‘LM tokenization’ tag
- See Also
- Gwern
-
Links
- “Llama Goes off the Rails If You Ask It for 5 Odd Numbers That Don’t Have the Letter ‘E’ in Them”, Applemoi 2025
- “Tokenization Is NP-Complete”, Whittington et al 2024
- “Clio: Privacy-Preserving Insights into Real-World AI Use”, Anthropic 2024
- “The Structure of the Token Space for Large Language Models”, Robinson et al 2024
- “When a Language Model Is Optimized for Reasoning, Does It Still Show Embers of Autoregression? An Analysis of OpenAI O1”, McCoy et al 2024
- “MaskBit: Embedding-Free Image Generation via Bit Tokens”, Weber et al 2024
- “A New Class of Glitch Tokens: BPE Sub-Token Artifacts”
- “JPEG-LM: LLMs As Image Generators With Canonical Codec Representations”, Han et al 2024
- “CARTE: toward Table Foundation Models”, Varoquaux 2024
- “Token Erasure As a Footprint of Implicit Vocabulary Items in LLMs”, Feucht et al 2024
- “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
- “Transformers Can Do Arithmetic With the Right Embeddings”, McLeish et al 2024
- “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
- “Zero-Shot Tokenizer Transfer”, Minixhofer et al 2024
- “Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models”, Bai et al 2024
- “Fishing for Magikarp: Automatically Detecting Under-Trained Tokens in Large Language Models”, Land & Bartolo 2024
- “SpaceByte: Towards Deleting Tokenization from Large Language Modeling”, Slagle 2024
- “Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge”, Batsuren et al 2024
- “Why Do Small Language Models Underperform? Studying Language Model Saturation via the Softmax Bottleneck”, Godey et al 2024
- “Training LLMs over Neurally Compressed Text”, Lester et al 2024
- “Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
- “CARTE: Pretraining and Transfer for Tabular Learning”, Kim et al 2024
- “Tokenization Counts: the Impact of Tokenization on Arithmetic in Frontier LLMs”, Singh & Strouse 2024
- “Tasks That Language Models Don’t Learn”, Lee & Lim 2024
- “Getting the Most out of Your Tokenizer for Pre-Training and Domain Adaptation”, Dagan et al 2024
- “MambaByte: Token-Free Selective State Space Model”, Wang et al 2024
- “A Long-Context Language Model for the Generation of Bacteriophage Genomes”, Shao 2023
- “Diff History for Neural Language Agents”, Piterbarg et al 2023
- “TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering”, Chen et al 2023
- “Positional Description Matters for Transformers Arithmetic”, Shen et al 2023
- “AnyText: Multilingual Visual Text Generation And Editing”, Tuo et al 2023
- “EELBERT: Tiny Models through Dynamic Embeddings”, Cohn et al 2023
- “ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
- “Learn Your Tokens: Word-Pooled Tokenization for Language Modeling”, Thawani et al 2023
- “Tokenizer Choice For LLM Training: Negligible or Crucial?”, Ali et al 2023
- “XVal: A Continuous Number Encoding for Large Language Models”, Golkar et al 2023
- “Think Before You Speak: Training Language Models With Pause Tokens”, Goyal et al 2023
- “Embers of Autoregression: Understanding Large Language Models Through the Problem They Are Trained to Solve”, McCoy et al 2023
- “Subwords As Skills: Tokenization for Sparse-Reward Reinforcement Learning”, Yunis et al 2023
- “PASTA: Pretrained Action-State Transformer Agents”, Boige et al 2023
- “In-Context Autoencoder for Context Compression in a Large Language Model”, Ge et al 2023
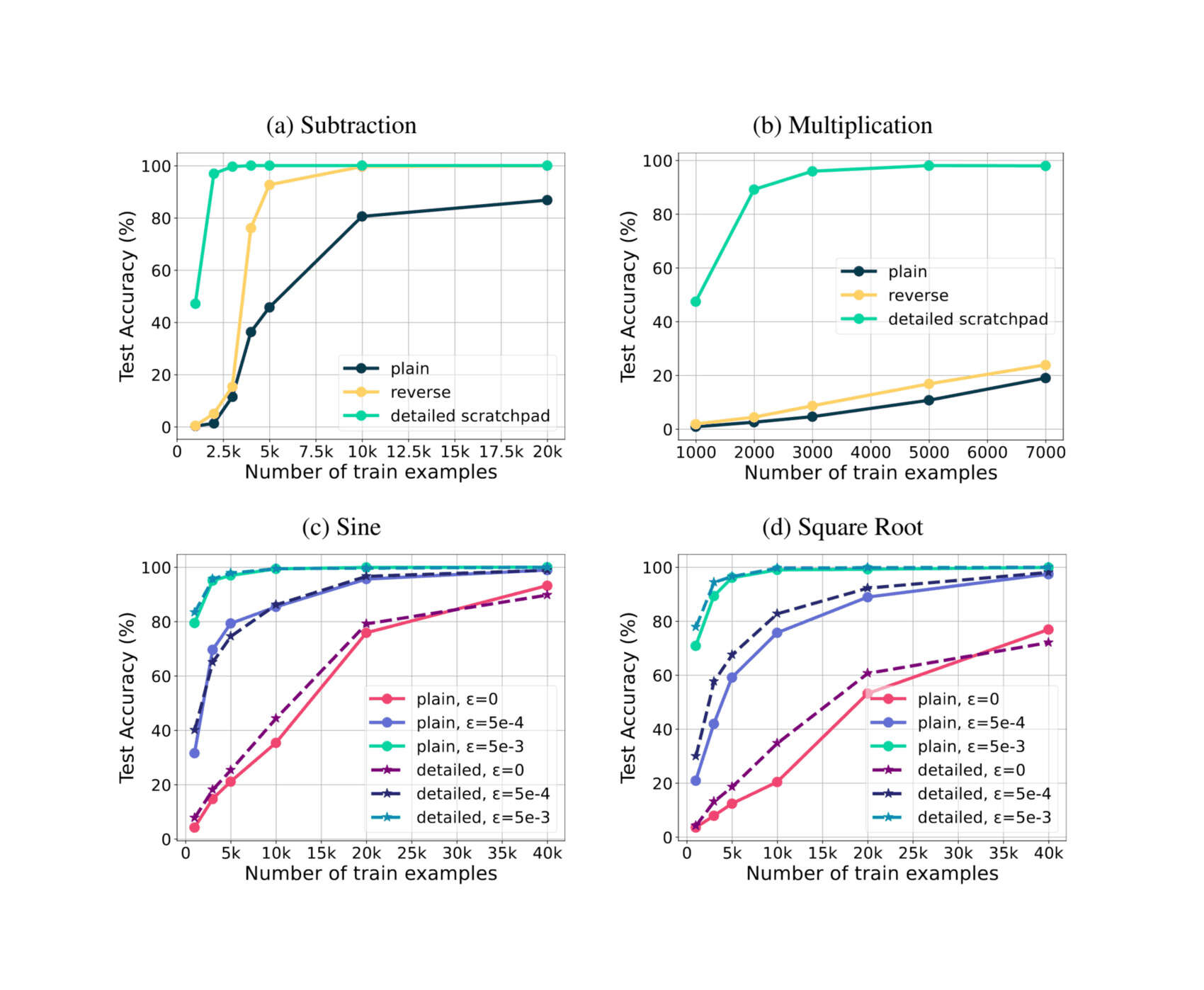
- “Teaching Arithmetic to Small Transformers”, Lee et al 2023
- “Length Generalization in Arithmetic Transformers”, Jelassi et al 2023
- “ChatGPT Is Fun, but It Is Not Funny! Humor Is Still Challenging Large Language Models”, Jentzsch & Kersting 2023
- “Bytes Are All You Need: Transformers Operating Directly On File Bytes”, Horton et al 2023
- “FERMAT: An Alternative to Accuracy for Numerical Reasoning”, Sivakumar & Moosavi 2023
- “MEGABYTE: Predicting Million-Byte Sequences With Multiscale Transformers”, Yu et al 2023
- “Evaluating Transformer Language Models on Arithmetic Operations Using Number Decomposition”, Muffo et al 2023
- “What’s AGI, and Why Are AI Experts Skeptical? ChatGPT and Other Bots Have Revived Conversations on Artificial General Intelligence. Scientists Say Algorithms Won’t Surpass You Any Time Soon”, Rogers 2023
- “BloombergGPT: A Large Language Model for Finance”, Wu et al 2023
- “How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
- “LLaMa-1: Open and Efficient Foundation Language Models”, Touvron et al 2023
- “Language Is Not All You Need: Aligning Perception With Language Models (Kosmos-1)”, Huang et al 2023
- “XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models”, Liang et al 2023
- “Language Models Are Better Than Humans at Next-Token Prediction”, Shlegeris et al 2022
- “Character-Aware Models Improve Visual Text Rendering”, Liu et al 2022
- “NPM: Nonparametric Masked Language Modeling”, Min et al 2022
- “Fast Inference from Transformers via Speculative Decoding”, Leviathan et al 2022
- “Efficient Transformers With Dynamic Token Pooling”, Nawrot et al 2022
- “Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities”, Tjandra et al 2022
- “LMentry: A Language Model Benchmark of Elementary Language Tasks”, Efrat et al 2022
- “n-Gram Is Back: Residual Learning of Neural Text Generation With n-Gram Language Model”, Li et al 2022
- “Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”, Chakrabarty et al 2022
- “DALL·E 2 Is Seeing Double: Flaws in Word-To-Concept Mapping in Text2Image Models”, Rassin et al 2022
- “Most Language Models Can Be Poets Too: An AI Writing Assistant and Constrained Text Generation Studio”, Roush et al 2022
- “Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints”, Jawahar et al 2022
- “AudioLM: a Language Modeling Approach to Audio Generation”, Borsos et al 2022
- “PIXEL: Language Modeling With Pixels”, Rust et al 2022
- “N-Grammer: Augmenting Transformers With Latent n-Grams”, Roy et al 2022
- “Forecasting Future World Events With Neural Networks”, Zou et al 2022
- “SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
- “FLOTA: An Embarrassingly Simple Method to Mitigate Und-Es-Ira-Ble Properties of Pretrained Language Model Tokenizers”, Hofmann et al 2022
- “DALL·E 2: Hierarchical Text-Conditional Image Generation With CLIP Latents § 7. Limitations and Risks”, Ramesh et al 2022 (page 16 org openai)
- “ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”, Zhu et al 2022
- “Make-A-Scene: Scene-Based Text-To-Image Generation With Human Priors”, Gafni et al 2022
- “Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words”, Feng et al 2022
- “Between Words and Characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP”, Mielke et al 2021
- “PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts”, Khashabi et al 2021
- “OCR-Free Document Understanding Transformer”, Kim et al 2021
- “What Changes Can Large-Scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-Scale Korean Generative Pretrained Transformers”, Kim et al 2021
- “Models In a Spelling Bee: Language Models Implicitly Learn the Character Composition of Tokens”, Itzhak & Levy 2021
- “Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
- “Charformer: Fast Character Transformers via Gradient-Based Subword Tokenization”, Tay et al 2021
- “ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”, Xue et al 2021
- “Robust Open-Vocabulary Translation from Visual Text Representations”, Salesky et al 2021
- “GPT-3 vs Water Cooler Trivia Participants: A Human vs Robot Showdown”, Waldoch 2021
- “CANINE: Pre-Training an Efficient Tokenization-Free Encoder for Language Representation”, Clark et al 2021
- “There Once Was a Really Bad Poet, It Was Automated but You Didn’t Know It”, Wang et al 2021
- “Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
- “Investigating the Limitations of the Transformers With Simple Arithmetic Tasks”, Nogueira et al 2021
- “Superbizarre Is Not Superb: Derivational Morphology Improves BERT’s Interpretation of Complex Words”, Hofmann et al 2021
- “Fast WordPiece Tokenization”, Song et al 2020
- “CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters”, Boukkouri et al 2020
- “Towards End-To-End In-Image Neural Machine Translation”, Mansimov et al 2020
- “Unigram LM: Byte Pair Encoding Is Suboptimal for Language Model Pretraining”, Bostrom & Durrett 2020
- “Generative Language Modeling for Automated Theorem Proving § Experiments”, Polu & Sutskever 2020 (page 11 org openai)
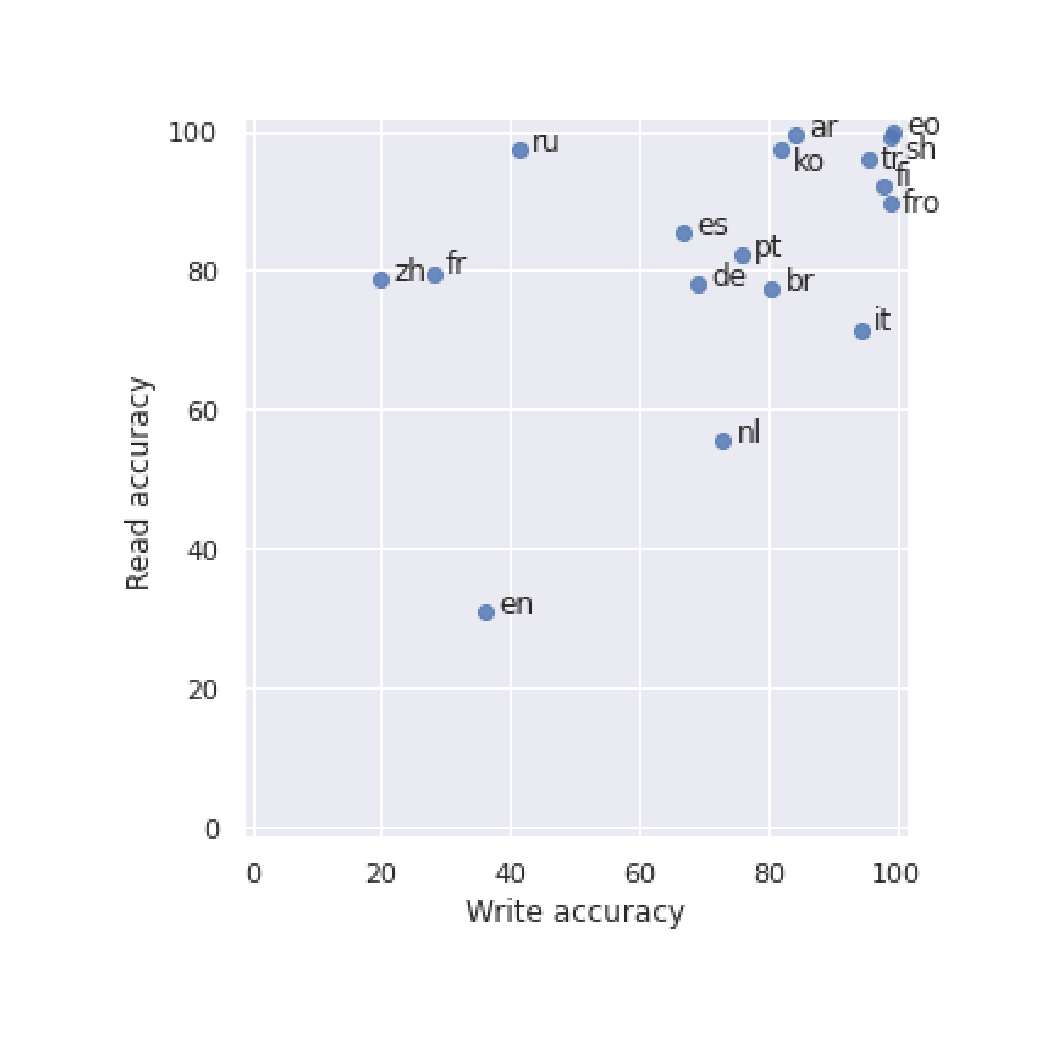
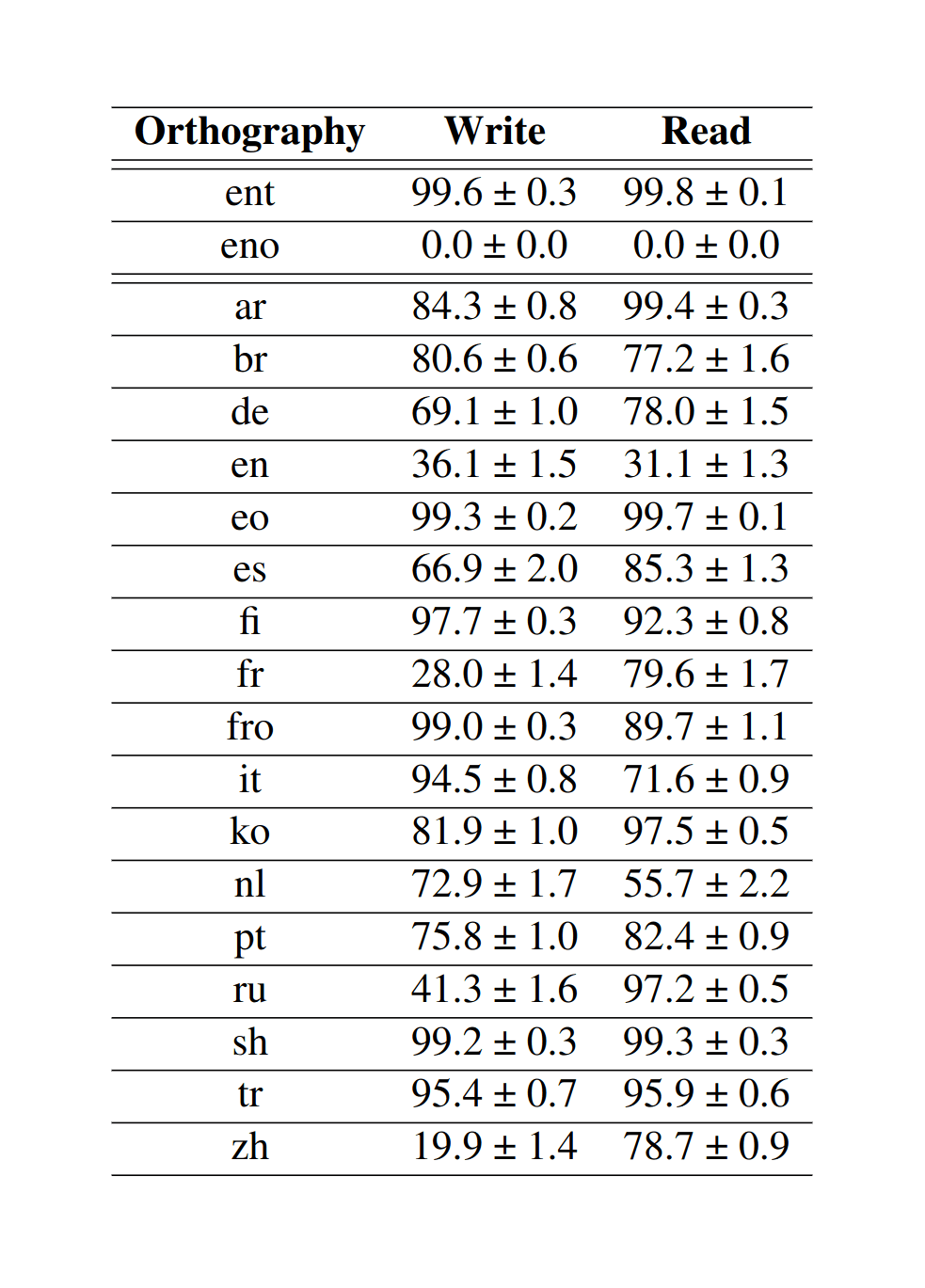
- “OTEANN: Estimating the Transparency of Orthographies With an Artificial Neural Network”, Marjou 2019
- “BPE-Dropout: Simple and Effective Subword Regularization”, Provilkov et al 2019
- “BERTRAM: Improved Word Embeddings Have Big Impact on Contextualized Model Performance”, Schick & Schütze 2019
- “Do NLP Models Know Numbers? Probing Numeracy in Embeddings”, Wallace et al 2019
- “Generating Text With Recurrent Neural Networks”, Sutskever et al 2019
- “SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing”, Kudo & Richardson 2018
- “Character-Level Language Modeling With Deeper Self-Attention”, Al-Rfou et al 2018
- “Deep-Speare: A Joint Neural Model of Poetic Language, Meter and Rhyme”, Lau et al 2018
- “GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”, Radford et al 2018 (page 5)
- “One Big Net For Everything”, Schmidhuber 2018
- “Breaking the Softmax Bottleneck: A High-Rank RNN Language Model”, Yang et al 2017
- “DeepTingle”, Khalifa et al 2017
- “Multiplicative LSTM for Sequence Modeling”, Krause et al 2016
- “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, Wu et al 2016
- “BPEs: Neural Machine Translation of Rare Words With Subword Units”, Sennrich et al 2015
- “Scaling Language Models: Methods, Analysis & Insights from Training Gopher § Table A40: Conversations Can Create the Illusion of Creativity”
- “Commas vs Integers”
- “FineWeb: Decanting the Web for the Finest Text Data at Scale”
- “The Bouba/Kiki Effect And Sound Symbolism In CLIP”
- “BPE Blues”
- “BPE Blues+”
- “The Art of Prompt Design: Prompt Boundaries and Token Healing”
- “Monitor: An AI-Driven Observability Interface”
- “A Poem Is All You Need: Jailbreaking ChatGPT, Meta & More”
- NineOfNein
- Sort By Magic
- Wikipedia
- Miscellaneous
- Bibliography
See Also
Gwern
“GPT-3 Creative Fiction”, Gwern 2020
“GPT-3 Nonfiction”, Gwern 2020
“AI Text Tokenization”, Gwern 2020
“GPT-2 Folk Music”, Gwern & Presser 2019
Links
“Llama Goes off the Rails If You Ask It for 5 Odd Numbers That Don’t Have the Letter ‘E’ in Them”, Applemoi 2025
Llama goes off the rails if you ask it for 5 odd numbers that don’t have the letter ‘E’ in them
“Tokenization Is NP-Complete”, Whittington et al 2024
“Clio: Privacy-Preserving Insights into Real-World AI Use”, Anthropic 2024
“The Structure of the Token Space for Large Language Models”, Robinson et al 2024
“When a Language Model Is Optimized for Reasoning, Does It Still Show Embers of Autoregression? An Analysis of OpenAI O1”, McCoy et al 2024
“MaskBit: Embedding-Free Image Generation via Bit Tokens”, Weber et al 2024
“A New Class of Glitch Tokens: BPE Sub-Token Artifacts”
“JPEG-LM: LLMs As Image Generators With Canonical Codec Representations”, Han et al 2024
JPEG-LM: LLMs as Image Generators with Canonical Codec Representations
“CARTE: toward Table Foundation Models”, Varoquaux 2024
“Token Erasure As a Footprint of Implicit Vocabulary Items in LLMs”, Feucht et al 2024
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs
“Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets
“Transformers Can Do Arithmetic With the Right Embeddings”, McLeish et al 2024
“From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
“Zero-Shot Tokenizer Transfer”, Minixhofer et al 2024
“Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models”, Bai et al 2024
Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models
“Fishing for Magikarp: Automatically Detecting Under-Trained Tokens in Large Language Models”, Land & Bartolo 2024
Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
“SpaceByte: Towards Deleting Tokenization from Large Language Modeling”, Slagle 2024
SpaceByte: Towards Deleting Tokenization from Large Language Modeling
“Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge”, Batsuren et al 2024
Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge
“Why Do Small Language Models Underperform? Studying Language Model Saturation via the Softmax Bottleneck”, Godey et al 2024
“Training LLMs over Neurally Compressed Text”, Lester et al 2024
“Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
“CARTE: Pretraining and Transfer for Tabular Learning”, Kim et al 2024
“Tokenization Counts: the Impact of Tokenization on Arithmetic in Frontier LLMs”, Singh & Strouse 2024
Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs
“Tasks That Language Models Don’t Learn”, Lee & Lim 2024
“Getting the Most out of Your Tokenizer for Pre-Training and Domain Adaptation”, Dagan et al 2024
Getting the most out of your tokenizer for pre-training and domain adaptation
“MambaByte: Token-Free Selective State Space Model”, Wang et al 2024
“A Long-Context Language Model for the Generation of Bacteriophage Genomes”, Shao 2023
A long-context language model for the generation of bacteriophage genomes
“Diff History for Neural Language Agents”, Piterbarg et al 2023
“TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering”, Chen et al 2023
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
“Positional Description Matters for Transformers Arithmetic”, Shen et al 2023
“AnyText: Multilingual Visual Text Generation And Editing”, Tuo et al 2023
“EELBERT: Tiny Models through Dynamic Embeddings”, Cohn et al 2023
“ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
“Learn Your Tokens: Word-Pooled Tokenization for Language Modeling”, Thawani et al 2023
Learn Your Tokens: Word-Pooled Tokenization for Language Modeling
“Tokenizer Choice For LLM Training: Negligible or Crucial?”, Ali et al 2023
“XVal: A Continuous Number Encoding for Large Language Models”, Golkar et al 2023
xVal: A Continuous Number Encoding for Large Language Models
“Think Before You Speak: Training Language Models With Pause Tokens”, Goyal et al 2023
Think before you speak: Training Language Models With Pause Tokens
“Embers of Autoregression: Understanding Large Language Models Through the Problem They Are Trained to Solve”, McCoy et al 2023
“Subwords As Skills: Tokenization for Sparse-Reward Reinforcement Learning”, Yunis et al 2023
Subwords as Skills: Tokenization for Sparse-Reward Reinforcement Learning
“PASTA: Pretrained Action-State Transformer Agents”, Boige et al 2023
“In-Context Autoencoder for Context Compression in a Large Language Model”, Ge et al 2023
In-context Autoencoder for Context Compression in a Large Language Model
“Teaching Arithmetic to Small Transformers”, Lee et al 2023
“Length Generalization in Arithmetic Transformers”, Jelassi et al 2023
“ChatGPT Is Fun, but It Is Not Funny! Humor Is Still Challenging Large Language Models”, Jentzsch & Kersting 2023
ChatGPT is fun, but it is not funny! Humor is still challenging Large Language Models
“Bytes Are All You Need: Transformers Operating Directly On File Bytes”, Horton et al 2023
Bytes Are All You Need: Transformers Operating Directly On File Bytes
“FERMAT: An Alternative to Accuracy for Numerical Reasoning”, Sivakumar & Moosavi 2023
“MEGABYTE: Predicting Million-Byte Sequences With Multiscale Transformers”, Yu et al 2023
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
“Evaluating Transformer Language Models on Arithmetic Operations Using Number Decomposition”, Muffo et al 2023
Evaluating Transformer Language Models on Arithmetic Operations Using Number Decomposition
“What’s AGI, and Why Are AI Experts Skeptical? ChatGPT and Other Bots Have Revived Conversations on Artificial General Intelligence. Scientists Say Algorithms Won’t Surpass You Any Time Soon”, Rogers 2023
“BloombergGPT: A Large Language Model for Finance”, Wu et al 2023
“How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
How well do Large Language Models perform in Arithmetic tasks?
“LLaMa-1: Open and Efficient Foundation Language Models”, Touvron et al 2023
“Language Is Not All You Need: Aligning Perception With Language Models (Kosmos-1)”, Huang et al 2023
Language Is Not All You Need: Aligning Perception with Language Models (Kosmos-1)
“XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models”, Liang et al 2023
XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models
“Language Models Are Better Than Humans at Next-Token Prediction”, Shlegeris et al 2022
Language models are better than humans at next-token prediction
“Character-Aware Models Improve Visual Text Rendering”, Liu et al 2022
“NPM: Nonparametric Masked Language Modeling”, Min et al 2022
“Fast Inference from Transformers via Speculative Decoding”, Leviathan et al 2022
“Efficient Transformers With Dynamic Token Pooling”, Nawrot et al 2022
“Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities”, Tjandra et al 2022
“LMentry: A Language Model Benchmark of Elementary Language Tasks”, Efrat et al 2022
LMentry: A Language Model Benchmark of Elementary Language Tasks
“n-Gram Is Back: Residual Learning of Neural Text Generation With n-Gram Language Model”, Li et al 2022
n-gram Is Back: Residual Learning of Neural Text Generation with n-gram Language Model
“Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”, Chakrabarty et al 2022
Help me write a poem: Instruction Tuning as a Vehicle for Collaborative Poetry Writing (CoPoet)
“DALL·E 2 Is Seeing Double: Flaws in Word-To-Concept Mapping in Text2Image Models”, Rassin et al 2022
DALL·E 2 is Seeing Double: Flaws in Word-to-Concept Mapping in Text2Image Models
“Most Language Models Can Be Poets Too: An AI Writing Assistant and Constrained Text Generation Studio”, Roush et al 2022
“Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints”, Jawahar et al 2022
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
“AudioLM: a Language Modeling Approach to Audio Generation”, Borsos et al 2022
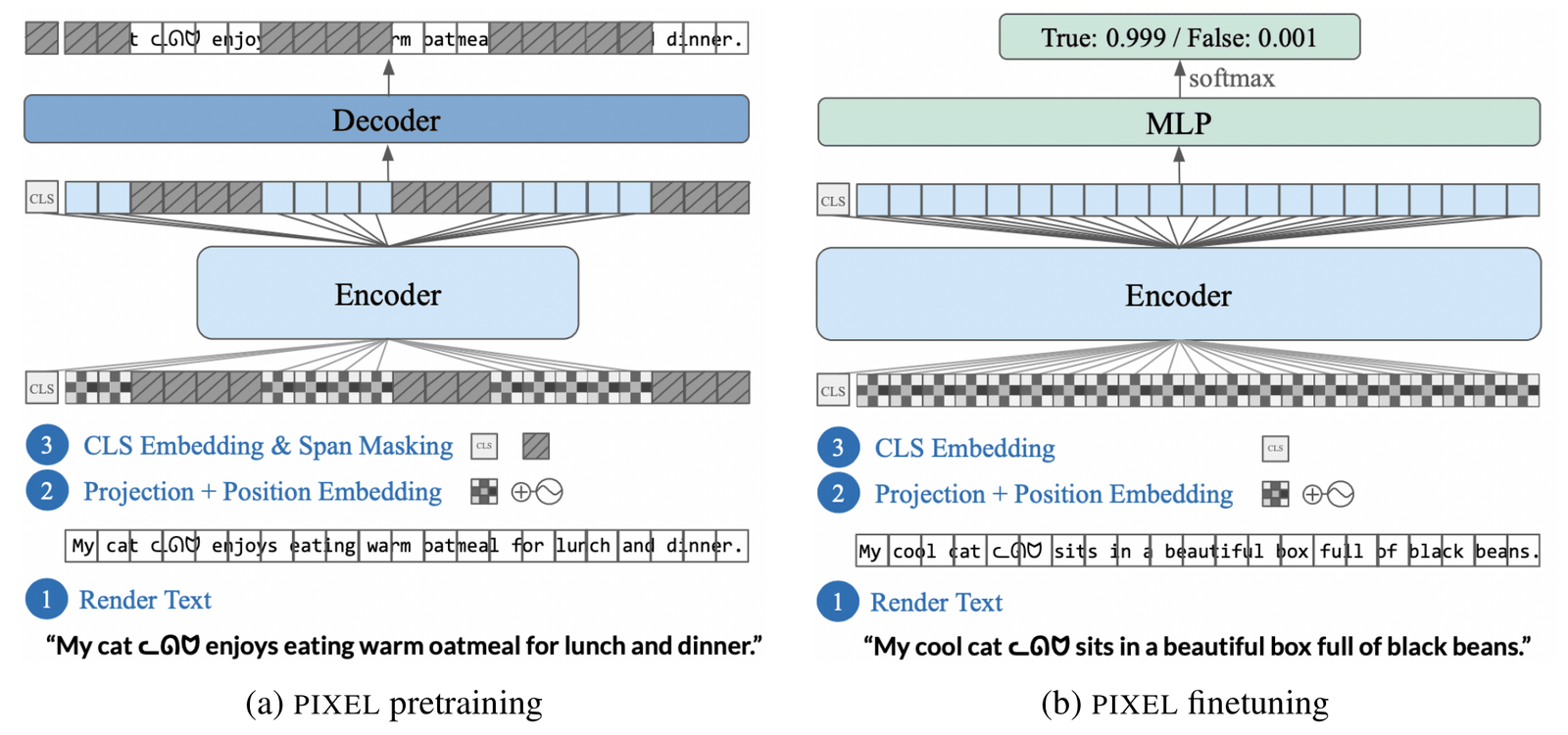
“PIXEL: Language Modeling With Pixels”, Rust et al 2022
“N-Grammer: Augmenting Transformers With Latent n-Grams”, Roy et al 2022
“Forecasting Future World Events With Neural Networks”, Zou et al 2022
“SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
SymphonyNet: Symphony Generation with Permutation Invariant Language Model
“FLOTA: An Embarrassingly Simple Method to Mitigate Und-Es-Ira-Ble Properties of Pretrained Language Model Tokenizers”, Hofmann et al 2022
“DALL·E 2: Hierarchical Text-Conditional Image Generation With CLIP Latents § 7. Limitations and Risks”, Ramesh et al 2022 (page 16 org openai)
“ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”, Zhu et al 2022
ByT5 model for massively multilingual grapheme-to-phoneme conversion
“Make-A-Scene: Scene-Based Text-To-Image Generation With Human Priors”, Gafni et al 2022
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
“Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words”, Feng et al 2022
Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words
“Between Words and Characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP”, Mielke et al 2021
Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP
“PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts”, Khashabi et al 2021
PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
“OCR-Free Document Understanding Transformer”, Kim et al 2021
“What Changes Can Large-Scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-Scale Korean Generative Pretrained Transformers”, Kim et al 2021
“Models In a Spelling Bee: Language Models Implicitly Learn the Character Composition of Tokens”, Itzhak & Levy 2021
Models In a Spelling Bee: Language Models Implicitly Learn the Character Composition of Tokens
“Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
Perceiver IO: A General Architecture for Structured Inputs & Outputs
“Charformer: Fast Character Transformers via Gradient-Based Subword Tokenization”, Tay et al 2021
Charformer: Fast Character Transformers via Gradient-based Subword Tokenization
“ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”, Xue et al 2021
ByT5: Towards a token-free future with pre-trained byte-to-byte models
“Robust Open-Vocabulary Translation from Visual Text Representations”, Salesky et al 2021
Robust Open-Vocabulary Translation from Visual Text Representations
“GPT-3 vs Water Cooler Trivia Participants: A Human vs Robot Showdown”, Waldoch 2021
GPT-3 vs Water Cooler Trivia participants: A Human vs Robot Showdown
“CANINE: Pre-Training an Efficient Tokenization-Free Encoder for Language Representation”, Clark et al 2021
CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation
“There Once Was a Really Bad Poet, It Was Automated but You Didn’t Know It”, Wang et al 2021
There Once Was a Really Bad Poet, It Was Automated but You Didn’t Know It
“Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
“Investigating the Limitations of the Transformers With Simple Arithmetic Tasks”, Nogueira et al 2021
Investigating the Limitations of the Transformers with Simple Arithmetic Tasks
“Superbizarre Is Not Superb: Derivational Morphology Improves BERT’s Interpretation of Complex Words”, Hofmann et al 2021
Superbizarre Is Not Superb: Derivational Morphology Improves BERT’s Interpretation of Complex Words
“Fast WordPiece Tokenization”, Song et al 2020
“CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters”, Boukkouri et al 2020
“Towards End-To-End In-Image Neural Machine Translation”, Mansimov et al 2020
“Unigram LM: Byte Pair Encoding Is Suboptimal for Language Model Pretraining”, Bostrom & Durrett 2020
Unigram LM: Byte Pair Encoding is Suboptimal for Language Model Pretraining
“Generative Language Modeling for Automated Theorem Proving § Experiments”, Polu & Sutskever 2020 (page 11 org openai)
Generative Language Modeling for Automated Theorem Proving § Experiments
“OTEANN: Estimating the Transparency of Orthographies With an Artificial Neural Network”, Marjou 2019
OTEANN: Estimating the Transparency of Orthographies with an Artificial Neural Network
“BPE-Dropout: Simple and Effective Subword Regularization”, Provilkov et al 2019
“BERTRAM: Improved Word Embeddings Have Big Impact on Contextualized Model Performance”, Schick & Schütze 2019
BERTRAM: Improved Word Embeddings Have Big Impact on Contextualized Model Performance
“Do NLP Models Know Numbers? Probing Numeracy in Embeddings”, Wallace et al 2019
“Generating Text With Recurrent Neural Networks”, Sutskever et al 2019
“SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing”, Kudo & Richardson 2018
“Character-Level Language Modeling With Deeper Self-Attention”, Al-Rfou et al 2018
Character-Level Language Modeling with Deeper Self-Attention
“Deep-Speare: A Joint Neural Model of Poetic Language, Meter and Rhyme”, Lau et al 2018
Deep-speare: A Joint Neural Model of Poetic Language, Meter and Rhyme
“GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”, Radford et al 2018 (page 5)
GPT-1: Improving Language Understanding by Generative Pre-Training § Model specifications
“One Big Net For Everything”, Schmidhuber 2018
“Breaking the Softmax Bottleneck: A High-Rank RNN Language Model”, Yang et al 2017
Breaking the Softmax Bottleneck: A High-Rank RNN Language Model
“DeepTingle”, Khalifa et al 2017
“Multiplicative LSTM for Sequence Modeling”, Krause et al 2016
“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, Wu et al 2016
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
“BPEs: Neural Machine Translation of Rare Words With Subword Units”, Sennrich et al 2015
BPEs: Neural Machine Translation of Rare Words with Subword Units
“Scaling Language Models: Methods, Analysis & Insights from Training Gopher § Table A40: Conversations Can Create the Illusion of Creativity”
“Commas vs Integers”
“FineWeb: Decanting the Web for the Finest Text Data at Scale”
FineWeb: decanting the web for the finest text data at scale
“The Bouba/Kiki Effect And Sound Symbolism In CLIP”
“BPE Blues”
“BPE Blues+”
“The Art of Prompt Design: Prompt Boundaries and Token Healing”
The Art of Prompt Design: Prompt Boundaries and Token Healing
“Monitor: An AI-Driven Observability Interface”
“A Poem Is All You Need: Jailbreaking ChatGPT, Meta & More”
NineOfNein
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
text-generation
transformers
neural-tokenization
Wikipedia
Miscellaneous
-
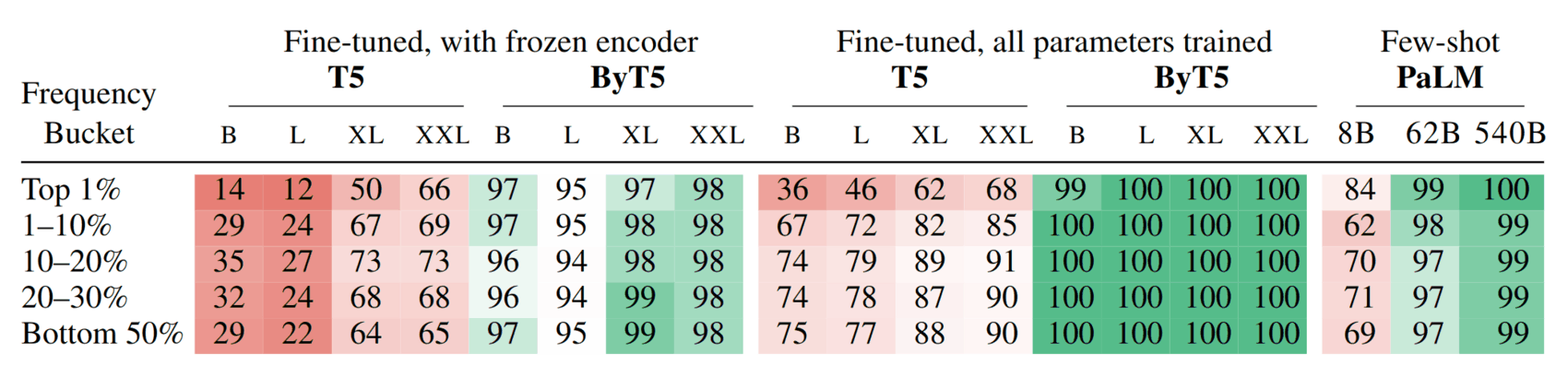
/doc/ai/nn/tokenization/2024-01-10-gwern-gpt4-usingipasoftwaretotrytounderstandatomatopun.png: -
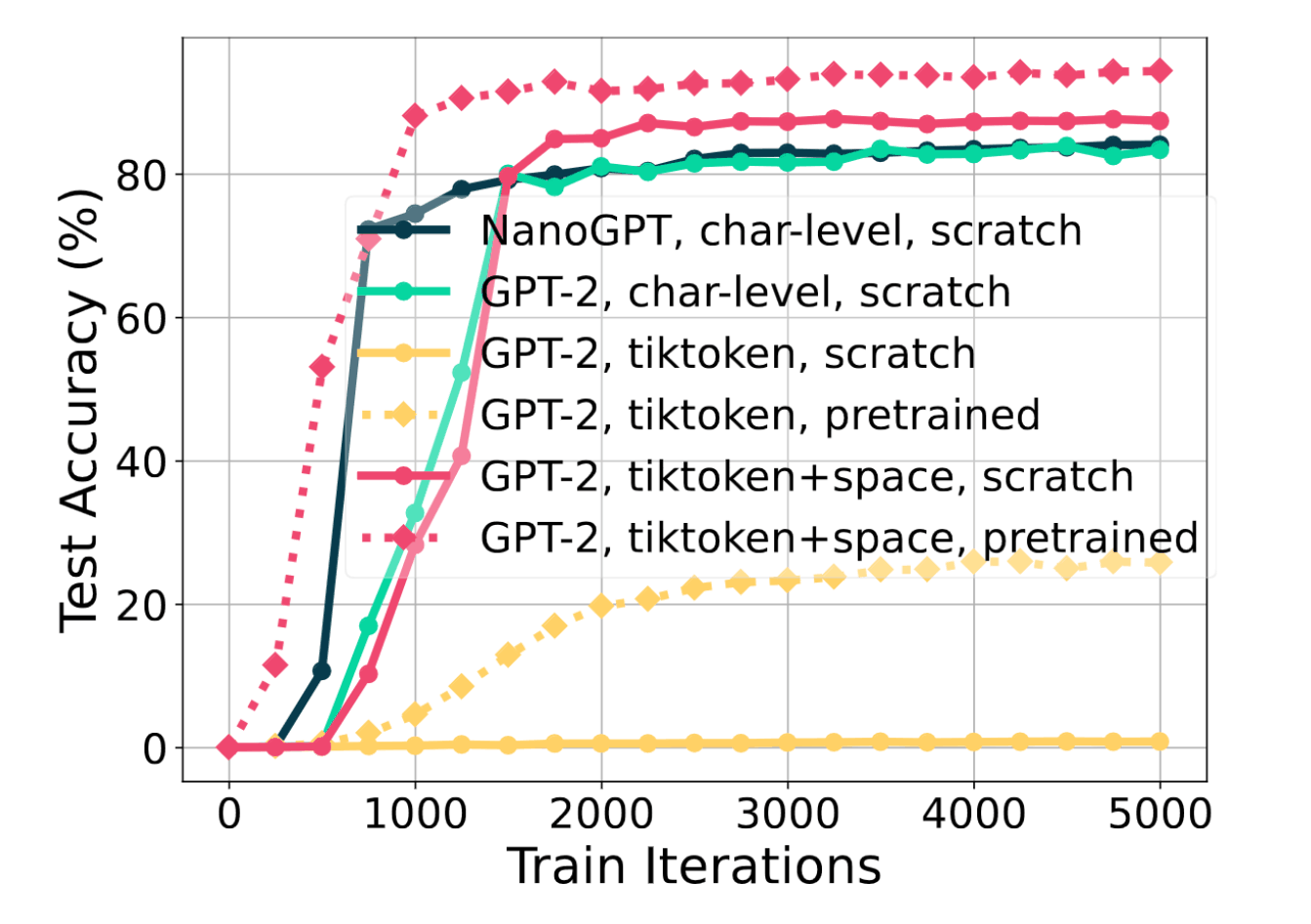
/doc/ai/nn/tokenization/2023-lee-figure20-naivebpetokenizationbadlydamagesgpt2arithmetictraining.png: -
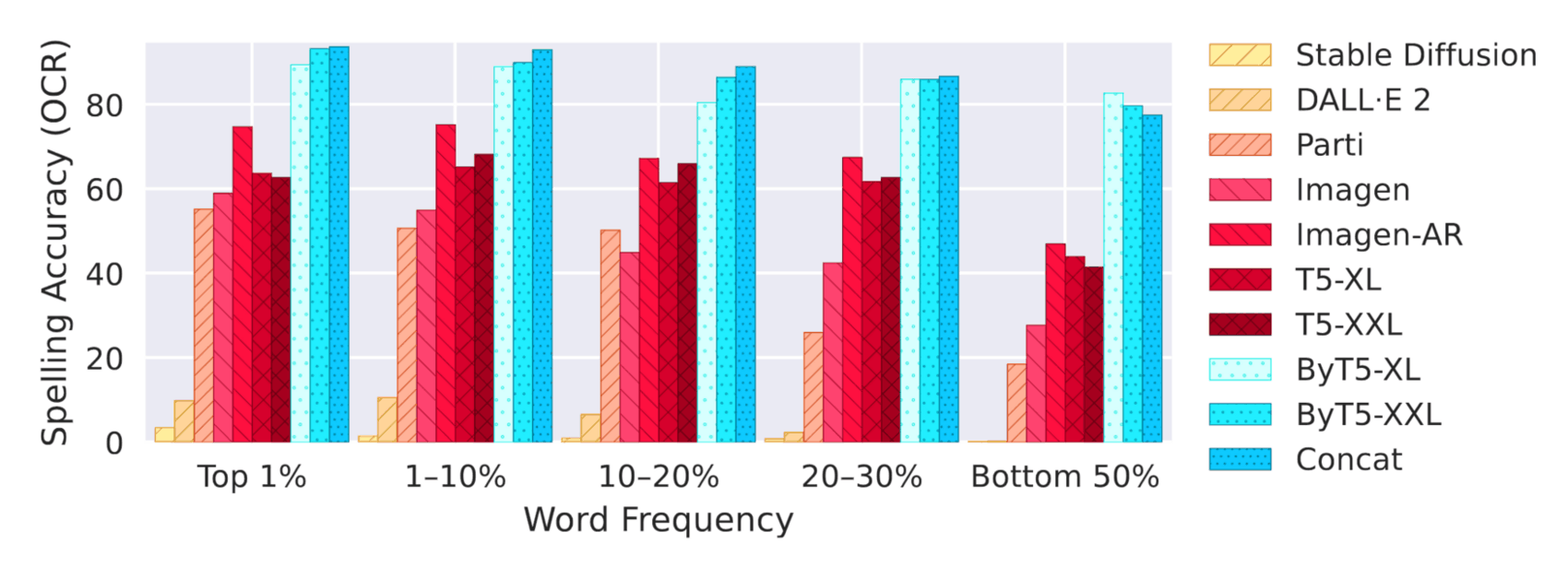
/doc/ai/nn/tokenization/2021-liu-table1-spellingtestforbyt5vst5vspalmshowsbyt5spellsmuchbetter.png: -
https://aclanthology.org/D18-1092/:View External Link:
-
https://blog.scottlogic.com/2021/08/31/a-primer-on-the-openai-api-1.html -
https://denyslinkov.medium.com/why-is-gpt-3-15-77x-more-expensive-for-certain-languages-2b19a4adc4bc: -
https://gist.github.com/moyix/ca4091f16f0b5011bfa8f3f97f705a0d: -
https://github.com/alasdairforsythe/tokenmonster/blob/main/benchmark/pretrain.md: -
https://research.google/blog/a-fast-wordpiece-tokenization-system/ -
https://www.beren.io/2023-02-04-Integer-tokenization-is-insane/: -
https://www.lesswrong.com/posts/8viQEp8KBg2QSW4Yc/solidgoldmagikarp-iii-glitch-token-archaeology: -
https://www.lesswrong.com/posts/aPeJE8bSo6rAFoLqg/solidgoldmagikarp-plus-prompt-generation -
https://www.lesswrong.com/posts/jkY6QdCfAXHJk3kea/the-petertodd-phenomenon -
https://www.reddit.com/r/ChatGPT/comments/12xai7j/spamming_the_word_stop_2300_times_or_probably_any/ -
https://www.reddit.com/r/mlscaling/comments/146rgq2/chatgpt_is_running_quantized/jnst1t8/ -
https://www.technologyreview.com/2024/05/22/1092763/openais-gpt4o-chinese-ai-data/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
-
https://arxiv.org/abs/2410.08993: “The Structure of the Token Space for Large Language Models”, -
https://arxiv.org/abs/2409.16211#bytedance: “MaskBit: Embedding-Free Image Generation via Bit Tokens”, -
https://arxiv.org/abs/2406.20086: “Token Erasure As a Footprint of Implicit Vocabulary Items in LLMs”, -
https://arxiv.org/abs/2406.18906: “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, -
https://arxiv.org/abs/2405.14838: “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, -
https://arxiv.org/abs/2405.07883: “Zero-Shot Tokenizer Transfer”, -
https://arxiv.org/abs/2404.13292: “Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge”, -
https://arxiv.org/abs/2403.17844: “Mechanistic Design and Scaling of Hybrid Architectures”, -
https://arxiv.org/abs/2402.14903: “Tokenization Counts: the Impact of Tokenization on Arithmetic in Frontier LLMs”, -
https://arxiv.org/abs/2402.11349: “Tasks That Language Models Don’t Learn”, -
https://arxiv.org/abs/2311.16465: “TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering”, -
https://arxiv.org/abs/2310.02226: “Think Before You Speak: Training Language Models With Pause Tokens”, -
https://arxiv.org/abs/2307.03381: “Teaching Arithmetic to Small Transformers”, -
https://arxiv.org/abs/2306.00238#apple: “Bytes Are All You Need: Transformers Operating Directly On File Bytes”, -
https://www.wired.com/story/what-is-artificial-general-intelligence-agi-explained/: “What’s AGI, and Why Are AI Experts Skeptical? ChatGPT and Other Bots Have Revived Conversations on Artificial General Intelligence. Scientists Say Algorithms Won’t Surpass You Any Time Soon”, -
https://arxiv.org/abs/2304.02015#alibaba: “How Well Do Large Language Models Perform in Arithmetic Tasks?”, -
https://arxiv.org/abs/2212.10562#google: “Character-Aware Models Improve Visual Text Rendering”, -
https://arxiv.org/abs/2212.01349#facebook: “NPM: Nonparametric Masked Language Modeling”, -
https://arxiv.org/abs/2210.13669: “Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”, -
https://aclanthology.org/2022.cai-1.2.pdf: “Most Language Models Can Be Poets Too: An AI Writing Assistant and Constrained Text Generation Studio”, -
https://arxiv.org/abs/2207.06991: “PIXEL: Language Modeling With Pixels”, -
https://arxiv.org/abs/2206.15474: “Forecasting Future World Events With Neural Networks”, -
https://aclanthology.org/2022.acl-short.43.pdf: “FLOTA: An Embarrassingly Simple Method to Mitigate Und-Es-Ira-Ble Properties of Pretrained Language Model Tokenizers”, -
https://arxiv.org/pdf/2204.06125#page=16&org=openai: “DALL·E 2: Hierarchical Text-Conditional Image Generation With CLIP Latents § 7. Limitations and Risks”, -
https://arxiv.org/abs/2204.03067: “ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”, -
https://arxiv.org/abs/2203.13131#facebook: “Make-A-Scene: Scene-Based Text-To-Image Generation With Human Priors”, -
https://arxiv.org/abs/2108.11193: “Models In a Spelling Bee: Language Models Implicitly Learn the Character Composition of Tokens”, -
https://arxiv.org/abs/2107.14795#deepmind: “Perceiver IO: A General Architecture for Structured Inputs & Outputs”, -
https://arxiv.org/abs/2106.12672#google: “Charformer: Fast Character Transformers via Gradient-Based Subword Tokenization”, -
https://arxiv.org/abs/2105.13626#google: “ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”, -
https://arxiv.org/abs/2103.03206#deepmind: “Perceiver: General Perception With Iterative Attention”, -
https://arxiv.org/abs/2012.15524#google: “Fast WordPiece Tokenization”, -
https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf#page=5: “GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”,