‘compressed Transformers’ tag
- See Also
-
Links
- “Cached Transformers: Improving Transformers With Differentiable Memory Cache”, Zhang et al 2023
- “In-Context Autoencoder for Context Compression in a Large Language Model”, Ge et al 2023
- “Learning to Compress Prompts With Gist Tokens”, Mu et al 2023
- “Token Turing Machines”, Ryoo et al 2022
- “MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition”, Wu et al 2022
- “ABC: Attention With Bounded-Memory Control”, Peng et al 2021
- “Memorizing Transformers”, Wu et al 2021
- “Recursively Summarizing Books With Human Feedback”, Wu et al 2021
- “∞-Former: Infinite Memory Transformer”, Martins et al 2021
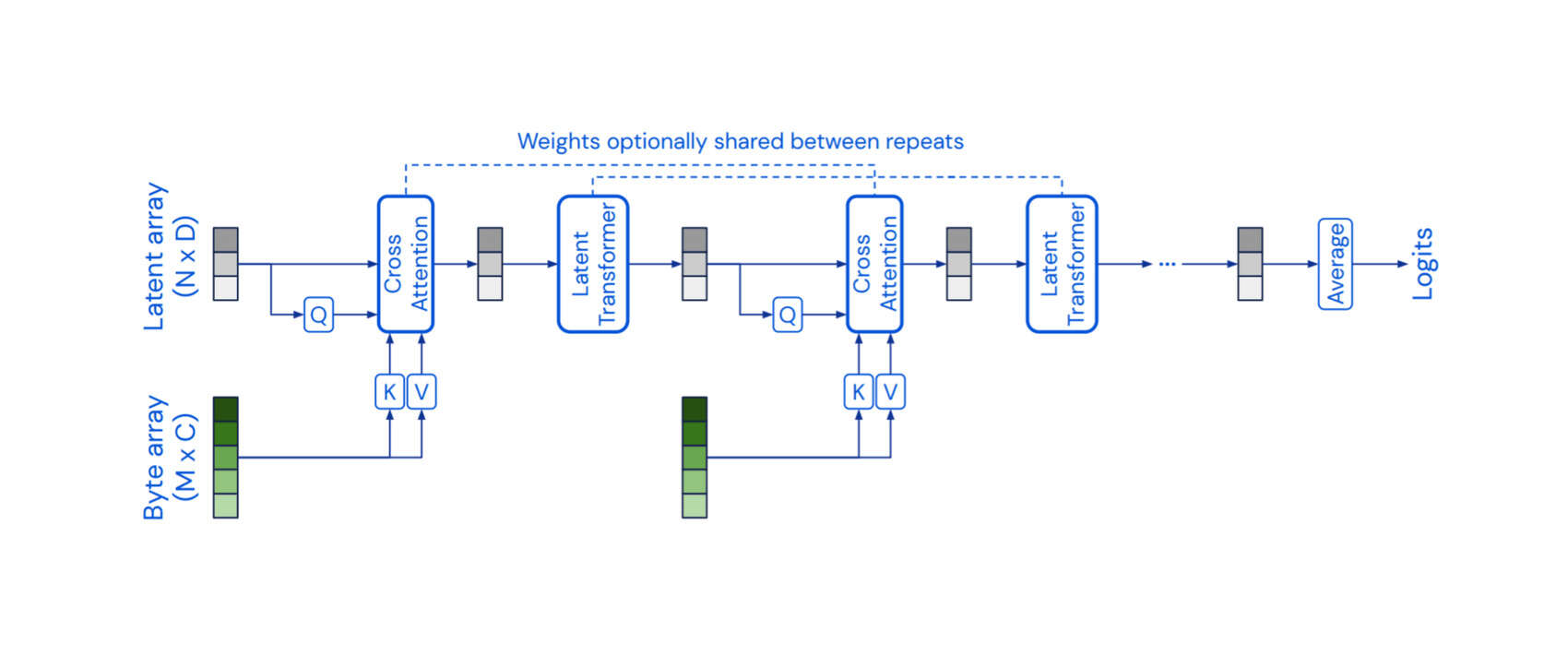
- “Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
- “TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?”, Ryoo et al 2021
- “Not All Memories Are Created Equal: Learning to Forget by Expiring”, Sukhbaatar et al 2021
- “Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
- “Learning to Summarize Long Texts With Memory Compression and Transfer”, Park et al 2020
- “Memory Transformer”, Burtsev et al 2020
- “Compressive Transformers for Long-Range Sequence Modeling”, Rae et al 2019
- “Set Transformer: A Framework for Attention-Based Permutation-Invariant Neural Networks”, Lee et al 2018
- “Generating Wikipedia by Summarizing Long Sequences”, Liu et al 2018
- “Phonotactic Reconstruction of Encrypted VoIP Conversations: Hookt on Fon-Iks”, White et al 2011
- Miscellaneous
- Bibliography
See Also
Links
“Cached Transformers: Improving Transformers With Differentiable Memory Cache”, Zhang et al 2023
Cached Transformers: Improving Transformers with Differentiable Memory Cache
“In-Context Autoencoder for Context Compression in a Large Language Model”, Ge et al 2023
In-context Autoencoder for Context Compression in a Large Language Model
“Learning to Compress Prompts With Gist Tokens”, Mu et al 2023
“Token Turing Machines”, Ryoo et al 2022
“MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition”, Wu et al 2022
MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition
“ABC: Attention With Bounded-Memory Control”, Peng et al 2021
“Memorizing Transformers”, Wu et al 2021
“Recursively Summarizing Books With Human Feedback”, Wu et al 2021
“∞-Former: Infinite Memory Transformer”, Martins et al 2021
“Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
Perceiver IO: A General Architecture for Structured Inputs & Outputs
“TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?”, Ryoo et al 2021
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
“Not All Memories Are Created Equal: Learning to Forget by Expiring”, Sukhbaatar et al 2021
Not All Memories are Created Equal: Learning to Forget by Expiring
“Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
“Learning to Summarize Long Texts With Memory Compression and Transfer”, Park et al 2020
Learning to Summarize Long Texts with Memory Compression and Transfer
“Memory Transformer”, Burtsev et al 2020
“Compressive Transformers for Long-Range Sequence Modeling”, Rae et al 2019
“Set Transformer: A Framework for Attention-Based Permutation-Invariant Neural Networks”, Lee et al 2018
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks
“Generating Wikipedia by Summarizing Long Sequences”, Liu et al 2018
“Phonotactic Reconstruction of Encrypted VoIP Conversations: Hookt on Fon-Iks”, White et al 2011
Phonotactic Reconstruction of Encrypted VoIP Conversations: Hookt on Fon-iks
Miscellaneous
{kind=link}
Bibliography
-
https://arxiv.org/abs/2304.08467: “Learning to Compress Prompts With Gist Tokens”, -
https://arxiv.org/abs/2203.08913#google: “Memorizing Transformers”, -
https://arxiv.org/abs/2109.10862#openai: “Recursively Summarizing Books With Human Feedback”, -
https://arxiv.org/abs/2107.14795#deepmind: “Perceiver IO: A General Architecture for Structured Inputs & Outputs”, -
https://arxiv.org/abs/2103.03206#deepmind: “Perceiver: General Perception With Iterative Attention”, -
https://arxiv.org/abs/1911.05507#deepmind: “Compressive Transformers for Long-Range Sequence Modeling”, -
2011-white.pdf: “Phonotactic Reconstruction of Encrypted VoIP Conversations: Hookt on Fon-Iks”,