “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
- “Not All Language Model Features Are Linear”, Engels et al 2024
- “You Only Cache Once: Decoder-Decoder Architectures for Language Models”, Sun et al 2024
- “Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge”, Batsuren et al 2024
- “Chinchilla Scaling: A Replication Attempt”, Besiroglu et al 2024
- “Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?”, Jin et al 2024
- “Conformer-1: Robust ASR via Large-Scale Semi-Supervised Bootstrapping”, Zhang et al 2024
- “MiniCPM: Unveiling the Potential of Small Language Models With Scalable Training Strategies”, Hu et al 2024
- “Language Models Accurately Infer Correlations between Psychological Items and Scales from Text Alone”, Hommel & Arslan 2024
- “Privacy Backdoors: Stealing Data With Corrupted Pretrained Models”, Feng & Tramèr 2024
- “Language Models Learn Rare Phenomena from Less Rare Phenomena: The Case of the Missing AANNs”, Misra & Mahowald 2024
- “A Study in Dataset Pruning for Image Super-Resolution”, Moser et al 2024
- “AI and Memory Wall”, Gholami et al 2024
- “Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey”, Han et al 2024
- “Inflection-2.5: Meet the World’s Best Personal AI”, Inflection 2024
- “CARTE: Pretraining and Transfer for Tabular Learning”, Kim et al 2024
- “LTE: Training Neural Networks from Scratch With Parallel Low-Rank Adapters”, Huh et al 2024
- “Beyond A✱: Better Planning With Transformers via Search Dynamics Bootstrapping (Searchformer)”, Lehnert et al 2024
- “KARL: Knowledge-Aware Retrieval and Representations Aid Retention and Learning in Students”, Shu et al 2024
- “Do Llamas Work in English? On the Latent Language of Multilingual Transformers”, Wendler et al 2024
- “DE-COP: Detecting Copyrighted Content in Language Models Training Data”, Duarte et al 2024
- “Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift”, Qiu et al 2024
- “The Manga Whisperer: Automatically Generating Transcriptions for Comics”, Sachdeva & Zisserman 2024
- “A Philosophical Introduction to Language Models—Part I: Continuity With Classic Debates”, Millière & Buckner 2024
- “Solving Olympiad Geometry without Human Demonstrations”, Trinh et al 2024
- “Real-Time AI & The Future of AI Hardware”, Uberti 2023
- “Seamless: Multilingual Expressive and Streaming Speech Translation”, Communication et al 2023
- “Scaling Transformer Neural Networks for Skillful and Reliable Medium-Range Weather Forecasting”, Nguyen et al 2023
- “The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning”, Lin et al 2023
- “GIVT: Generative Infinite-Vocabulary Transformers”, Tschannen et al 2023
- “Sequential Modeling Enables Scalable Learning for Large Vision Models”, Bai et al 2023
- “DiLoCo: Distributed Low-Communication Training of Language Models”, Douillard et al 2023
- “CogVLM: Visual Expert for Pretrained Language Models”, Wang et al 2023
- “GLaMM: Pixel Grounding Large Multimodal Model”, Rasheed et al 2023
- “Don’t Make Your LLM an Evaluation Benchmark Cheater”, Zhou et al 2023
- “ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-Like Language Models”, Luo et al 2023
- “EELBERT: Tiny Models through Dynamic Embeddings”, Cohn et al 2023
- “LLM-FP4: 4-Bit Floating-Point Quantized Transformers”, Liu et al 2023
- “Will Releasing the Weights of Large Language Models Grant Widespread Access to Pandemic Agents?”, Gopal et al 2023
- “Model Merging by Uncertainty-Based Gradient Matching”, Daheim et al 2023
- “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
- “Sparse Universal Transformer”, Tan et al 2023
- “Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”, Xia et al 2023
- “Language Models Represent Space and Time”, Gurnee & Tegmark 2023
- “DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation”, Duan et al 2023
- “Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions”, Chebotar et al 2023
- “Demystifying RCE Vulnerabilities in LLM-Integrated Apps”, Liu et al 2023
- “A Pooled Cell Painting CRISPR Screening Platform Enables de Novo Inference of Gene Function by Self-Supervised Deep Learning”, Sivanandan et al 2023
- “Nougat: Neural Optical Understanding for Academic Documents”, Blecher et al 2023
- “SeamlessM4T: Massively Multilingual & Multimodal Machine Translation”, Communication et al 2023
- “Predicting Brain Activity Using Transformers”, Adeli et al 2023
- “Copy Is All You Need”, Lan et al 2023
- “HEADLINES: A Massive Scale Semantic Similarity Dataset of Historical English”, Silcock & Dell 2023
- “Expanding the Methodological Toolbox: Machine-Based Item Desirability Ratings As an Alternative to Human-Based Ratings”, Hommel 2023
- “OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents”, Laurençon et al 2023
- “RGD: Stochastic Re-Weighted Gradient Descent via Distributionally Robust Optimization”, Kumar et al 2023
- “SequenceMatch: Imitation Learning for Autoregressive Sequence Modeling With Backtracking”, Cundy & Ermon 2023
- “Using Sequences of Life-Events to Predict Human Lives”, Savcisens et al 2023
- “Binary and Ternary Natural Language Generation”, Liu et al 2023
- “AWQ: Activation-Aware Weight Quantization for LLM Compression and Acceleration”, Lin et al 2023
- “The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora With Web Data, and Web Data Only”, Penedo et al 2023
- “Learning Transformer Programs”, Friedman et al 2023
- “FERMAT: An Alternative to Accuracy for Numerical Reasoning”, Sivakumar & Moosavi 2023
- “Translatotron 3: Speech to Speech Translation With Monolingual Data”, Nachmani et al 2023
- “Deep Learning Based Forecasting: a Case Study from the Online Fashion Industry”, Kunz et al 2023
- “Scaling Laws for Language Encoding Models in FMRI”, Antonello et al 2023
- “DarkBERT: A Language Model for the Dark Side of the Internet”, Jin et al 2023
- “Mitigating Lies in Vision-Language Models”, Li et al 2023
- “VendorLink: An NLP Approach for Identifying & Linking Vendor Migrants & Potential Aliases on Darknet Markets”, Saxena et al 2023
- “Visual Instruction Tuning”, Liu et al 2023
- “Segment Anything”, Kirillov et al 2023
- “A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision”, Beyer et al 2023
- “When and How Artificial Intelligence Augments Employee Creativity”, Jia et al 2023
- “Trained on 100 Million Words and Still in Shape: BERT Meets British National Corpus”, Samuel et al 2023
- “Mitigating YouTube Recommendation Polarity Using BERT and K-Means Clustering”, Ahmad et al 2023
- “Model Scale versus Domain Knowledge in Statistical Forecasting of Chaotic Systems”, Gilpin 2023
- “Tag2Text: Guiding Vision-Language Model via Image Tagging”, Huang et al 2023
- “The Man of Your Dreams For $300, Replika Sells an AI Companion Who Will Never Die, Argue, or Cheat—Until His Algorithm Is Updated”, Singh-Kurtz 2023
- “Towards Democratizing Joint-Embedding Self-Supervised Learning”, Bordes et al 2023
- “MUX-PLMs: Pre-Training Language Models With Data Multiplexing”, Murahari et al 2023
- “Optical Transformers”, Anderson et al 2023
- “Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
- “BMT: Binarized Neural Machine Translation”, Zhang et al 2023
- “V1T: Large-Scale Mouse V1 Response Prediction Using a Vision Transformer”, Li et al 2023
- “The BabyLM Challenge: Sample-Efficient Pretraining on a Developmentally Plausible Corpus”, Warstadt et al 2023
- “SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient”, Ryabinin et al 2023
- “XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models”, Liang et al 2023
- “ClimaX: A Foundation Model for Weather and Climate”, Nguyen et al 2023
- “DataMUX: Data Multiplexing for Neural Networks”, Murahari et al 2023
- “Progress Measures for Grokking via Mechanistic Interpretability”, Nanda et al 2023
- “Scaling Laws for Generative Mixed-Modal Language Models”, Aghajanyan et al 2023
- “Vision Transformers Are Good Mask Auto-Labelers”, Lan et al 2023
- “Why Do Nearest Neighbor Language Models Work?”, Xu et al 2023
- “Cramming: Training a Language Model on a Single GPU in One Day”, Geiping & Goldstein 2022
- “Less Is More: Parameter-Free Text Classification With Gzip”, Jiang et al 2022
- “NBC-Softmax: Darkweb Author Fingerprinting and Migration Tracking”, Kulatilleke et al 2022
- “What Do Vision Transformers Learn? A Visual Exploration”, Ghiasi et al 2022
- “POM: A Principal Odor Map Unifies Diverse Tasks in Human Olfactory Perception”, Lee et al 2022
- “MAGVIT: Masked Generative Video Transformer”, Yu et al 2022
- “VindLU: A Recipe for Effective Video-And-Language Pretraining”, Cheng et al 2022
- “Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, Wang et al 2022
- “Discovering Latent Knowledge in Language Models Without Supervision”, Burns et al 2022
- “NPM: Nonparametric Masked Language Modeling”, Min et al 2022
- “BARTSmiles: Generative Masked Language Models for Molecular Representations”, Chilingaryan et al 2022
- “RGB No More: Minimally-Decoded JPEG Vision Transformers”, Park & Johnson 2022
- “Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models”, Henderson et al 2022
- “A Deep Learning and Digital Archaeology Approach for Mosquito Repellent Discovery”, Wei et al 2022
- “GENIUS: Sketch-Based Language Model Pre-Training via Extreme and Selective Masking for Text Generation and Augmentation”, Guo et al 2022
- “UniSumm: Unified Few-Shot Summarization With Multi-Task Pre-Training and Prefix-Tuning”, Chen et al 2022
- “Uni-Perceiver V2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks”, Li et al 2022
- “Distilled DeepConsensus: Knowledge Distillation for Fast and Accurate DNA Sequence Correction”, Belyaeva et al 2022
- “Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities”, Tjandra et al 2022
- “OneFormer: One Transformer to Rule Universal Image Segmentation”, Jain et al 2022
- “Characterizing Intrinsic Compositionality in Transformers With Tree Projections”, Murty et al 2022
- “Fast DistilBERT on CPUs”, Shen et al 2022
- “n-Gram Is Back: Residual Learning of Neural Text Generation With n-Gram Language Model”, Li et al 2022
- “Same Pre-Training Loss, Better Downstream: Implicit Bias Matters for Language Models”, Liu et al 2022
- “The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers”, Li et al 2022
- “Noise-Robust De-Duplication at Scale”, Silcock et al 2022
- “Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints”, Jawahar et al 2022
- “Improving Sample Quality of Diffusion Models Using Self-Attention Guidance”, Hong et al 2022
- “Semantic Scene Descriptions As an Objective of Human Vision”, Doerig et al 2022
- “SetFit: Efficient Few-Shot Learning Without Prompts”, Tunstall et al 2022
- “A Generalist Neural Algorithmic Learner”, Ibarz et al 2022
- “Machine Reading, Fast and Slow: When Do Models "Understand" Language?”, Choudhury et al 2022
- “On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)”, Rohanian et al 2022
- “Analyzing Transformers in Embedding Space”, Dar et al 2022
- “ASR2K: Speech Recognition for Around 2,000 Languages without Audio”, Li et al 2022
- “MeloForm: Generating Melody With Musical Form Based on Expert Systems and Neural Networks”, Lu et al 2022
- “CorpusBrain: Pre-Train a Generative Retrieval Model for Knowledge-Intensive Language Tasks”, Chen et al 2022
- “PatchDropout: Economizing Vision Transformers Using Patch Dropout”, Liu et al 2022
- “Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
- “Re2G: Retrieve, Rerank, Generate”, Glass et al 2022
- “Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling”, Nguyen & Grover 2022
- “TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data”, Hollmann et al 2022
- “Neural Networks and the Chomsky Hierarchy”, Delétang et al 2022
- “Do Loyal Users Enjoy Better Recommendations? Understanding Recommender Accuracy from a Time Perspective”, Ji et al 2022
- “Transfer Learning With Deep Tabular Models”, Levin et al 2022
- “BertNet: Harvesting Knowledge Graphs from Pretrained Language Models”, Hao et al 2022
- “ProGen2: Exploring the Boundaries of Protein Language Models”, Nijkamp et al 2022
- “SBERT Studies Meaning Representations: Decomposing Sentence Embeddings into Explainable Semantic Features”, Opitz & Frank 2022
- “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
- “LAVENDER: Unifying Video-Language Understanding As Masked Language Modeling”, Li et al 2022
- “Language Models Are General-Purpose Interfaces”, Hao et al 2022
- “Uni-Perceiver-MoE: Learning Sparse Generalist Models With Conditional MoEs”, Zhu et al 2022
- “Reconstructing the Cascade of Language Processing in the Brain Using the Internal Computations of a Transformer-Based Language Model”, Kumar et al 2022
- “A Neural Corpus Indexer for Document Retrieval”, Wang et al 2022
- “XTC: Extreme Compression for Pre-Trained Transformers Made Simple and Efficient”, Wu et al 2022
- “Toward a Realistic Model of Speech Processing in the Brain With Self-Supervised Learning”, Millet et al 2022
- “Text2Human: Text-Driven Controllable Human Image Generation”, Jiang et al 2022
- “Anime Character Recognition Using Intermediate Features Aggregation”, Rios et al 2022
- “Towards Learning Universal Hyperparameter Optimizers With Transformers”, Chen et al 2022
- “FLEURS: Few-Shot Learning Evaluation of Universal Representations of Speech”, Conneau et al 2022
- “HTPS: HyperTree Proof Search for Neural Theorem Proving”, Lample et al 2022
- “On the Paradox of Learning to Reason from Data”, Zhang et al 2022
- “Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
- “UViM: A Unified Modeling Approach for Vision With Learned Guiding Codes”, Kolesnikov et al 2022
- “Tradformer: A Transformer Model of Traditional Music Transcriptions”, Casini & Sturm 2022
- “Continual Pre-Training Mitigates Forgetting in Language and Vision”, Cossu et al 2022
- “PLAID: An Efficient Engine for Late Interaction Retrieval”, Santhanam et al 2022
- “Few-Shot Parameter-Efficient Fine-Tuning Is Better and Cheaper Than In-Context Learning”, Liu et al 2022
- “SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
- “When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”, Vasudevan et al 2022
- “A Challenging Benchmark of Anime Style Recognition”, Li et al 2022
- “Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
- “Masked Siamese Networks for Label-Efficient Learning”, Assran et al 2022
- “DualPrompt: Complementary Prompting for Rehearsal-Free Continual Learning”, Wang et al 2022
- “Language Models That Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion”, Shuster et al 2022
- “On Embeddings for Numerical Features in Tabular Deep Learning”, Gorishniy et al 2022
- “In-Context Learning and Induction Heads”, Olsson et al 2022
- “LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models”, Javaheripi et al 2022
- “Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words”, Feng et al 2022
- “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-To-Sequence Learning Framework”, Wang et al 2022
- “TACTiS: Transformer-Attentional Copulas for Time Series”, Drouin et al 2022
- “AutoDistil: Few-Shot Task-Agnostic Neural Architecture Search for Distilling Large Language Models”, Xu et al 2022
- “FIGARO: Generating Symbolic Music With Fine-Grained Artistic Control”, Rütte et al 2022
- “Robust Contrastive Learning against Noisy Views”, Chuang et al 2022
- “HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning”, Zhmoginov et al 2022
- “A Mathematical Framework for Transformer Circuits”, Elhage et al 2021
- “PFNs: Transformers Can Do Bayesian Inference”, Müller et al 2021
- “XGLM: Few-Shot Learning With Multilingual Language Models”, Lin et al 2021
- “An Empirical Investigation of the Role of Pre-Training in Lifelong Learning”, Mehta et al 2021
- “AI Improvements in Chemical Calculations”, Lowe 2021
- “You Only Need One Model for Open-Domain Question Answering”, Lee et al 2021
- “Human Parity on CommonsenseQA: Augmenting Self-Attention With External Attention”, Xu et al 2021
- “ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction”, Santhanam et al 2021
- “Uni-Perceiver: Pre-Training Unified Architecture for Generic Perception for Zero-Shot and Few-Shot Tasks”, Zhu et al 2021
- “Inducing Causal Structure for Interpretable Neural Networks (IIT)”, Geiger et al 2021
- “OCR-Free Document Understanding Transformer”, Kim et al 2021
- “FQ-ViT: Fully Quantized Vision Transformer without Retraining”, Lin et al 2021
- “Semi-Supervised Music Tagging Transformer”, Won et al 2021
- “LEMON: Scaling Up Vision-Language Pre-Training for Image Captioning”, Hu et al 2021
- “UNICORN: Crossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling”, Yang et al 2021
- “Compositional Transformers for Scene Generation”, Hudson & Zitnick 2021
- “It’s About Time: Analog Clock Reading in the Wild”, Yang et al 2021
- “XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale”, Babu et al 2021
- “A Survey of Visual Transformers”, Liu et al 2021
- “Improving Visual Quality of Image Synthesis by A Token-Based Generator With Transformers”, Zeng et al 2021
- “The Efficiency Misnomer”, Dehghani et al 2021
- “STransGAN: An Empirical Study on Transformer in GANs”, Xu et al 2021
- “Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora”, Jin et al 2021
- “The Dangers of Underclaiming: Reasons for Caution When Reporting How NLP Systems Fail”, Bowman 2021
- “Palette: Image-To-Image Diffusion Models”, Saharia et al 2021
- “Transformers Are Meta-Reinforcement Learners”, Anonymous 2021
- “Autoregressive Latent Video Prediction With High-Fidelity Image Generator”, Seo et al 2021
- “Skill Induction and Planning With Latent Language”, Sharma et al 2021
- “Text2Brain: Synthesis of Brain Activation Maps from Free-Form Text Query”, Ngo et al 2021
- “Understanding and Overcoming the Challenges of Efficient Transformer Quantization”, Bondarenko et al 2021
- “BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition”, Zhang et al 2021
- “TrOCR: Transformer-Based Optical Character Recognition With Pre-Trained Models”, Li et al 2021
- “MeLT: Message-Level Transformer With Masked Document Representations As Pre-Training for Stance Detection”, Matero et al 2021
- “KroneckerBERT: Learning Kronecker Decomposition for Pre-Trained Language Models via Knowledge Distillation”, Tahaei et al 2021
- “Block Pruning For Faster Transformers”, Lagunas et al 2021
- “The Sensory Neuron As a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning”, Tang & Ha 2021
- “DeepConsensus: Gap-Aware Sequence Transformers for Sequence Correction”, Baid et al 2021
- “A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, Zhao et al 2021
- “Data and Parameter Scaling Laws for Neural Machine Translation”, Gordon et al 2021
- “ImageBART: Bidirectional Context With Multinomial Diffusion for Autoregressive Image Synthesis”, Esser et al 2021
- “Modeling Protein Using Large-Scale Pretrain Language Model”, Xiao et al 2021
- “Billion-Scale Pretraining With Vision Transformers for Multi-Task Visual Representations”, Beal et al 2021
- “EVA: An Open-Domain Chinese Dialogue System With Large-Scale Generative Pre-Training”, Zhou et al 2021
- “Internet-Augmented Dialogue Generation”, Komeili et al 2021
- “HTLM: Hyper-Text Pre-Training and Prompting of Language Models”, Aghajanyan et al 2021
- “SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking”, Formal et al 2021
- “ViTGAN: Training GANs With Vision Transformers”, Lee et al 2021
- “ARM-Net: Adaptive Relation Modeling Network for Structured Data”, Cai et al 2021
- “SCARF: Self-Supervised Contrastive Learning Using Random Feature Corruption”, Bahri et al 2021
- “Charformer: Fast Character Transformers via Gradient-Based Subword Tokenization”, Tay et al 2021
- “BitFit: Simple Parameter-Efficient Fine-Tuning for Transformer-Based Masked Language-Models”, Zaken et al 2021
- “Revisiting the Calibration of Modern Neural Networks”, Minderer et al 2021
- “Scaling Laws for Acoustic Models”, Droppo & Elibol 2021
- “CoAtNet: Marrying Convolution and Attention for All Data Sizes”, Dai et al 2021
- “Chasing Sparsity in Vision Transformers: An End-To-End Exploration”, Chen et al 2021
- “Tabular Data: Deep Learning Is Not All You Need”, Shwartz-Ziv & Armon 2021
- “Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning”, Kossen et al 2021
- “Exploring Transfer Learning Techniques for Named Entity Recognition in Noisy User-Generated Text”, Bogensperger 2021
- “SegFormer: Simple and Efficient Design for Semantic Segmentation With Transformers”, Xie et al 2021
- “Maximizing 3-D Parallelism in Distributed Training for Huge Neural Networks”, Bian et al 2021
- “One4all User Representation for Recommender Systems in E-Commerce”, Shin et al 2021
- “QASPER: A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers”, Dasigi et al 2021
- “MathBERT: A Pre-Trained Model for Mathematical Formula Understanding”, Peng et al 2021
- “MDETR—Modulated Detection for End-To-End Multi-Modal Understanding”, Kamath et al 2021
- “XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond”, Barbieri et al 2021
- “[Ali Released PLUG: 27 Billion Parameters, the Largest Pre-Trained Language Model in the Chinese Community]”, Yuying 2021
- “SimCSE: Simple Contrastive Learning of Sentence Embeddings”, Gao et al 2021
- “Robust Open-Vocabulary Translation from Visual Text Representations”, Salesky et al 2021
- “Memorization versus Generalization in Pre-Trained Language Models”, Tänzer et al 2021
- “Retrieval Augmentation Reduces Hallucination in Conversation”, Shuster et al 2021
- “Gradient-Based Adversarial Attacks against Text Transformers”, Guo et al 2021
- “TSDAE: Using Transformer-Based Sequential Denoising Autoencoder for Unsupervised Sentence Embedding Learning”, Wang et al 2021
- “Machine Translation Decoding beyond Beam Search”, Leblond et al 2021
- “An Empirical Study of Training Self-Supervised Vision Transformers”, Chen et al 2021
- “ChinAI #137: Year 3 of ChinAI: Reflections on the Newsworthiness of Machine Translation”, Ding 2021
- “GPV-1: Towards General Purpose Vision Systems”, Gupta et al 2021
- “DeepViT: Towards Deeper Vision Transformer”, Zhou et al 2021
- “ConViT: Improving Vision Transformers With Soft Convolutional Inductive Biases”, d’Ascoli et al 2021
- “Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
- “Learning from Videos to Understand the World”, Zweig et al 2021
- “Are NLP Models Really Able to Solve Simple Math Word Problems?”, Patel et al 2021
- “CANINE: Pre-Training an Efficient Tokenization-Free Encoder for Language Representation”, Clark et al 2021
- “TransGAN: Two Transformers Can Make One Strong GAN”, Jiang et al 2021
- “Baller2vec: A Multi-Entity Transformer For Multi-Agent Spatiotemporal Modeling”, Alcorn & Nguyen 2021
- “ViLT: Vision-And-Language Transformer Without Convolution or Region Supervision”, Kim et al 2021
- “Video Transformer Network”, Neimark et al 2021
- “Tokens-To-Token ViT: Training Vision Transformers from Scratch on ImageNet”, Yuan et al 2021
- “BENDR: Using Transformers and a Contrastive Self-Supervised Learning Task to Learn from Massive Amounts of EEG Data”, Kostas et al 2021
- “Bottleneck Transformers for Visual Recognition”, Srinivas et al 2021
- “DAF:re: A Challenging, Crowd-Sourced, Large-Scale, Long-Tailed Dataset For Anime Character Recognition”, Rios et al 2021
- “UPDeT: Universal Multi-Agent Reinforcement Learning via Policy Decoupling With Transformers”, Hu et al 2021
- “MSR-VTT: A Large Video Description Dataset for Bridging Video and Language”, Xu et al 2021
- “XMC-GAN: Cross-Modal Contrastive Learning for Text-To-Image Generation”, Zhang et al 2021
- “Superbizarre Is Not Superb: Derivational Morphology Improves BERT’s Interpretation of Complex Words”, Hofmann et al 2021
- “Training Data-Efficient Image Transformers & Distillation through Attention”, Touvron et al 2020
- “VQ-GAN: Taming Transformers for High-Resolution Image Synthesis”, Esser et al 2020
- “Object-Based Attention for Spatio-Temporal Reasoning: Outperforming Neuro-Symbolic Models With Flexible Distributed Architectures”, Ding et al 2020
- “Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences”, Rives et al 2020
- “Progressively Stacking 2.0: A Multi-Stage Layerwise Training Method for BERT Training Speedup”, Yang et al 2020
- “TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game”, Han et al 2020
- “A Recurrent Vision-And-Language BERT for Navigation”, Hong et al 2020
- “A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
- “CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters”, Boukkouri et al 2020
- “TernaryBERT: Distillation-Aware Ultra-Low Bit BERT”, Zhang et al 2020
- “Weird AI Yankovic: Generating Parody Lyrics”, Riedl 2020
- “It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners”, Schick & Schütze 2020
- “DeepSpeed: Extreme-Scale Model Training for Everyone”, Team et al 2020
- “Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing”, Gu et al 2020
- “CoVoST 2 and Massively Multilingual Speech-To-Text Translation”, Wang et al 2020
- “Modern Hopfield Networks and Attention for Immune Repertoire Classification”, Widrich et al 2020
- “Hopfield Networks Is All You Need”, Ramsauer et al 2020
- “Can Neural Networks Acquire a Structural Bias from Raw Linguistic Data?”, Warstadt & Bowman 2020
- “DeepSinger: Singing Voice Synthesis With Data Mined From the Web”, Ren et al 2020
- “Data Movement Is All You Need: A Case Study on Optimizing Transformers”, Ivanov et al 2020
- “Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations”, Baevski et al 2020
- “PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training”, Narayanan et al 2020
- “Learning to Learn With Feedback and Local Plasticity”, Lindsey & Litwin-Kumar 2020
- “Improving GAN Training With Probability Ratio Clipping and Sample Reweighting”, Wu et al 2020
- “DeBERTa: Decoding-Enhanced BERT With Disentangled Attention”, He et al 2020
- “DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations”, Giorgi et al 2020
- “DETR: End-To-End Object Detection With Transformers”, Carion et al 2020
- “Open-Retrieval Conversational Question Answering”, Qu et al 2020
- “TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data”, Yin et al 2020
- “ForecastQA: A Question Answering Challenge for Event Forecasting With Temporal Text Data”, Jin et al 2020
- “Can Multilingual Language Models Transfer to an Unseen Dialect? A Case Study on North African Arabizi”, Muller et al 2020
- “VLN-BERT: Improving Vision-And-Language Navigation With Image-Text Pairs from the Web”, Majumdar et al 2020
- “Blender: A State-Of-The-Art Open Source Chatbot”, Roller et al 2020
- “General Purpose Text Embeddings from Pre-Trained Language Models for Scalable Inference”, Du et al 2020
- “Recipes for Building an Open-Domain Chatbot”, Roller et al 2020
- “Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks”, Gururangan et al 2020
- “On the Effect of Dropping Layers of Pre-Trained Transformer Models”, Sajjad et al 2020
- “Rapformer: Conditional Rap Lyrics Generation With Denoising Autoencoders”, Nikolov et al 2020
- “TAPAS: Weakly Supervised Table Parsing via Pre-Training”, Herzig et al 2020
- “A Hundred Visions and Revisions”, Binder 2020
- “Rethinking Parameter Counting in Deep Models: Effective Dimensionality Revisited”, Maddox et al 2020
- “AraBERT: Transformer-Based Model for Arabic Language Understanding”, Antoun et al 2020
- “MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”, Wang et al 2020
- “GNS: Learning to Simulate Complex Physics With Graph Networks”, Sanchez-Gonzalez et al 2020
- “Do We Need Zero Training Loss After Achieving Zero Training Error?”, Ishida et al 2020
- “Bayesian Deep Learning and a Probabilistic Perspective of Generalization”, Wilson & Izmailov 2020
- “Transformers As Soft Reasoners over Language”, Clark et al 2020
- “Towards a Conversational Agent That Can Chat About…Anything”, Adiwardana & Luong 2020
- “Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference”, Schick & Schütze 2020
- “Improving Transformer Optimization Through Better Initialization”, Huang 2020
- “VIME: Extending the Success of Self-Supervised and Semi-Supervised Learning to Tabular Domain”, Yoon et al 2020
- “Measuring Compositional Generalization: A Comprehensive Method on Realistic Data”, Keysers et al 2019
- “Mastering Complex Control in MOBA Games With Deep Reinforcement Learning”, Ye et al 2019
- “PEGASUS: Pre-Training With Extracted Gap-Sentences for Abstractive Summarization”, Zhang et al 2019
- “Encoding Musical Style With Transformer Autoencoders”, Choi et al 2019
- “Deep Double Descent: We Show That the Double Descent Phenomenon Occurs in CNNs, ResNets, and Transformers: Performance First Improves, Then Gets Worse, and Then Improves Again With Increasing Model Size, Data Size, or Training Time”, Nakkiran et al 2019
- “Detecting GAN Generated Errors”, Zhu et al 2019
- “SimpleBooks: Long-Term Dependency Book Dataset With Simplified English Vocabulary for Word-Level Language Modeling”, Nguyen 2019
- “Unsupervised Cross-Lingual Representation Learning at Scale”, Conneau et al 2019
- “DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter”, Sanh et al 2019
- “TinyBERT: Distilling BERT for Natural Language Understanding”, Jiao et al 2019
- “Do NLP Models Know Numbers? Probing Numeracy in Embeddings”, Wallace et al 2019
- “PubMedQA: A Dataset for Biomedical Research Question Answering”, Jin et al 2019
- “Frustratingly Easy Natural Question Answering”, Pan et al 2019
- “Distributionally Robust Language Modeling”, Oren et al 2019
- “Language Models As Knowledge Bases?”, Petroni et al 2019
- “Encode, Tag, Realize: High-Precision Text Editing”, Malmi et al 2019
- “Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks”, Reimers & Gurevych 2019
- “Well-Read Students Learn Better: On the Importance of Pre-Training Compact Models”, Turc et al 2019
- “TabNet: Attentive Interpretable Tabular Learning”, Arik & Pfister 2019
- “StructBERT: Incorporating Language Structures into Pre-Training for Deep Language Understanding”, Wang et al 2019
- “What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models”, Ettinger 2019
- “RoBERTa: A Robustly Optimized BERT Pretraining Approach”, Liu et al 2019
- “Theoretical Limitations of Self-Attention in Neural Sequence Models”, Hahn 2019
- “Energy and Policy Considerations for Deep Learning in NLP”, Strubell et al 2019
- “Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned”, Voita et al 2019
- “HellaSwag: Can a Machine Really Finish Your Sentence?”, Zellers et al 2019
- “UniLM: Unified Language Model Pre-Training for Natural Language Understanding and Generation”, Dong et al 2019
- “MASS: Masked Sequence to Sequence Pre-Training for Language Generation”, Song et al 2019
- “Mask-Predict: Parallel Decoding of Conditional Masked Language Models”, Ghazvininejad et al 2019
- “Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes”, You et al 2019
- “LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game”, Urbanek et al 2019
- “Insertion Transformer: Flexible Sequence Generation via Insertion Operations”, Stern et al 2019
- “Adapter: Parameter-Efficient Transfer Learning for NLP”, Houlsby et al 2019
- “Learning and Evaluating General Linguistic Intelligence”, Yogatama et al 2019
- “BioBERT: a Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining”, Lee et al 2019
- “Efficient Training of BERT by Progressively Stacking”, Gong et al 2019
- “Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
- “Blockwise Parallel Decoding for Deep Autoregressive Models”, Stern et al 2018
- “Object Hallucination in Image Captioning”, Rohrbach et al 2018
- “Self-Attention Generative Adversarial Networks”, Zhang et al 2018
- “Universal Sentence Encoder”, Cer et al 2018
- “Self-Attention With Relative Position Representations”, Shaw et al 2018
- “Learning Longer-Term Dependencies in RNNs With Auxiliary Losses”, Trinh et al 2018
- “Generating Structured Music through Self-Attention”, Huang et al 2018
- “GPipe: Easy Scaling With Micro-Batch Pipeline Parallelism § Pg4”, Huang 2018 (page 4 org google)
- “A Simple Neural Attentive Meta-Learner”, Mishra et al 2017
- “Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer”, Zagoruyko & Komodakis 2016
- “QRNNs: Quasi-Recurrent Neural Networks”, Bradbury et al 2016
- “Gaussian Error Linear Units (GELUs)”, Hendrycks & Gimpel 2016
- “Pointer Networks”, Vinyals et al 2015
- “No Physics? No Problem. AI Weather Forecasting Is Already Making Huge Strides.”
-
“Huggingface:
transformersRepo”, Huggingface 2025 - “Transformers in Vision”
- “The Illustrated GPT-2 (Visualizing Transformer Language Models)”
- “The Illustrated Transformer”
- “Autoregressive Long-Context Music Generation With Perceiver AR”
- “The Transformer—Attention Is All You Need.”
- “Understanding BERT Transformer: Attention Isn’t All You Need”, Sileo 2025
- “Caglar Gulcehre Homepage”, Gulcehre 2025
- “Etched Is Making the Biggest Bet in AI”
- “Was Linguistic A.I. Created by Accident?”
- “Transformers Are a Very Exciting Family of Machine Learning Architectures”, Bloem 2025
- Sort By Magic
- Wikipedia
- Miscellaneous
- Bibliography
See Also
Links
“Learning to Move Like Professional Counter-Strike Players”, Durst et al 2024
“Gemma 2: Improving Open Language Models at a Practical Size”, Riviere et al 2024
“Investigating the Ability of LLMs to Recognize Their Own Writing”, Ackerman & Panickssery 2024
Investigating the Ability of LLMs to Recognize Their Own Writing
“CARTE: toward Table Foundation Models”, Varoquaux 2024
“Questionable Practices in Machine Learning”, Leech et al 2024
“Revealing Fine-Grained Values and Opinions in Large Language Models”, Wright et al 2024
Revealing Fine-Grained Values and Opinions in Large Language Models
“Linguistics-Based Formalization of the Antibody Language As a Basis for Antibody Language Models”, Vu et al 2024
Linguistics-based formalization of the antibody language as a basis for antibody language models
“BERTs Are Generative In-Context Learners”, Samuel 2024
“Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks”, He et al 2024
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
“Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
“Not All Language Model Features Are Linear”, Engels et al 2024
“You Only Cache Once: Decoder-Decoder Architectures for Language Models”, Sun et al 2024
You Only Cache Once: Decoder-Decoder Architectures for Language Models
“Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge”, Batsuren et al 2024
Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge
“Chinchilla Scaling: A Replication Attempt”, Besiroglu et al 2024
“Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?”, Jin et al 2024
Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
“Conformer-1: Robust ASR via Large-Scale Semi-Supervised Bootstrapping”, Zhang et al 2024
Conformer-1: Robust ASR via Large-Scale Semi-supervised Bootstrapping
“MiniCPM: Unveiling the Potential of Small Language Models With Scalable Training Strategies”, Hu et al 2024
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
“Language Models Accurately Infer Correlations between Psychological Items and Scales from Text Alone”, Hommel & Arslan 2024
Language models accurately infer correlations between psychological items and scales from text alone
“Privacy Backdoors: Stealing Data With Corrupted Pretrained Models”, Feng & Tramèr 2024
Privacy Backdoors: Stealing Data with Corrupted Pretrained Models
“Language Models Learn Rare Phenomena from Less Rare Phenomena: The Case of the Missing AANNs”, Misra & Mahowald 2024
Language Models Learn Rare Phenomena from Less Rare Phenomena: The Case of the Missing AANNs
“A Study in Dataset Pruning for Image Super-Resolution”, Moser et al 2024
“AI and Memory Wall”, Gholami et al 2024
“Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey”, Han et al 2024
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
“Inflection-2.5: Meet the World’s Best Personal AI”, Inflection 2024
“CARTE: Pretraining and Transfer for Tabular Learning”, Kim et al 2024
“LTE: Training Neural Networks from Scratch With Parallel Low-Rank Adapters”, Huh et al 2024
LTE: Training Neural Networks from Scratch with Parallel Low-Rank Adapters
“Beyond A✱: Better Planning With Transformers via Search Dynamics Bootstrapping (Searchformer)”, Lehnert et al 2024
Beyond A✱: Better Planning with Transformers via Search Dynamics Bootstrapping (Searchformer)
“KARL: Knowledge-Aware Retrieval and Representations Aid Retention and Learning in Students”, Shu et al 2024
KARL: Knowledge-Aware Retrieval and Representations aid Retention and Learning in Students
“Do Llamas Work in English? On the Latent Language of Multilingual Transformers”, Wendler et al 2024
Do Llamas Work in English? On the Latent Language of Multilingual Transformers
“DE-COP: Detecting Copyrighted Content in Language Models Training Data”, Duarte et al 2024
DE-COP: Detecting Copyrighted Content in Language Models Training Data
“Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift”, Qiu et al 2024
Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift
“The Manga Whisperer: Automatically Generating Transcriptions for Comics”, Sachdeva & Zisserman 2024
The Manga Whisperer: Automatically Generating Transcriptions for Comics
“A Philosophical Introduction to Language Models—Part I: Continuity With Classic Debates”, Millière & Buckner 2024
A Philosophical Introduction to Language Models—Part I: Continuity With Classic Debates
“Solving Olympiad Geometry without Human Demonstrations”, Trinh et al 2024
“Real-Time AI & The Future of AI Hardware”, Uberti 2023
“Seamless: Multilingual Expressive and Streaming Speech Translation”, Communication et al 2023
Seamless: Multilingual Expressive and Streaming Speech Translation
“Scaling Transformer Neural Networks for Skillful and Reliable Medium-Range Weather Forecasting”, Nguyen et al 2023
Scaling transformer neural networks for skillful and reliable medium-range weather forecasting
“The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning”, Lin et al 2023
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
“GIVT: Generative Infinite-Vocabulary Transformers”, Tschannen et al 2023
“Sequential Modeling Enables Scalable Learning for Large Vision Models”, Bai et al 2023
Sequential Modeling Enables Scalable Learning for Large Vision Models
“DiLoCo: Distributed Low-Communication Training of Language Models”, Douillard et al 2023
DiLoCo: Distributed Low-Communication Training of Language Models
“CogVLM: Visual Expert for Pretrained Language Models”, Wang et al 2023
“GLaMM: Pixel Grounding Large Multimodal Model”, Rasheed et al 2023
“Don’t Make Your LLM an Evaluation Benchmark Cheater”, Zhou et al 2023
“ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-Like Language Models”, Luo et al 2023
ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-like Language Models
“EELBERT: Tiny Models through Dynamic Embeddings”, Cohn et al 2023
“LLM-FP4: 4-Bit Floating-Point Quantized Transformers”, Liu et al 2023
“Will Releasing the Weights of Large Language Models Grant Widespread Access to Pandemic Agents?”, Gopal et al 2023
Will releasing the weights of large language models grant widespread access to pandemic agents?
“Model Merging by Uncertainty-Based Gradient Matching”, Daheim et al 2023
“To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
“Sparse Universal Transformer”, Tan et al 2023
“Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”, Xia et al 2023
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
“Language Models Represent Space and Time”, Gurnee & Tegmark 2023
“DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation”, Duan et al 2023
DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation
“Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions”, Chebotar et al 2023
Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
“Demystifying RCE Vulnerabilities in LLM-Integrated Apps”, Liu et al 2023
“A Pooled Cell Painting CRISPR Screening Platform Enables de Novo Inference of Gene Function by Self-Supervised Deep Learning”, Sivanandan et al 2023
“Nougat: Neural Optical Understanding for Academic Documents”, Blecher et al 2023
“SeamlessM4T: Massively Multilingual & Multimodal Machine Translation”, Communication et al 2023
SeamlessM4T: Massively Multilingual & Multimodal Machine Translation
“Predicting Brain Activity Using Transformers”, Adeli et al 2023
“Copy Is All You Need”, Lan et al 2023
“HEADLINES: A Massive Scale Semantic Similarity Dataset of Historical English”, Silcock & Dell 2023
HEADLINES: A Massive Scale Semantic Similarity Dataset of Historical English
“Expanding the Methodological Toolbox: Machine-Based Item Desirability Ratings As an Alternative to Human-Based Ratings”, Hommel 2023
“OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents”, Laurençon et al 2023
OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
“RGD: Stochastic Re-Weighted Gradient Descent via Distributionally Robust Optimization”, Kumar et al 2023
RGD: Stochastic Re-weighted Gradient Descent via Distributionally Robust Optimization
“SequenceMatch: Imitation Learning for Autoregressive Sequence Modeling With Backtracking”, Cundy & Ermon 2023
SequenceMatch: Imitation Learning for Autoregressive Sequence Modeling with Backtracking
“Using Sequences of Life-Events to Predict Human Lives”, Savcisens et al 2023
“Binary and Ternary Natural Language Generation”, Liu et al 2023
“AWQ: Activation-Aware Weight Quantization for LLM Compression and Acceleration”, Lin et al 2023
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
“The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora With Web Data, and Web Data Only”, Penedo et al 2023
“Learning Transformer Programs”, Friedman et al 2023
“FERMAT: An Alternative to Accuracy for Numerical Reasoning”, Sivakumar & Moosavi 2023
“Translatotron 3: Speech to Speech Translation With Monolingual Data”, Nachmani et al 2023
Translatotron 3: Speech to Speech Translation with Monolingual Data
“Deep Learning Based Forecasting: a Case Study from the Online Fashion Industry”, Kunz et al 2023
Deep Learning based Forecasting: a case study from the online fashion industry
“Scaling Laws for Language Encoding Models in FMRI”, Antonello et al 2023
“DarkBERT: A Language Model for the Dark Side of the Internet”, Jin et al 2023
DarkBERT: A Language Model for the Dark Side of the Internet
“Mitigating Lies in Vision-Language Models”, Li et al 2023
“VendorLink: An NLP Approach for Identifying & Linking Vendor Migrants & Potential Aliases on Darknet Markets”, Saxena et al 2023
“Visual Instruction Tuning”, Liu et al 2023
“Segment Anything”, Kirillov et al 2023
“A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision”, Beyer et al 2023
A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
“When and How Artificial Intelligence Augments Employee Creativity”, Jia et al 2023
When and How Artificial Intelligence Augments Employee Creativity
“Trained on 100 Million Words and Still in Shape: BERT Meets British National Corpus”, Samuel et al 2023
Trained on 100 million words and still in shape: BERT meets British National Corpus
“Mitigating YouTube Recommendation Polarity Using BERT and K-Means Clustering”, Ahmad et al 2023
Mitigating YouTube Recommendation Polarity using BERT and K-Means Clustering
“Model Scale versus Domain Knowledge in Statistical Forecasting of Chaotic Systems”, Gilpin 2023
Model scale versus domain knowledge in statistical forecasting of chaotic systems
“Tag2Text: Guiding Vision-Language Model via Image Tagging”, Huang et al 2023
“The Man of Your Dreams For $300, Replika Sells an AI Companion Who Will Never Die, Argue, or Cheat—Until His Algorithm Is Updated”, Singh-Kurtz 2023
“Towards Democratizing Joint-Embedding Self-Supervised Learning”, Bordes et al 2023
Towards Democratizing Joint-Embedding Self-Supervised Learning
“MUX-PLMs: Pre-Training Language Models With Data Multiplexing”, Murahari et al 2023
MUX-PLMs: Pre-training Language Models with Data Multiplexing
“Optical Transformers”, Anderson et al 2023
“Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
“BMT: Binarized Neural Machine Translation”, Zhang et al 2023
“V1T: Large-Scale Mouse V1 Response Prediction Using a Vision Transformer”, Li et al 2023
V1T: large-scale mouse V1 response prediction using a Vision Transformer
“The BabyLM Challenge: Sample-Efficient Pretraining on a Developmentally Plausible Corpus”, Warstadt et al 2023
The BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
“SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient”, Ryabinin et al 2023
SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient
“XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models”, Liang et al 2023
XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models
“ClimaX: A Foundation Model for Weather and Climate”, Nguyen et al 2023
“DataMUX: Data Multiplexing for Neural Networks”, Murahari et al 2023
“Progress Measures for Grokking via Mechanistic Interpretability”, Nanda et al 2023
Progress measures for grokking via mechanistic interpretability
“Scaling Laws for Generative Mixed-Modal Language Models”, Aghajanyan et al 2023
“Vision Transformers Are Good Mask Auto-Labelers”, Lan et al 2023
“Why Do Nearest Neighbor Language Models Work?”, Xu et al 2023
“Cramming: Training a Language Model on a Single GPU in One Day”, Geiping & Goldstein 2022
Cramming: Training a Language Model on a Single GPU in One Day
“Less Is More: Parameter-Free Text Classification With Gzip”, Jiang et al 2022
“NBC-Softmax: Darkweb Author Fingerprinting and Migration Tracking”, Kulatilleke et al 2022
NBC-Softmax: Darkweb Author fingerprinting and migration tracking
“What Do Vision Transformers Learn? A Visual Exploration”, Ghiasi et al 2022
“POM: A Principal Odor Map Unifies Diverse Tasks in Human Olfactory Perception”, Lee et al 2022
POM: A Principal Odor Map Unifies Diverse Tasks in Human Olfactory Perception
“MAGVIT: Masked Generative Video Transformer”, Yu et al 2022
“VindLU: A Recipe for Effective Video-And-Language Pretraining”, Cheng et al 2022
VindLU: A Recipe for Effective Video-and-Language Pretraining
“Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, Wang et al 2022
Text Embeddings by Weakly-Supervised Contrastive Pre-training
“Discovering Latent Knowledge in Language Models Without Supervision”, Burns et al 2022
Discovering Latent Knowledge in Language Models Without Supervision
“NPM: Nonparametric Masked Language Modeling”, Min et al 2022
“BARTSmiles: Generative Masked Language Models for Molecular Representations”, Chilingaryan et al 2022
BARTSmiles: Generative Masked Language Models for Molecular Representations
“RGB No More: Minimally-Decoded JPEG Vision Transformers”, Park & Johnson 2022
“Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models”, Henderson et al 2022
Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models
“A Deep Learning and Digital Archaeology Approach for Mosquito Repellent Discovery”, Wei et al 2022
A deep learning and digital archaeology approach for mosquito repellent discovery
“GENIUS: Sketch-Based Language Model Pre-Training via Extreme and Selective Masking for Text Generation and Augmentation”, Guo et al 2022
“UniSumm: Unified Few-Shot Summarization With Multi-Task Pre-Training and Prefix-Tuning”, Chen et al 2022
UniSumm: Unified Few-shot Summarization with Multi-Task Pre-Training and Prefix-Tuning
“Uni-Perceiver V2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks”, Li et al 2022
Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks
“Distilled DeepConsensus: Knowledge Distillation for Fast and Accurate DNA Sequence Correction”, Belyaeva et al 2022
Distilled DeepConsensus: Knowledge distillation for fast and accurate DNA sequence correction
“Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities”, Tjandra et al 2022
“OneFormer: One Transformer to Rule Universal Image Segmentation”, Jain et al 2022
OneFormer: One Transformer to Rule Universal Image Segmentation
“Characterizing Intrinsic Compositionality in Transformers With Tree Projections”, Murty et al 2022
Characterizing Intrinsic Compositionality in Transformers with Tree Projections
“Fast DistilBERT on CPUs”, Shen et al 2022
“n-Gram Is Back: Residual Learning of Neural Text Generation With n-Gram Language Model”, Li et al 2022
n-gram Is Back: Residual Learning of Neural Text Generation with n-gram Language Model
“Same Pre-Training Loss, Better Downstream: Implicit Bias Matters for Language Models”, Liu et al 2022
Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models
“The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers”, Li et al 2022
The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers
“Noise-Robust De-Duplication at Scale”, Silcock et al 2022
“Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints”, Jawahar et al 2022
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
“Improving Sample Quality of Diffusion Models Using Self-Attention Guidance”, Hong et al 2022
Improving Sample Quality of Diffusion Models Using Self-Attention Guidance
“Semantic Scene Descriptions As an Objective of Human Vision”, Doerig et al 2022
“SetFit: Efficient Few-Shot Learning Without Prompts”, Tunstall et al 2022
“A Generalist Neural Algorithmic Learner”, Ibarz et al 2022
“Machine Reading, Fast and Slow: When Do Models "Understand" Language?”, Choudhury et al 2022
Machine Reading, Fast and Slow: When Do Models "Understand" Language?
“On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)”, Rohanian et al 2022
On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)
“Analyzing Transformers in Embedding Space”, Dar et al 2022
“ASR2K: Speech Recognition for Around 2,000 Languages without Audio”, Li et al 2022
ASR2K: Speech Recognition for Around 2,000 Languages without Audio
“MeloForm: Generating Melody With Musical Form Based on Expert Systems and Neural Networks”, Lu et al 2022
MeloForm: Generating Melody with Musical Form based on Expert Systems and Neural Networks
“CorpusBrain: Pre-Train a Generative Retrieval Model for Knowledge-Intensive Language Tasks”, Chen et al 2022
CorpusBrain: Pre-train a Generative Retrieval Model for Knowledge-Intensive Language Tasks
“PatchDropout: Economizing Vision Transformers Using Patch Dropout”, Liu et al 2022
PatchDropout: Economizing Vision Transformers Using Patch Dropout
“Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
Why do tree-based models still outperform deep learning on tabular data?
“Re2G: Retrieve, Rerank, Generate”, Glass et al 2022
“Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling”, Nguyen & Grover 2022
Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling
“TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data”, Hollmann et al 2022
TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data
“Neural Networks and the Chomsky Hierarchy”, Delétang et al 2022
“Do Loyal Users Enjoy Better Recommendations? Understanding Recommender Accuracy from a Time Perspective”, Ji et al 2022
“Transfer Learning With Deep Tabular Models”, Levin et al 2022
“BertNet: Harvesting Knowledge Graphs from Pretrained Language Models”, Hao et al 2022
BertNet: Harvesting Knowledge Graphs from Pretrained Language Models
“ProGen2: Exploring the Boundaries of Protein Language Models”, Nijkamp et al 2022
ProGen2: Exploring the Boundaries of Protein Language Models
“SBERT Studies Meaning Representations: Decomposing Sentence Embeddings into Explainable Semantic Features”, Opitz & Frank 2022
“RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
RHO-LOSS: Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
“LAVENDER: Unifying Video-Language Understanding As Masked Language Modeling”, Li et al 2022
LAVENDER: Unifying Video-Language Understanding as Masked Language Modeling
“Language Models Are General-Purpose Interfaces”, Hao et al 2022
“Uni-Perceiver-MoE: Learning Sparse Generalist Models With Conditional MoEs”, Zhu et al 2022
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
“Reconstructing the Cascade of Language Processing in the Brain Using the Internal Computations of a Transformer-Based Language Model”, Kumar et al 2022
“A Neural Corpus Indexer for Document Retrieval”, Wang et al 2022
“XTC: Extreme Compression for Pre-Trained Transformers Made Simple and Efficient”, Wu et al 2022
XTC: Extreme Compression for Pre-trained Transformers Made Simple and Efficient
“Toward a Realistic Model of Speech Processing in the Brain With Self-Supervised Learning”, Millet et al 2022
Toward a realistic model of speech processing in the brain with self-supervised learning
“Text2Human: Text-Driven Controllable Human Image Generation”, Jiang et al 2022
“Anime Character Recognition Using Intermediate Features Aggregation”, Rios et al 2022
Anime Character Recognition using Intermediate Features Aggregation
“Towards Learning Universal Hyperparameter Optimizers With Transformers”, Chen et al 2022
Towards Learning Universal Hyperparameter Optimizers with Transformers
“FLEURS: Few-Shot Learning Evaluation of Universal Representations of Speech”, Conneau et al 2022
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
“HTPS: HyperTree Proof Search for Neural Theorem Proving”, Lample et al 2022
“On the Paradox of Learning to Reason from Data”, Zhang et al 2022
“Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
Housekeep: Tidying Virtual Households using Commonsense Reasoning
“UViM: A Unified Modeling Approach for Vision With Learned Guiding Codes”, Kolesnikov et al 2022
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
“Tradformer: A Transformer Model of Traditional Music Transcriptions”, Casini & Sturm 2022
Tradformer: A Transformer Model of Traditional Music Transcriptions
“Continual Pre-Training Mitigates Forgetting in Language and Vision”, Cossu et al 2022
Continual Pre-Training Mitigates Forgetting in Language and Vision
“PLAID: An Efficient Engine for Late Interaction Retrieval”, Santhanam et al 2022
“Few-Shot Parameter-Efficient Fine-Tuning Is Better and Cheaper Than In-Context Learning”, Liu et al 2022
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
“SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
SymphonyNet: Symphony Generation with Permutation Invariant Language Model
“When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”, Vasudevan et al 2022
When does dough become a bagel? Analyzing the remaining mistakes on ImageNet
“A Challenging Benchmark of Anime Style Recognition”, Li et al 2022
“Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers
“Masked Siamese Networks for Label-Efficient Learning”, Assran et al 2022
“DualPrompt: Complementary Prompting for Rehearsal-Free Continual Learning”, Wang et al 2022
DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning
“Language Models That Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion”, Shuster et al 2022
“On Embeddings for Numerical Features in Tabular Deep Learning”, Gorishniy et al 2022
On Embeddings for Numerical Features in Tabular Deep Learning
“In-Context Learning and Induction Heads”, Olsson et al 2022
“LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models”, Javaheripi et al 2022
LiteTransformerSearch: Training-free Neural Architecture Search for Efficient Language Models
“Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words”, Feng et al 2022
Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words
“OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-To-Sequence Learning Framework”, Wang et al 2022
“TACTiS: Transformer-Attentional Copulas for Time Series”, Drouin et al 2022
“AutoDistil: Few-Shot Task-Agnostic Neural Architecture Search for Distilling Large Language Models”, Xu et al 2022
AutoDistil: Few-shot Task-agnostic Neural Architecture Search for Distilling Large Language Models
“FIGARO: Generating Symbolic Music With Fine-Grained Artistic Control”, Rütte et al 2022
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
“Robust Contrastive Learning against Noisy Views”, Chuang et al 2022
“HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning”, Zhmoginov et al 2022
HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning
“A Mathematical Framework for Transformer Circuits”, Elhage et al 2021
“PFNs: Transformers Can Do Bayesian Inference”, Müller et al 2021
“XGLM: Few-Shot Learning With Multilingual Language Models”, Lin et al 2021
“An Empirical Investigation of the Role of Pre-Training in Lifelong Learning”, Mehta et al 2021
An Empirical Investigation of the Role of Pre-training in Lifelong Learning
“AI Improvements in Chemical Calculations”, Lowe 2021
“You Only Need One Model for Open-Domain Question Answering”, Lee et al 2021
“Human Parity on CommonsenseQA: Augmenting Self-Attention With External Attention”, Xu et al 2021
Human Parity on CommonsenseQA: Augmenting Self-Attention with External Attention
“ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction”, Santhanam et al 2021
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
“Uni-Perceiver: Pre-Training Unified Architecture for Generic Perception for Zero-Shot and Few-Shot Tasks”, Zhu et al 2021
“Inducing Causal Structure for Interpretable Neural Networks (IIT)”, Geiger et al 2021
Inducing Causal Structure for Interpretable Neural Networks (IIT)
“OCR-Free Document Understanding Transformer”, Kim et al 2021
“FQ-ViT: Fully Quantized Vision Transformer without Retraining”, Lin et al 2021
FQ-ViT: Fully Quantized Vision Transformer without Retraining
“Semi-Supervised Music Tagging Transformer”, Won et al 2021
“LEMON: Scaling Up Vision-Language Pre-Training for Image Captioning”, Hu et al 2021
LEMON: Scaling Up Vision-Language Pre-training for Image Captioning
“UNICORN: Crossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling”, Yang et al 2021
UNICORN: Crossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling
“Compositional Transformers for Scene Generation”, Hudson & Zitnick 2021
“It’s About Time: Analog Clock Reading in the Wild”, Yang et al 2021
“XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale”, Babu et al 2021
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
“A Survey of Visual Transformers”, Liu et al 2021
“Improving Visual Quality of Image Synthesis by A Token-Based Generator With Transformers”, Zeng et al 2021
Improving Visual Quality of Image Synthesis by A Token-based Generator with Transformers
“The Efficiency Misnomer”, Dehghani et al 2021
“STransGAN: An Empirical Study on Transformer in GANs”, Xu et al 2021
“Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora”, Jin et al 2021
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
“The Dangers of Underclaiming: Reasons for Caution When Reporting How NLP Systems Fail”, Bowman 2021
The Dangers of Underclaiming: Reasons for Caution When Reporting How NLP Systems Fail
“Palette: Image-To-Image Diffusion Models”, Saharia et al 2021
“Transformers Are Meta-Reinforcement Learners”, Anonymous 2021
“Autoregressive Latent Video Prediction With High-Fidelity Image Generator”, Seo et al 2021
Autoregressive Latent Video Prediction with High-Fidelity Image Generator
“Text2Brain: Synthesis of Brain Activation Maps from Free-Form Text Query”, Ngo et al 2021
Text2Brain: Synthesis of Brain Activation Maps from Free-form Text Query
“Understanding and Overcoming the Challenges of Efficient Transformer Quantization”, Bondarenko et al 2021
Understanding and Overcoming the Challenges of Efficient Transformer Quantization
“BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition”, Zhang et al 2021
“TrOCR: Transformer-Based Optical Character Recognition With Pre-Trained Models”, Li et al 2021
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
“MeLT: Message-Level Transformer With Masked Document Representations As Pre-Training for Stance Detection”, Matero et al 2021
“KroneckerBERT: Learning Kronecker Decomposition for Pre-Trained Language Models via Knowledge Distillation”, Tahaei et al 2021
“Block Pruning For Faster Transformers”, Lagunas et al 2021
“The Sensory Neuron As a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning”, Tang & Ha 2021
“DeepConsensus: Gap-Aware Sequence Transformers for Sequence Correction”, Baid et al 2021
DeepConsensus: Gap-Aware Sequence Transformers for Sequence Correction
“A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, Zhao et al 2021
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
“Data and Parameter Scaling Laws for Neural Machine Translation”, Gordon et al 2021
Data and Parameter Scaling Laws for Neural Machine Translation
“ImageBART: Bidirectional Context With Multinomial Diffusion for Autoregressive Image Synthesis”, Esser et al 2021
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
“Modeling Protein Using Large-Scale Pretrain Language Model”, Xiao et al 2021
“Billion-Scale Pretraining With Vision Transformers for Multi-Task Visual Representations”, Beal et al 2021
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
“EVA: An Open-Domain Chinese Dialogue System With Large-Scale Generative Pre-Training”, Zhou et al 2021
EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
“Internet-Augmented Dialogue Generation”, Komeili et al 2021
“HTLM: Hyper-Text Pre-Training and Prompting of Language Models”, Aghajanyan et al 2021
HTLM: Hyper-Text Pre-Training and Prompting of Language Models
“SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking”, Formal et al 2021
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
“ViTGAN: Training GANs With Vision Transformers”, Lee et al 2021
“ARM-Net: Adaptive Relation Modeling Network for Structured Data”, Cai et al 2021
ARM-Net: Adaptive Relation Modeling Network for Structured Data
“SCARF: Self-Supervised Contrastive Learning Using Random Feature Corruption”, Bahri et al 2021
SCARF: Self-Supervised Contrastive Learning using Random Feature Corruption
“Charformer: Fast Character Transformers via Gradient-Based Subword Tokenization”, Tay et al 2021
Charformer: Fast Character Transformers via Gradient-based Subword Tokenization
“BitFit: Simple Parameter-Efficient Fine-Tuning for Transformer-Based Masked Language-Models”, Zaken et al 2021
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
“Revisiting the Calibration of Modern Neural Networks”, Minderer et al 2021
“Scaling Laws for Acoustic Models”, Droppo & Elibol 2021
“CoAtNet: Marrying Convolution and Attention for All Data Sizes”, Dai et al 2021
CoAtNet: Marrying Convolution and Attention for All Data Sizes
“Chasing Sparsity in Vision Transformers: An End-To-End Exploration”, Chen et al 2021
Chasing Sparsity in Vision Transformers: An End-to-End Exploration
“Tabular Data: Deep Learning Is Not All You Need”, Shwartz-Ziv & Armon 2021
“Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning”, Kossen et al 2021
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
“Exploring Transfer Learning Techniques for Named Entity Recognition in Noisy User-Generated Text”, Bogensperger 2021
Exploring Transfer Learning techniques for Named Entity Recognition in Noisy User-Generated Text
“SegFormer: Simple and Efficient Design for Semantic Segmentation With Transformers”, Xie et al 2021
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
“Maximizing 3-D Parallelism in Distributed Training for Huge Neural Networks”, Bian et al 2021
Maximizing 3-D Parallelism in Distributed Training for Huge Neural Networks
“One4all User Representation for Recommender Systems in E-Commerce”, Shin et al 2021
One4all User Representation for Recommender Systems in E-commerce
“QASPER: A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers”, Dasigi et al 2021
QASPER: A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers
“MathBERT: A Pre-Trained Model for Mathematical Formula Understanding”, Peng et al 2021
MathBERT: A Pre-Trained Model for Mathematical Formula Understanding
“MDETR—Modulated Detection for End-To-End Multi-Modal Understanding”, Kamath et al 2021
MDETR—Modulated Detection for End-to-End Multi-Modal Understanding
“XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond”, Barbieri et al 2021
XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond
“[Ali Released PLUG: 27 Billion Parameters, the Largest Pre-Trained Language Model in the Chinese Community]”, Yuying 2021
“SimCSE: Simple Contrastive Learning of Sentence Embeddings”, Gao et al 2021
“Robust Open-Vocabulary Translation from Visual Text Representations”, Salesky et al 2021
Robust Open-Vocabulary Translation from Visual Text Representations
“Memorization versus Generalization in Pre-Trained Language Models”, Tänzer et al 2021
Memorization versus Generalization in Pre-trained Language Models
“Retrieval Augmentation Reduces Hallucination in Conversation”, Shuster et al 2021
Retrieval Augmentation Reduces Hallucination in Conversation
“Gradient-Based Adversarial Attacks against Text Transformers”, Guo et al 2021
Gradient-based Adversarial Attacks against Text Transformers
“TSDAE: Using Transformer-Based Sequential Denoising Autoencoder for Unsupervised Sentence Embedding Learning”, Wang et al 2021
“Machine Translation Decoding beyond Beam Search”, Leblond et al 2021
“An Empirical Study of Training Self-Supervised Vision Transformers”, Chen et al 2021
An Empirical Study of Training Self-Supervised Vision Transformers
“ChinAI #137: Year 3 of ChinAI: Reflections on the Newsworthiness of Machine Translation”, Ding 2021
ChinAI #137: Year 3 of ChinAI: Reflections on the newsworthiness of machine translation
“GPV-1: Towards General Purpose Vision Systems”, Gupta et al 2021
“DeepViT: Towards Deeper Vision Transformer”, Zhou et al 2021
“ConViT: Improving Vision Transformers With Soft Convolutional Inductive Biases”, d’Ascoli et al 2021
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
“Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence (VitaminC)
“Learning from Videos to Understand the World”, Zweig et al 2021
“Are NLP Models Really Able to Solve Simple Math Word Problems?”, Patel et al 2021
Are NLP Models really able to Solve Simple Math Word Problems?
“CANINE: Pre-Training an Efficient Tokenization-Free Encoder for Language Representation”, Clark et al 2021
CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation
“TransGAN: Two Transformers Can Make One Strong GAN”, Jiang et al 2021
“Baller2vec: A Multi-Entity Transformer For Multi-Agent Spatiotemporal Modeling”, Alcorn & Nguyen 2021
baller2vec: A Multi-Entity Transformer For Multi-Agent Spatiotemporal Modeling
“ViLT: Vision-And-Language Transformer Without Convolution or Region Supervision”, Kim et al 2021
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
“Video Transformer Network”, Neimark et al 2021
“Tokens-To-Token ViT: Training Vision Transformers from Scratch on ImageNet”, Yuan et al 2021
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
“BENDR: Using Transformers and a Contrastive Self-Supervised Learning Task to Learn from Massive Amounts of EEG Data”, Kostas et al 2021
“Bottleneck Transformers for Visual Recognition”, Srinivas et al 2021
“DAF:re: A Challenging, Crowd-Sourced, Large-Scale, Long-Tailed Dataset For Anime Character Recognition”, Rios et al 2021
“UPDeT: Universal Multi-Agent Reinforcement Learning via Policy Decoupling With Transformers”, Hu et al 2021
UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers
“MSR-VTT: A Large Video Description Dataset for Bridging Video and Language”, Xu et al 2021
MSR-VTT: A Large Video Description Dataset for Bridging Video and Language
“XMC-GAN: Cross-Modal Contrastive Learning for Text-To-Image Generation”, Zhang et al 2021
XMC-GAN: Cross-Modal Contrastive Learning for Text-to-Image Generation
“Superbizarre Is Not Superb: Derivational Morphology Improves BERT’s Interpretation of Complex Words”, Hofmann et al 2021
Superbizarre Is Not Superb: Derivational Morphology Improves BERT’s Interpretation of Complex Words
“Training Data-Efficient Image Transformers & Distillation through Attention”, Touvron et al 2020
Training data-efficient image transformers & distillation through attention
“VQ-GAN: Taming Transformers for High-Resolution Image Synthesis”, Esser et al 2020
VQ-GAN: Taming Transformers for High-Resolution Image Synthesis
“Object-Based Attention for Spatio-Temporal Reasoning: Outperforming Neuro-Symbolic Models With Flexible Distributed Architectures”, Ding et al 2020
“Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences”, Rives et al 2020
“Progressively Stacking 2.0: A Multi-Stage Layerwise Training Method for BERT Training Speedup”, Yang et al 2020
Progressively Stacking 2.0: A Multi-stage Layerwise Training Method for BERT Training Speedup
“TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game”, Han et al 2020
“A Recurrent Vision-And-Language BERT for Navigation”, Hong et al 2020
“A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
“CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters”, Boukkouri et al 2020
“TernaryBERT: Distillation-Aware Ultra-Low Bit BERT”, Zhang et al 2020
“Weird AI Yankovic: Generating Parody Lyrics”, Riedl 2020
“It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners”, Schick & Schütze 2020
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
“DeepSpeed: Extreme-Scale Model Training for Everyone”, Team et al 2020
“Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing”, Gu et al 2020
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
“CoVoST 2 and Massively Multilingual Speech-To-Text Translation”, Wang et al 2020
CoVoST 2 and Massively Multilingual Speech-to-Text Translation
“Modern Hopfield Networks and Attention for Immune Repertoire Classification”, Widrich et al 2020
Modern Hopfield Networks and Attention for Immune Repertoire Classification
“Hopfield Networks Is All You Need”, Ramsauer et al 2020
“Can Neural Networks Acquire a Structural Bias from Raw Linguistic Data?”, Warstadt & Bowman 2020
Can neural networks acquire a structural bias from raw linguistic data?
“DeepSinger: Singing Voice Synthesis With Data Mined From the Web”, Ren et al 2020
DeepSinger: Singing Voice Synthesis with Data Mined From the Web
“Data Movement Is All You Need: A Case Study on Optimizing Transformers”, Ivanov et al 2020
Data Movement Is All You Need: A Case Study on Optimizing Transformers
“Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations”, Baevski et al 2020
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
“PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training”, Narayanan et al 2020
PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training
“Learning to Learn With Feedback and Local Plasticity”, Lindsey & Litwin-Kumar 2020
“Improving GAN Training With Probability Ratio Clipping and Sample Reweighting”, Wu et al 2020
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
“DeBERTa: Decoding-Enhanced BERT With Disentangled Attention”, He et al 2020
“DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations”, Giorgi et al 2020
DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
“DETR: End-To-End Object Detection With Transformers”, Carion et al 2020
“Open-Retrieval Conversational Question Answering”, Qu et al 2020
“TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data”, Yin et al 2020
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
“ForecastQA: A Question Answering Challenge for Event Forecasting With Temporal Text Data”, Jin et al 2020
ForecastQA: A Question Answering Challenge for Event Forecasting with Temporal Text Data
“Can Multilingual Language Models Transfer to an Unseen Dialect? A Case Study on North African Arabizi”, Muller et al 2020
“VLN-BERT: Improving Vision-And-Language Navigation With Image-Text Pairs from the Web”, Majumdar et al 2020
VLN-BERT: Improving Vision-and-Language Navigation with Image-Text Pairs from the Web
“Blender: A State-Of-The-Art Open Source Chatbot”, Roller et al 2020
“General Purpose Text Embeddings from Pre-Trained Language Models for Scalable Inference”, Du et al 2020
General Purpose Text Embeddings from Pre-trained Language Models for Scalable Inference
“Recipes for Building an Open-Domain Chatbot”, Roller et al 2020
“Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks”, Gururangan et al 2020
Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
“On the Effect of Dropping Layers of Pre-Trained Transformer Models”, Sajjad et al 2020
On the Effect of Dropping Layers of Pre-trained Transformer Models
“Rapformer: Conditional Rap Lyrics Generation With Denoising Autoencoders”, Nikolov et al 2020
Rapformer: Conditional Rap Lyrics Generation with Denoising Autoencoders
“TAPAS: Weakly Supervised Table Parsing via Pre-Training”, Herzig et al 2020
“A Hundred Visions and Revisions”, Binder 2020
“Rethinking Parameter Counting in Deep Models: Effective Dimensionality Revisited”, Maddox et al 2020
Rethinking Parameter Counting in Deep Models: Effective Dimensionality Revisited
“AraBERT: Transformer-Based Model for Arabic Language Understanding”, Antoun et al 2020
AraBERT: Transformer-based Model for Arabic Language Understanding
“MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”, Wang et al 2020
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
“GNS: Learning to Simulate Complex Physics With Graph Networks”, Sanchez-Gonzalez et al 2020
GNS: Learning to Simulate Complex Physics with Graph Networks
“Do We Need Zero Training Loss After Achieving Zero Training Error?”, Ishida et al 2020
Do We Need Zero Training Loss After Achieving Zero Training Error?
“Bayesian Deep Learning and a Probabilistic Perspective of Generalization”, Wilson & Izmailov 2020
Bayesian Deep Learning and a Probabilistic Perspective of Generalization
“Transformers As Soft Reasoners over Language”, Clark et al 2020
“Towards a Conversational Agent That Can Chat About…Anything”, Adiwardana & Luong 2020
“Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference”, Schick & Schütze 2020
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
“Improving Transformer Optimization Through Better Initialization”, Huang 2020
Improving Transformer Optimization Through Better Initialization:
“VIME: Extending the Success of Self-Supervised and Semi-Supervised Learning to Tabular Domain”, Yoon et al 2020
VIME: Extending the Success of Self-supervised and Semi-supervised Learning to Tabular Domain
“Measuring Compositional Generalization: A Comprehensive Method on Realistic Data”, Keysers et al 2019
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
“Mastering Complex Control in MOBA Games With Deep Reinforcement Learning”, Ye et al 2019
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
“PEGASUS: Pre-Training With Extracted Gap-Sentences for Abstractive Summarization”, Zhang et al 2019
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
“Encoding Musical Style With Transformer Autoencoders”, Choi et al 2019
“Deep Double Descent: We Show That the Double Descent Phenomenon Occurs in CNNs, ResNets, and Transformers: Performance First Improves, Then Gets Worse, and Then Improves Again With Increasing Model Size, Data Size, or Training Time”, Nakkiran et al 2019
“Detecting GAN Generated Errors”, Zhu et al 2019
“SimpleBooks: Long-Term Dependency Book Dataset With Simplified English Vocabulary for Word-Level Language Modeling”, Nguyen 2019
“Unsupervised Cross-Lingual Representation Learning at Scale”, Conneau et al 2019
“DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter”, Sanh et al 2019
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
“TinyBERT: Distilling BERT for Natural Language Understanding”, Jiao et al 2019
TinyBERT: Distilling BERT for Natural Language Understanding
“Do NLP Models Know Numbers? Probing Numeracy in Embeddings”, Wallace et al 2019
“PubMedQA: A Dataset for Biomedical Research Question Answering”, Jin et al 2019
PubMedQA: A Dataset for Biomedical Research Question Answering
“Frustratingly Easy Natural Question Answering”, Pan et al 2019
“Distributionally Robust Language Modeling”, Oren et al 2019
“Language Models As Knowledge Bases?”, Petroni et al 2019
“Encode, Tag, Realize: High-Precision Text Editing”, Malmi et al 2019
“Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks”, Reimers & Gurevych 2019
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
“Well-Read Students Learn Better: On the Importance of Pre-Training Compact Models”, Turc et al 2019
Well-Read Students Learn Better: On the Importance of Pre-training Compact Models
“TabNet: Attentive Interpretable Tabular Learning”, Arik & Pfister 2019
“StructBERT: Incorporating Language Structures into Pre-Training for Deep Language Understanding”, Wang et al 2019
StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
“What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models”, Ettinger 2019
What BERT is not: Lessons from a new suite of psycholinguistic diagnostics for language models
“RoBERTa: A Robustly Optimized BERT Pretraining Approach”, Liu et al 2019
“Theoretical Limitations of Self-Attention in Neural Sequence Models”, Hahn 2019
Theoretical Limitations of Self-Attention in Neural Sequence Models
“Energy and Policy Considerations for Deep Learning in NLP”, Strubell et al 2019
“Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned”, Voita et al 2019
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
“HellaSwag: Can a Machine Really Finish Your Sentence?”, Zellers et al 2019
“UniLM: Unified Language Model Pre-Training for Natural Language Understanding and Generation”, Dong et al 2019
UniLM: Unified Language Model Pre-training for Natural Language Understanding and Generation
“MASS: Masked Sequence to Sequence Pre-Training for Language Generation”, Song et al 2019
MASS: Masked Sequence to Sequence Pre-training for Language Generation
“Mask-Predict: Parallel Decoding of Conditional Masked Language Models”, Ghazvininejad et al 2019
Mask-Predict: Parallel Decoding of Conditional Masked Language Models
“Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes”, You et al 2019
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
“LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game”, Urbanek et al 2019
LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game
“Insertion Transformer: Flexible Sequence Generation via Insertion Operations”, Stern et al 2019
Insertion Transformer: Flexible Sequence Generation via Insertion Operations
“Adapter: Parameter-Efficient Transfer Learning for NLP”, Houlsby et al 2019
“Learning and Evaluating General Linguistic Intelligence”, Yogatama et al 2019
“BioBERT: a Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining”, Lee et al 2019
BioBERT: a pre-trained biomedical language representation model for biomedical text mining
“Efficient Training of BERT by Progressively Stacking”, Gong et al 2019
“Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
“Blockwise Parallel Decoding for Deep Autoregressive Models”, Stern et al 2018
“Object Hallucination in Image Captioning”, Rohrbach et al 2018
“Self-Attention Generative Adversarial Networks”, Zhang et al 2018
“Universal Sentence Encoder”, Cer et al 2018
“Self-Attention With Relative Position Representations”, Shaw et al 2018
“Learning Longer-Term Dependencies in RNNs With Auxiliary Losses”, Trinh et al 2018
Learning Longer-term Dependencies in RNNs with Auxiliary Losses
“Generating Structured Music through Self-Attention”, Huang et al 2018
“GPipe: Easy Scaling With Micro-Batch Pipeline Parallelism § Pg4”, Huang 2018 (page 4 org google)
GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism § pg4:
“A Simple Neural Attentive Meta-Learner”, Mishra et al 2017
“Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer”, Zagoruyko & Komodakis 2016
“QRNNs: Quasi-Recurrent Neural Networks”, Bradbury et al 2016
“Gaussian Error Linear Units (GELUs)”, Hendrycks & Gimpel 2016
“Pointer Networks”, Vinyals et al 2015
“No Physics? No Problem. AI Weather Forecasting Is Already Making Huge Strides.”
No physics? No problem. AI weather forecasting is already making huge strides.
“Huggingface: transformers Repo”, Huggingface 2025
“Transformers in Vision”
“The Illustrated GPT-2 (Visualizing Transformer Language Models)”
The Illustrated GPT-2 (Visualizing Transformer Language Models):
“The Illustrated Transformer”
“Autoregressive Long-Context Music Generation With Perceiver AR”
Autoregressive long-context music generation with Perceiver AR:
View External Link:
“The Transformer—Attention Is All You Need.”
“Understanding BERT Transformer: Attention Isn’t All You Need”, Sileo 2025
Understanding BERT Transformer: Attention isn’t all you need
“Caglar Gulcehre Homepage”, Gulcehre 2025
“Etched Is Making the Biggest Bet in AI”
“Was Linguistic A.I. Created by Accident?”
“Transformers Are a Very Exciting Family of Machine Learning Architectures”, Bloem 2025
Transformers are a very exciting family of machine learning architectures
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
language-models
perception-learning
conversational-ai
Wikipedia
Miscellaneous
-
/doc/ai/nn/transformer/2021-hu-figure2-b-datascalingfinetuningperformanceonnocaps.jpg: -
/doc/ai/nn/transformer/2021-hu-figure6-largerlemoncaptionmodelsaremoresampleefficient.jpg: -
https://aclanthology.org/D18-1092/:View External Link:
-
https://github.com/huggingface/transformers/tree/main/src/transformers -
https://gonzoml.substack.com/p/you-only-cache-once-decoder-decoder -
https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/:View External Link:
https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/ -
https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms -
https://research.google/blog/on-device-content-distillation-with-graph-neural-networks/ -
https://research.google/blog/unsupervised-speech-to-speech-translation-from-monolingual-data/ -
https://sander.ai/2023/01/09/diffusion-language.html#deepmind: -
https://www.quantamagazine.org/how-ai-transformers-mimic-parts-of-the-brain-20220912/:
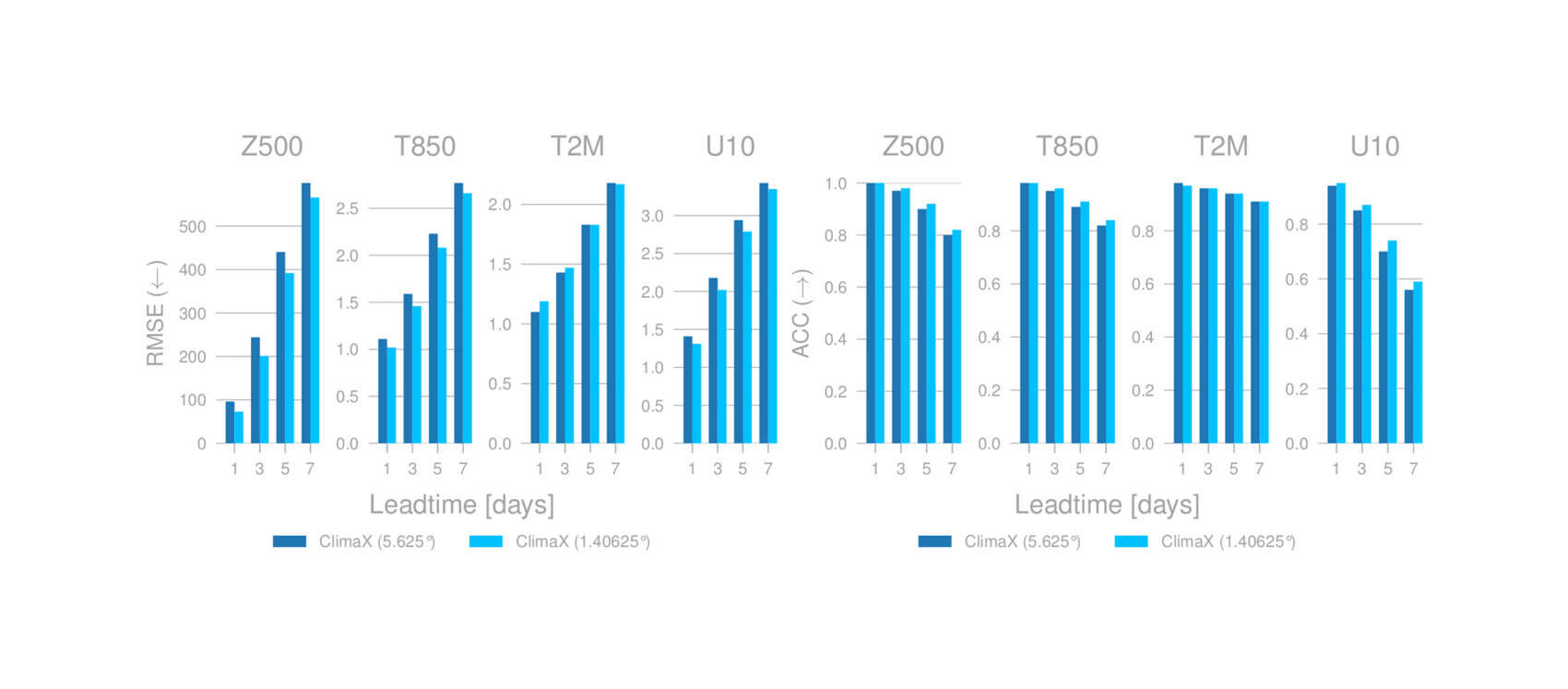{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
-
https://arxiv.org/abs/2408.00118#google: “Gemma 2: Improving Open Language Models at a Practical Size”, -
https://www.lesswrong.com/posts/ADrTuuus6JsQr5CSi/investigating-the-ability-of-llms-to-recognize-their-own: “Investigating the Ability of LLMs to Recognize Their Own Writing”, -
https://arxiv.org/abs/2405.20233: “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, -
https://arxiv.org/abs/2405.14860: “Not All Language Model Features Are Linear”, -
https://arxiv.org/abs/2405.05254#microsoft: “You Only Cache Once: Decoder-Decoder Architectures for Language Models”, -
https://arxiv.org/abs/2404.13292: “Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge”, -
https://arxiv.org/abs/2404.10102: “Chinchilla Scaling: A Replication Attempt”, -
https://osf.io/preprints/psyarxiv/kjuce: “Language Models Accurately Infer Correlations between Psychological Items and Scales from Text Alone”, -
https://inflection.ai/inflection-2-5: “Inflection-2.5: Meet the World’s Best Personal AI”, -
https://arxiv.org/abs/2312.03876: “Scaling Transformer Neural Networks for Skillful and Reliable Medium-Range Weather Forecasting”, -
https://arxiv.org/abs/2312.02116: “GIVT: Generative Infinite-Vocabulary Transformers”, -
https://arxiv.org/abs/2311.03079#zhipu: “CogVLM: Visual Expert for Pretrained Language Models”, -
https://arxiv.org/abs/2310.16836: “LLM-FP4: 4-Bit Floating-Point Quantized Transformers”, -
https://arxiv.org/abs/2310.13061: “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, -
https://arxiv.org/abs/2310.07096#ibm: “Sparse Universal Transformer”, -
https://arxiv.org/abs/2310.06694: “Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”, -
https://arxiv.org/abs/2310.02207: “Language Models Represent Space and Time”, -
https://arxiv.org/abs/2308.13418#facebook: “Nougat: Neural Optical Understanding for Academic Documents”, -
https://arxiv.org/abs/2308.11596#facebook: “SeamlessM4T: Massively Multilingual & Multimodal Machine Translation”, -
https://arxiv.org/abs/2306.09222#google: “RGD: Stochastic Re-Weighted Gradient Descent via Distributionally Robust Optimization”, -
https://arxiv.org/abs/2306.05426: “SequenceMatch: Imitation Learning for Autoregressive Sequence Modeling With Backtracking”, -
https://arxiv.org/abs/2305.11863: “Scaling Laws for Language Encoding Models in FMRI”, -
2023-jia.pdf: “When and How Artificial Intelligence Augments Employee Creativity”, -
https://arxiv.org/abs/2302.12441: “MUX-PLMs: Pre-Training Language Models With Data Multiplexing”, -
https://arxiv.org/abs/2302.05442#google: “Scaling Vision Transformers to 22 Billion Parameters”, -
https://arxiv.org/abs/2302.04907#google: “BMT: Binarized Neural Machine Translation”, -
https://arxiv.org/abs/2301.05217: “Progress Measures for Grokking via Mechanistic Interpretability”, -
https://arxiv.org/abs/2301.03728#facebook: “Scaling Laws for Generative Mixed-Modal Language Models”, -
https://arxiv.org/abs/2301.03992#nvidia: “Vision Transformers Are Good Mask Auto-Labelers”, -
https://arxiv.org/abs/2212.14034: “Cramming: Training a Language Model on a Single GPU in One Day”, -
https://arxiv.org/abs/2212.09410: “Less Is More: Parameter-Free Text Classification With Gzip”, -
https://arxiv.org/abs/2212.06727: “What Do Vision Transformers Learn? A Visual Exploration”, -
https://arxiv.org/abs/2212.05199#google: “MAGVIT: Masked Generative Video Transformer”, -
https://arxiv.org/abs/2212.05051: “VindLU: A Recipe for Effective Video-And-Language Pretraining”, -
https://arxiv.org/abs/2212.03533#microsoft: “Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, -
https://arxiv.org/abs/2212.01349#facebook: “NPM: Nonparametric Masked Language Modeling”, -
https://arxiv.org/abs/2211.09808: “Uni-Perceiver V2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks”, -
https://arxiv.org/abs/2211.06220: “OneFormer: One Transformer to Rule Universal Image Segmentation”, -
https://arxiv.org/abs/2210.06313#google: “The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers”, -
https://arxiv.org/abs/2209.11737: “Semantic Scene Descriptions As an Objective of Human Vision”, -
https://arxiv.org/abs/2209.11055: “SetFit: Efficient Few-Shot Learning Without Prompts”, -
https://arxiv.org/abs/2209.02535: “Analyzing Transformers in Embedding Space”, -
https://arxiv.org/abs/2207.06300#ibm: “Re2G: Retrieve, Rerank, Generate”, -
https://arxiv.org/abs/2207.01848: “TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data”, -
https://arxiv.org/abs/2204.05927: “Do Loyal Users Enjoy Better Recommendations? Understanding Recommender Accuracy from a Time Perspective”, -
https://arxiv.org/abs/2206.07137: “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, -
https://arxiv.org/abs/2206.07160#microsoft: “LAVENDER: Unifying Video-Language Understanding As Masked Language Modeling”, -
https://www.biorxiv.org/content/10.1101/2022.06.08.495348.full: “Reconstructing the Cascade of Language Processing in the Brain Using the Internal Computations of a Transformer-Based Language Model”, -
https://arxiv.org/abs/2206.01859#microsoft: “XTC: Extreme Compression for Pre-Trained Transformers Made Simple and Efficient”, -
https://arxiv.org/abs/2206.01685: “Toward a Realistic Model of Speech Processing in the Brain With Self-Supervised Learning”, -
2022-rios.pdf: “Anime Character Recognition Using Intermediate Features Aggregation”, -
https://arxiv.org/abs/2205.13320#google: “Towards Learning Universal Hyperparameter Optimizers With Transformers”, -
https://arxiv.org/abs/2205.11491#facebook: “HTPS: HyperTree Proof Search for Neural Theorem Proving”, -
https://arxiv.org/abs/2205.04596#google: “When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”, -
https://arxiv.org/abs/2203.13224#facebook: “Language Models That Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion”, -
https://arxiv.org/abs/2203.02094#microsoft: “LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models”, -
https://arxiv.org/abs/2202.03052#alibaba: “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-To-Sequence Learning Framework”, -
https://arxiv.org/abs/2112.10510: “PFNs: Transformers Can Do Bayesian Inference”, -
https://arxiv.org/abs/2111.13824: “FQ-ViT: Fully Quantized Vision Transformer without Retraining”, -
https://arxiv.org/abs/2111.12233#microsoft: “LEMON: Scaling Up Vision-Language Pre-Training for Image Captioning”, -
https://arxiv.org/abs/2111.09162: “It’s About Time: Analog Clock Reading in the Wild”, -
https://arxiv.org/abs/2111.06091: “A Survey of Visual Transformers”, -
https://arxiv.org/abs/2109.12948: “Understanding and Overcoming the Challenges of Efficient Transformer Quantization”, -
https://arxiv.org/abs/2109.10282#microsoft: “TrOCR: Transformer-Based Optical Character Recognition With Pre-Trained Models”, -
https://arxiv.org/abs/2109.06243#huawei: “KroneckerBERT: Learning Kronecker Decomposition for Pre-Trained Language Models via Knowledge Distillation”, -
https://arxiv.org/abs/2108.13002#microsoft: “A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, -
https://arxiv.org/abs/2107.07566#facebook: “Internet-Augmented Dialogue Generation”, -
https://arxiv.org/abs/2107.04589: “ViTGAN: Training GANs With Vision Transformers”, -
https://arxiv.org/abs/2106.12672#google: “Charformer: Fast Character Transformers via Gradient-Based Subword Tokenization”, -
https://arxiv.org/abs/2106.10199: “BitFit: Simple Parameter-Efficient Fine-Tuning for Transformer-Based Masked Language-Models”, -
https://arxiv.org/abs/2106.09488#amazon: “Scaling Laws for Acoustic Models”, -
https://arxiv.org/abs/2106.04803#google: “CoAtNet: Marrying Convolution and Attention for All Data Sizes”, -
https://arxiv.org/abs/2106.04533: “Chasing Sparsity in Vision Transformers: An End-To-End Exploration”, -
https://arxiv.org/abs/2105.15203: “SegFormer: Simple and Efficient Design for Semantic Segmentation With Transformers”, -
https://arxiv.org/abs/2104.07567#facebook: “Retrieval Augmentation Reduces Hallucination in Conversation”, -
https://chinai.substack.com/p/chinai-137-year-3-of-chinai: “ChinAI #137: Year 3 of ChinAI: Reflections on the Newsworthiness of Machine Translation”, -
https://arxiv.org/abs/2103.10697#facebook: “ConViT: Improving Vision Transformers With Soft Convolutional Inductive Biases”, -
https://ai.facebook.com/blog/learning-from-videos-to-understand-the-world/: “Learning from Videos to Understand the World”, -
https://arxiv.org/abs/2102.07074: “TransGAN: Two Transformers Can Make One Strong GAN”, -
https://arxiv.org/abs/2102.03334: “ViLT: Vision-And-Language Transformer Without Convolution or Region Supervision”, -
https://arxiv.org/abs/2101.11986: “Tokens-To-Token ViT: Training Vision Transformers from Scratch on ImageNet”, -
https://arxiv.org/abs/2101.11605#google: “Bottleneck Transformers for Visual Recognition”, -
https://arxiv.org/abs/2101.08674: “DAF:re: A Challenging, Crowd-Sourced, Large-Scale, Long-Tailed Dataset For Anime Character Recognition”, -
https://arxiv.org/abs/2101.04702#google: “XMC-GAN: Cross-Modal Contrastive Learning for Text-To-Image Generation”, -
https://arxiv.org/abs/2012.12877#facebook: “Training Data-Efficient Image Transformers & Distillation through Attention”, -
https://arxiv.org/abs/2012.08508#deepmind: “Object-Based Attention for Spatio-Temporal Reasoning: Outperforming Neuro-Symbolic Models With Flexible Distributed Architectures”, -
https://arxiv.org/abs/2011.13729#tencent: “TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game”, -
https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/: “DeepSpeed: Extreme-Scale Model Training for Everyone”, -
https://arxiv.org/abs/2008.02217: “Hopfield Networks Is All You Need”, -
https://arxiv.org/abs/2006.03654#microsoft: “DeBERTa: Decoding-Enhanced BERT With Disentangled Attention”, -
https://arxiv.org/abs/2005.12872#facebook: “DETR: End-To-End Object Detection With Transformers”, -
https://ai.meta.com/blog/state-of-the-art-open-source-chatbot/: “Blender: A State-Of-The-Art Open Source Chatbot”, -
https://arxiv.org/abs/2004.03844: “On the Effect of Dropping Layers of Pre-Trained Transformer Models”, -
https://arxiv.org/abs/2004.03965: “Rapformer: Conditional Rap Lyrics Generation With Denoising Autoencoders”, -
https://arxiv.org/abs/2002.10957#microsoft: “MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”, -
https://research.google/blog/towards-a-conversational-agent-that-can-chat-aboutanything/: “Towards a Conversational Agent That Can Chat About…Anything”, -
https://openai.com/research/deep-double-descent: “Deep Double Descent: We Show That the Double Descent Phenomenon Occurs in CNNs, ResNets, and Transformers: Performance First Improves, Then Gets Worse, and Then Improves Again With Increasing Model Size, Data Size, or Training Time”, -
https://arxiv.org/abs/1911.02116#facebook: “Unsupervised Cross-Lingual Representation Learning at Scale”, -
https://arxiv.org/abs/1909.10351: “TinyBERT: Distilling BERT for Natural Language Understanding”, -
https://arxiv.org/abs/1909.05286#ibm: “Frustratingly Easy Natural Question Answering”, -
https://arxiv.org/abs/1908.04577#alibaba: “StructBERT: Incorporating Language Structures into Pre-Training for Deep Language Understanding”, -
https://arxiv.org/abs/1907.11692#facebook: “RoBERTa: A Robustly Optimized BERT Pretraining Approach”, -
https://arxiv.org/abs/1905.03197: “UniLM: Unified Language Model Pre-Training for Natural Language Understanding and Generation”, -
https://arxiv.org/abs/1904.00962#google: “Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes”, -
https://arxiv.org/abs/1901.08746: “BioBERT: a Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining”, -
2018-huang.pdf: “Generating Structured Music through Self-Attention”, -
https://github.com/huggingface/transformers: “Huggingface:transformersRepo”,