GPT-2 Folk Music
Generating Irish/folk/classical music in ABC format using GPT-2-117M, with good results.
In November 2019, I experimented with training a GPT-2 neural net model to generate folk music in the high-level ABC music text format, following previous work in 2016 which used a char-RNN trained on a ‘The Session’ dataset. A GPT-2 hypothetically can improve on an RNN by better global coherence & copying of patterns, without problems with the hidden-state bottleneck.
I encountered problems with the standard GPT-2 model’s encoding of text which damaged results, but after fixing that, I successfully trained it on n = 205,304 ABC music pieces taken from The Session & ABCnotation.com. The resulting music samples are in my opinion quite pleasant. (A similar model was later retrained by Geerlings & Meroño-2020.)
The ABC folk model & dataset are available for download, and I provide for listening selected music samples as well as medleys of random samples from throughout training.
We followed the ABC folk model with an ABC-MIDI model: a dataset of 453k ABC pieces decompiled from MIDI pieces, which fit into GPT-2-117M with an expanded context window when trained on TPUs. The MIDI pieces are far more diverse and challenging, and GPT-2 underfits and struggles to produce valid samples but when sampling succeeds, it can generate even better musical samples.
Compact text—perfect for NNs. Back in 2015–2016, Bob L. Sturm experimented with generating Irish folk music using a char-RNN trained on a corpus of folk music written from The Session in a high-level musical format called “ABC notation”. While ABC notation is written in ASCII, it supports many complex features, and it has been adopted widely by folk musicians and hundreds of thousands of pieces written/transcribed in it.
GPT-2-117M
Background: Folk-RNN
Prior success with char-RNNs. Sturm et al scraped ~40k ABC files from The Session and trained a Theano char-RNN called “folk-RNN”, putting the code & data online, and providing a web interface for generation. In addition to the various research publications, Sturm has also written many blog posts evaluating folk-RNN pieces, such as how well they’re played by human musicians.
Transformers?
DL progress. 2015 was a long time ago, however, and DL has seen a paradigm shift in sequence modeling away from char-RNNs to CNNs and attention-based Transformer models—most famously, GPT-2. Google Magenta’s Music Transformer ( et al 2018) with style control & OpenAI’s Sparse Transformer-based MuseNet have both demonstrated excellent results in music composition at various timescales/formats, and interesting features like mixing genres.
GPT-2: a perfect match. While messing around with GPT-2-based preference learning in late October 2019, I became curious if folk-RNN could be improved by simply throwing one of the GPT-2 models at it. (Not the large ones, of course, which would overfit far too easily or hadn’t been released yet, but GPT-2-117M.) GPT-2 is unable to model raw WAV audio, or MIDI, because a meaningful musical piece is a WAV sequence of hundreds of thousands to millions of symbols long, and a MIDI piece is tens of thousands of symbols long, which far exceed GPT-2’s small context window (but see later), and why OpenAI used Sparse Transformers for its MIDI generation, as Sparse Transformers can scale to text with tens of thousands of characters. However, the high-level notation of ABC pieces means they fit just fine into the GPT-2 window.
I had avoided doing anything music with GPT-2, focusing on my poetry generation instead, because I assumed OpenAI would be doing a MuseNet followup, but months later, they’d done nothing further, and when I inquired, I got the impression that their music projects were over. So why not?
As for why repeat Sturm’s project—there were two possible advantages to using GPT-2-117M:
-
improved global coherency:
I thought the Transformer might work particularly well on ABC format, because RNNs suffer from persistent ‘forgetting’ issues, where it’s difficult for the RNN to persist its memory of past generated sequences, making it hard for an RNN to repeat a theme with variants, while a GPT-2 Transformer has a context window of 1,024 BPEs—much longer than almost every ABC piece—and so is able to ‘see’ the entire piece simultaneously while generating the next note
-
English metadata understanding:
The English pretraining could potentially help by providing semantic understanding of eg. the ABC metadata, such as the difference between two pieces titled a ‘jig’ versus a ‘waltz’, or the pseudo-natural-language-ness of the ABC format as a whole.
ABC Data
The Session
Pipeline: ABC → MIDI → WAV. So I did apt-get install abcmidi timidity1 to get the CLI tools to do ABC → MIDI → WAV (respectively) and downloaded the folk-RNN repo with its data files.
The data comes in several formats, for their experiments in changing the notation. I used the original format, with n = 48,064 songs.
The data needed processing for GPT-2 as follows:
-
there was stray HTML (
</html>) which had to be removed.I used search-and-replace, and reported the issue.
-
abc2midirequires every song to have an integer identifier, eg.X: 48064, to be a valid ABC file which it can compile to MIDI.I used an Emacs macro (which can increment an integer 1–48,064) to insert a
X: $Nbefore eachT:title line, but in retrospect, I could have simply used another search-and-replace to insertX: 1in front of each piece—it’s not like the ID has to be unique, we’re just satisfyingabc2midiwhich is a bit picky. -
as usual for any neural model like char-RNN or GPT-2, it is important to insert
<|endoftext|>markers where relevant, so it understands how to generate separate pieces and avoids ‘run on’.I used search-and-replace.
This yielded 14MB of text to train on, and is converted to NPZ as usual.
Training
First Model
Because the Session corpus was so small (just 14MB), I used the smallest available GPT-2, GPT-2-117M to train on, and standard settings to train on one of my 1080tis:
CUDA_VISIBLE_DEVICES=0 PYTHONPATH=src ./train.py --dataset thesessions-irishabc.txt.npz
--batch_size 11 --model_name irish --save_every 4000 --sample_every 500 --learning_rate 0.0001
--run_name irish --memory_saving_gradients --noise 0.01 --val_every 500Straightforward success. Training was fairly easy, taking just a few days at most to train down to a loss of 0.46 (9742 steps at minibatch n = 5), and I killed it on 2019-10-21 and looked at the random samples. They struck me as pretty good, aside from generated pieces often having the same title repeatedly, which apparently was due to The Session posting multiple transcriptions of the same piece, so the model picked up on that and would generate variants on the same theme. Sturm highlighted a few and did some more in-depth commentary on them, with a mixed evaluation, concluding “So of the five transcriptions above, two are plausible. The polka is actually pretty good! All titles by GPT-2 are plagiarized, but I haven’t found much plagiarism in the tunes themselves.”
Some datasets are invalid ABC. I was worried about plagiarism and thought ~0.40 would be safe, but it seemed the music itself was still far from being copied, so I considered further training. The additional processed versions of The Session that Sturm et al had made seemed like a target, but caused problems when I simply concatenated them in, and I soon discovered why abc2midi now thought all the samples were broken:
allabcwrepeats_parsed_wot: This is version 3 of the dataset from thesession.org. In this version, we transpose all tunes to have the root C, transpose them all to have the root C#, remove the titles, and make new mode tokens,K:maj,K:min,K:dor, andK:mix. There are over 46,000 transcriptions here.
This turns out to be a problem: K:maj, K:min, K:dor, K:mix all break abc2midi! So I did additional search-and-replace to transform them into valid key signatures like K: Cmaj, K: Cmin, K: Cdor, or K: Cmix.
Balancing imitation & plagiarism. Retraining, I discovered 0.40 was far from converged, and with another 13k steps, it could go down to <0.09. However, checking random samples by hand, the textual overlap with The Session became particularly large once the loss reaches ~0.09 (note that it was not ‘overfitting’ in the standard sense, since the loss was still decreasing on the validation set), so I backed off to a model with ~0.13 loss. This seems to be high-quality without gross plagiarism.
Spaceless Model
While training a GPT-2-117M on a folk music corpus written in ABC format, persistent syntax errors kept being generated by an otherwise-high-quality model: random spaces would be generated, rendering a music piece either erroneous or lower-quality. Why? It seems to be some issue with the GPT BPE encoder handling of spaces which makes it difficult to emit the right space-separated characters. We found that ABC does not actually require spaces, and we simply removed all spaces from the corpus—noticeably improving quality of generated pieces.
I began using that model for the preference learning work, where I found that preference learning seemed to improve music more than the poetry, so I began focusing on the music.
Anomaly: permanent space-related syntax errors. Puzzlingly, no matter how many ratings I added, and despite the low loss, the generated samples would persistently have basic, blatant syntax errors involving spaces; abc2midi would often warn or even error out on a piece which could be easily fixed by hand by simply removing a few spaces. This was wasting my time during rating, since I couldn’t pick samples with syntax problems (even if they’d otherwise sound good) because I didn’t want to reinforce generation of invalid samples, and also while generating music.
Discussing it with Shawn Presser, who I was working with simultaneously to train GPT-2-1.5b on poetry, he pointed out that some people, like Nostalgebraist had some frustrating problems with the standard GPT-2 BPE encoding.
GPT-2 generates space-delimited word fragments. To explain what BPE is and why it might be a bad thing for ABC notation: GPT-2 doesn’t just feed in raw characters like a char-RNN does, because that makes every input extremely long. Instead, it tries to ‘chunk’ them into something in-between character-sized and word-sized, to get the best of both worlds, a way of writing text where common words are a single symbol but rare words can still be expressed as a couple symbols rather than deleted entirely like word-based encodings must; however, since the default model is trained on English text, chunking is done assuming normal English whitespace, like spaces between words.
Nostalgebraist notes that the actual BPE implementation used is weird and doesn’t act as you’d expect, especially when spaces are involved. So Presser wondered if GPT-2 couldn’t express the syntactically-correct text sans spaces, and that is why the errors were there and stubbornly persisted despite hundreds of ratings which told GPT-2 to stop doing that already.
Workaround—spaces optional! Checking, the ABC format apparently does not require spaces. They are only there for the convenience of humans reading & writing ABC. Aside from the metadata fields, if you delete all spaces, the music should be the same. I was surprised, but this seemed to be true. (Presser did some experiments with creating a brand-new BPE tailored to ABC, and while this would have reduced the BPE size of ABC pieces by >33%, I figured that all the ABC pieces fit into the GPT-2 window anyway and it wasn’t worth the hassle now that we had diagnosed & worked around the problem. He also did some experiments in generating video game style music via ABC: he prompted it with chords, and then switched from the default piano instruments/sound samples used by TiMidity++ to instruments like harps for a fantasy feel.)
So, I deleted the spaces with a simple tr -d ' ', re-encoded to NPZ, and retrained the first model to create a new ‘spaceless’ model. This required another few days to re-converge to ~0.13.
The spaceless corpus fixed the invalid-ABC problem, and the new model regularly generated ABC samples that triggered neither warnings nor errors, and Presser swore that the perceptual quality was much higher.
Combined Model: The Session + ABCnotation.com
More dakka (data). Presser was interested in expanding the repertoire beyond The Session and began looking at ABC databases. The biggest by far appeared to be ABCnotation.com, which had n = 290,000 pieces. He scraped a random half of them, for n = 157,240 total, and I combined them with The Session duplicated dataset, for a total n = 308,280 (n = 205,304 unique; 81MB).
Simplifying to match The Session ABC. ABCnotation.com pieces are much more diverse in formatting & metadata than The Session. To homogenize them, I ran all the pieces through abc2abc, and then I deleted some metadata fields that struck me as excessive—commentary, discussions about how to play a piece, sources, authors of the transcription, that sort of thing, which greatly inflated the loss of the combined dataset compared to the spaceless model. (In total, I filtered out abc2abc-generated warnings starting with %, and B:/D:/F:/N:/O:/S:/Z:/w: metadata.) It would have been nice if the metadata had included genre tags for greater control of conditional pieces, akin to my author-based control for GPT-2 or char-RNN poetry, a technique demonstrated at scale by CTRL using explicit Reddit metadata, and et al 2019 using autoencoders to do unsupervised learning of musical features which implicitly covers genre, but alas! We’ll have to stick with the basics like title/key/meter.
This required a full week of training or 168810 steps (1–7 Dec), down to a higher loss (as expected) but still on the edge of plagiarism:
Examples of generated ABC (note the lack of spaces):
X:1
T:AlongtheMourneShore
M:3/4
L:1/8
K:G
DGA|"G"B3AG2|"Bm"(dB3)AB|"Em"(BG)(AG)GD|"C"E3G(3(EDC)|
"G"D3GB2|"Bm"D3GB2|"Em"(dc3)(BG)|"D7"B3(DGA)|!
"G"B3AG2|"Bm"(dB3)AB|"Em"(BG)(AG)GD|"C"E3G(ED/C/)|
"G"D3GB2|"Bm"D3GB2|"C"c3/d/"D7"BA(GF)|"G"G3:|!X:1
T:ElChestrinDimmelsack-PolkaCF(pk07594)
T:HannyChristen.Bd.VBaselII,Jura.S.21(pk07594)orig.C,F
R:Polka
M:2/4
L:1/16
K:C
"C"GEcGecGE|"G7"FAdAf2d2|BdgdfdBG|"C"ceGecAGE|GEcGecGE|"Dm"FAcfAdAF|"C"EGce"G7"gfdf|"C"e2c2c2z2:|
"G7"GBdfedcB|"C"cegc'a2ge|"G7"f2dBG2ef|"C"gecGE2cc|"G7"GBdfedcB|"C"cegc'a2ge|"G7"f2dBG2ed|"C"c2e2c2z2:|
K:F
|:"F"aca2fac2|"C7"Bgg2G3F|EGcegbeg|"F"facfAcFA|caA2caG2|FAcfabc'a|
"C7"bgec=Bcde|1"F"f2agf2z2:|2"F"X:6
T:PolkaEbBbAb(5letras)cf.CGF5-Parts
P:ABAC
M:2/4
L:1/16
K:EbmFisch
[P:A]"Eb"B2BGe2eB|"Ab"c2cAF3E|"Bb7"DB=A^CD2D2|"Eb"EedcB4|B2BGe2eB|
"Ab"c2cAF3E|"Bb7"DB=A^CD2D2|"Eb"E4z2"_fine"z2||[P:B][K:Bbmaj]"Bb"d4f4|f2edc2B2|
"F7"cdcBA2A2|"Bb"cdBAG4|"Eb"d4f4|f2edcdcB|
"F7"cdcBA4|"Bb"B2B2B2B2||[P:C][K:Abmaj]"Ab"EACAE2c2|c3BA3B|
"Eb7"GeGeG2d2|d3c=BGFE|"Ab"ACEAE2c2|c3BA2B2|
"Eb7"GeGfGgBa|"Ab"aaa2a2z2||[P:D][K:Ebmaj]"Bb7"AGFdc3=B|"Eb"BeGBe4|"Bb7"B2BF"Eb"G2E2|"Bb7"FGABc4|
"Bb7"AGFdc3=B|"Eb"BeGBe4|"Bb7"B2B2e3d|"Eb"e3cBcBA|"Ab"AAAAA2e2|]Last example rendered as a score:

Score for “PolkaEbBbAb(5letras)cf.CGF5-Parts” (an ABC music sample generated by GPT-2-117M trained on a combined ABC dataset)
Samples
An ABC sample is not playable on its own; it must be converted to MIDI, and then the MIDI can be played. If one is looking at individual samples being generated by the model, a quick CLI way to play and then dump to an OGG Vorbis file might be:
xclip -o | abc2midi - -o /dev/stdout | \
timidity -A110 -
TARGET="`today`-thelonelyfireside.wav"; xclip -o | abc2midi - -o /dev/stdout | \
timidity -A110 - -Ow -o "$TARGET" && oggenc -q0 "$TARGET"Extracting multiple ABC samples, converting, and merging into a single long piece of music is somewhat more challenging, and I reused parts of my preference-learning rating script for that.
First Model Samples
-
GPT-2-117M random samples, first model trained on Session (2019-10-21):
-
"Paddywhack" generated title & sample (2019-10-22): -
"The Bank of Turf" sample (2019-10-22): -
"Hickey's Tune" sample (2019-10-23): -
"The Loon and his Quine" sample (2019-10-29): -
"The Atlantic Roar" sample (2019-10-30): -
"The Lonely Fireside" sample (2019-10-30): -
"The Marine" sample (2019-10-31): -
"Whiskey Before Breakfast" sample (2019-10-31): -
"The Flogging" sample (2019-11-01): -
"Banks of the Allan" sample (2019-11-03): -
"A Short Journey" sample (2019-11-04):
Spaceless Model Samples
-
100 random samples from spaceless Session GPT-2-117M (2019-11-08):
-
50 random samples (2019-11-09):
-
50 random samples, but with top-p = 0.99 to maximize diversity of samples (2019-11-09):
-
"#127512" sample (2019-11-14):
I enjoyed the model’s renditions of the “Yn Bollan Bane” jig when I came across it, and so I used conditional generation to generate 50 variations on it:
Combined Model Samples
-
100 random samples from combined GPT-2-117M:</figcaption
> -
"Invereshie's House" sample (2019-12-04): -
"FaroeRum" sample (2020-01-25):
Results
I am pleased with the final generated music; the spaceless & ABCnotation.com changes definitely improved over the original.
Smaller = better (for now). In retrospect, the use of GPT-2-117M was not necessary. It was so large that overfitting/plagiarism was a concern even with the combined dataset, and the English pretraining was largely useless—all of the generated titles I checked were copied from the training data, and I didn’t observe any interesting new ones. The GPT-2 BPE encoding also proved to be a problem in the end; generating a BPE specifically for an ABC corpus would have avoided that and probably also have improved learning. A smaller GPT-2 with a customized BPE (fewer parameters & attention heads, but more layers, I think would be better) would have trained much faster & probably give similar or better results.
Transformers = better copying + coherence? Qualitatively, I feel like the pieces have a different feel from char-RNN pieces, in their ability to repeat themes & motifs, and they also seem to have a much better ability to come to an ending, instead of meandering on indefinitely as char-RNN things have a tendency to do (even when trained on corpuses with clear end-of-text delimiters), perhaps because it’s easier for a Transformer to ‘count’ and know when a piece has reached a reasonable length, while a char-RNN forgets where it is. Overall, I’d call it a success.
Generating MIDI With 10k–30k Context Windows
To expand the ABC GPT-2 model to cover a wider variety of musical genres, I turn to the next-most compact widespread music encoding format: MIDI. There are hundreds of thousands of MIDIs which can be decompiled to ABC format, averaging ~10k BPEs—within GPT-2-117M’s feasible context window when trained on TPUs (which permit training of context windows up to 30k wide).
We compile the ABC from before and 2 large MIDI datasets, and convert to ABC, yielding ~453k usable ABC-MIDI musical files (~5.1GB of text). We trained January–April 2020 on our TPU swarm (with many interruptions), achieving a final loss of ~0.2 (underfit).
Sampling from the final model is hit-or-miss as it is prone to the likelihood repetition trap and it generates instruments one-by-one so it is common for instruments to be cut off or otherwise broken during sampling (indicating that sampling is increasingly a bigger problem than training for long-range sequence modeling). However, successful pieces are possible, and are musically far more diverse than the folk ABC corpus, with many pleasingly complex samples.
MIDI: hard, but not too hard? The logical next step from generating short ABC folk tunes is to generate music in general. Since ABC is not much used outside folk music, there are no good large ABC corpuses appropriate for this. Raw music is infeasible at the moment: things like WaveNet can generate excellent raw audio WAVs like musical notes, but the model sizes prohibit ‘seeing’ more than a few seconds at most, making them capable of playing musical scores fed to them, but not of higher-level composing—struggling to pass more than ~10s even with sophisticated approaches. So you could have a GPT-2 generating ABC which is fed into a WaveNet CNN, creating what sounds like real instruments playing real music, but you couldn’t have a single NN doing it all. Intermediate, more powerful than ABC but also not as demanding as raw audio generation, would be generating MIDI.
Binary MIDI → text ABC. We can’t generate raw MIDI since that’s a binary file format which doesn’t play well with most GPT-2 implementations (although there is nothing in principle stopping operation on full binary bytes rather than text bytes). What if we create a text encoding for MIDI and convert? The most straightforward representation, the piano roll, represents MIDI as 128 distinct instruments per timestep (almost all always silent), which leads to a hopelessly enormous sparse matrix. There are several available tools for encoding MIDI more directly than piano rolls, and one of them turns out to be ABC itself!
ABC-MIDI: still too long for GPT-2… The ABC-MIDI encodings are also relatively short. Checking with wc -w, MIDI files typically range in size from 10–50k characters equivalent; even with BPEs potentially saving some space (it’s ~10.7k BPEs2 per MIDI), GPT-2 simply cannot handle this sort of sequence (with many important long-range dependencies) with its standard context window of 1,024 tokens, because it would only be able to see less than a tenth of the music file at a time and it would be completely blind to the rest of it, since it has no memory. If you tried, it would not sound nearly as good as the ABC pieces above, because it would be unable to do all the nifty repetition-with-variation of melodies, overall thematic structure with beginnings & endings etc; instead, it would probably ramble around, generating plausible music which, however, never goes anywhere and just sort of ends. And, as anyone knows, GPT-2 does not scale to larger attention windows as self-attention is quadratic in the window length (𝒪(l2 · d)), and 1,024 is already pushing it for training, motivating the search for new architectures.3
More Dakka
Unless we use brute force. However, when training various GPT-2-1.5b models on our TPU swarm using the TPU research credits granted to us by Google’s TensorFlow Research Cloud Program (TRC), we noticed that a TPU can fit a model which uses up to 300GB VRAM before crashing.4 300GB—that’s quite a lot. What could you do with that? How bad exactly is GPT-2’s scaling…? Quadratic (𝒪(l2)) ≠ exponential (𝒪(2l)): if you have some good hardware available, you may be able to push it quite far.5
TPUs can train 30k context windows! We tried GPT-2-117M and it turned out a context window of 10,000 worked! Then we tried 12.5k, 15k, 20k, & 30k, and they all worked.6 (For comparison, Reformer generated great excitement for being able to scale up to 64k windows on single GPUs.) These are wide enough to train ABC-MIDI files, and we could even generate small text-encoded images (since 30k = 1732). 30k is slow, but not hopelessly slow, as with GPT-2-117M, we get 4 training steps in 2700 seconds (n = 1). A swarm of TPUs, like >100, would be able to train on a large corpus in just a few wallclock days. The memory usages are considerable, but not beyond the TPU:
-
12.5k = 45GB backprop
-
15k = 75GB backprop
-
20k = 112GB backprop
-
30k = 280GB backprop
When are 30k context windows useful? For reusing pretrained GPT-2. So, it can be done, but should it be done? Is this more than just a parlor trick reminding us that exponential ≠ quadratic? For the most part, it seems like anyone in need of big context windows is probably better off not renting all these TPUs to train a GPT-2 with 30k context windows, and using one of the many alternatives for long-range dependencies, like Reformer or Compressive Transformers or Sparse Transformers or dynamic convolutions or… But it might be useful in two cases: where one has a model already fully trained, and can do a final finetuning training phase on the original corpus to pick up long-range dependencies, since it’s still feasible to generate with wide context windows on commodity hardware; and where one needs the fully-trained model because the transfer learning is vital, and training one of the alternatives from scratch would nevertheless deliver inferior results. (At least as of 2020-01-30, I know of no publicly-released trained models for any of those alternatives architectures which approach the power of GPT-2-1.5b or T5 etc—they are all trained on much smaller datasets.)
MIDI Dataset
To get enough MIDIs to be worth training on, I combined 3 MIDI datasets:
-
The Sessions +
abcnotation.com(our partial scrape), described above -
The Lakh MIDI dataset is a collection of 176,581 unique MIDI files, 45,129 of which have been matched and aligned to entries in the Million Song Dataset…
LMD-full: The full collection of 176,581 deduped MIDI files. -
MIDI Dataset (Composing.ai)
The entire dataset, gzipped, can be downloaded at
https://drive.google.com/file/d/0B4wY8oEgAUnjX3NzSUJCNVZHbmc/view.The directory structure correspond to the sources on the Internet from which we grabbed the MIDI files. We deduplicated the dataset and the resulting collection has 77,153 songs.
-
Big_Data_Set: “The Largest MIDI Collection on the Internet” -
cariart: Ben Burgraff’s Midi Collection -
download-midi: Pop and Rock genres from DOWNLOAD-MIDI.COM -
Guitar_midkar.com_MIDIRip: midkar.com -
ics: Dan Hirschberg at University of California, Irvine -
lmd_matched: Straight from the LMD-matched dataset from the Lakh project -
TV_Themes_www.tv-timewarp.co.uk_MIDIRip: (Now defunct) TV Timewarp
-
(I did not use midi_man’s 137k collection, as I only learned about it much later.)
Combined, this yields 537,594 MIDI files (~9GB).
Converting MIDI to ABC
Need compact text versions of MIDIs. The problem with raw MIDI files is that they are binary, and not textual. The codebase does not support binary inputs as far as we know, and in any case, text is always much easier to inspect and work with. There are textual formats for MIDI, like hex encoding, and one can use generic binary → text encodings like Base64, but I was not too satisfied with them: when I tried them, they often blew up the character count greatly, and even 30k context would not be enough.
ABC works well enough. Ironically, ABC turns out to be the answer! The ABC tools ship with midi2abc, which is the inverse of abc2midi, and while it warns that it is a lossy translator, after listening to a few dozen, I had to say that it does a good job overall. It also generates ABC files which are similar in size to the original MIDI files. (I think that whatever midi2abc loses in having to potentially laboriously encode MIDI constructs, it makes up in being able to take shortcuts using ABC’s higher-level music constructs.) The weaknesses of midi2abc is that it: loses volume control, doesn’t work well on some rock tracks (drums/guitars are hollowed out), doesn’t successfully compile many MIDI files (leaving empty or extremely short ABC files), and there are occasional pathological examples (eg. one 44kb MIDI decompiled to a 3.4GB ABC file—some exponential blowup?). However, the first two are relatively minor, and the third can be tamed by simply dropping ABC output past 300kb (as hardly any non-pathological MIDI files compiled to >300kb).
Data cleaning. In converting the files, we want to avoid excessive use of newlines (-bpol 999999), we want to delete various warnings or error lines, we want to filter comments starting with '^% '—which take up a ton of space and often are just lyrics—and then delete spaces in non-MIDI-directive (^%%) lines per the ‘spaceless’ model above. The shell pipeline:
## delete odd trash files in LMD/Composing.ai
find . -type f -name '\._*' -delete
## clean up conversions from any previous runs
find . -type f -name "*.mid.abc" -delete
function convertMidi2Abc() { midi2abc -bpl 999999 -nogr "$@" | \
grep -E -v -e '^% ' -e '^w:' -e 'Missing time signature meta' \
-e 'All rights reserved' -e 'Error ' -e 'Copyright' | \
## ABC MIDI commands start with '%%', but regular comments start with '%', so drop any line with '%' but not '%%' in it:
sed -e 's/^%[^%].*//g' | \
## delete spaces inside non-MIDI commands (MIDI, but not ABC, commands are space-sensitive):
sed -e '/^%%/! s/ //g' | \
## a handful of files are pathological, so truncate:
head --bytes=300000 > "$@".abc; }
export -f convertMidi2Abc
find . -type f -name "*.mid" | parallel convertMidi2Abc
## below 150 characters means an ABC file probably contains only metadata
find . -type f -name "*.abc" -size -150c -delete
## create training (19/20) and validation (1/20) file lists:
find . -type f -name "*.mid.abc" | shuf > filelist.txt
split -n l/20 filelist.txt splitThe file-lists can be used to read in individual files, intersperse <|endoftext|>\n, and write them out as a single GPT-2-formatted text. A shell loop proved too slow so I wrote a simple Haskell script:
{-# LANGUAGE OverloadedStrings #-}
import Data.ByteString as B (concat, readFile, writeFile)
import Control.Monad (liftM)
import Data.List (intersperse)
main = do files <- liftM lines $ Prelude.readFile "training.txt" # 'splitaa'
contents <- mapM B.readFile files
let contents' = Data.List.intersperse "<|endoftext|>\n" contents
B.writeFile "foo" (B.concat contents')5.2GB of ABCs. The final results were 453,651 ABC files (~10k BPE/ABC?):
-
2020-03-30-abc-combinedmidi-training.txt: 4.9GB (430,928 ABC pieces) -
2020-03-30-abc-combinedmidi-validation.txt: 263MB (22,723 ABC pieces)
A sample of 50 randomly-chosen (excluding The Sessions) human-written MIDI files:
The full dataset (all MIDIs, ABCs, file-lists, and GPT-2-formatted text files) is available for download:
rsync -v rsync://176.9.41.242:873/biggan/2020-03-30-mididataset-abcnotation-thesessions-lmd_full-popmididatasetismir.tar.xz ./MIDI Training
Curriculum training. We initially trained with a ~27k context window, but iterations took multiple seconds, and after we took a second look at the ABC conversions and saw that pieces averaged only 10.7K BPEs, decided that was largely a waste, and switched over to 5k context windows. Due to repeated TPU preemptions and delays in restarting training and some ill-timed learning rate decreases, it wasn’t until late March 2020 that we got noticeably good samples at a loss of ~0.22/10m steps on 2020-03-24. (Thank goodness for our TRC credits! Even with TPUs covered, the final total cost of the VMs/bandwidth/storage was >$1,236.25$1,0002020.)
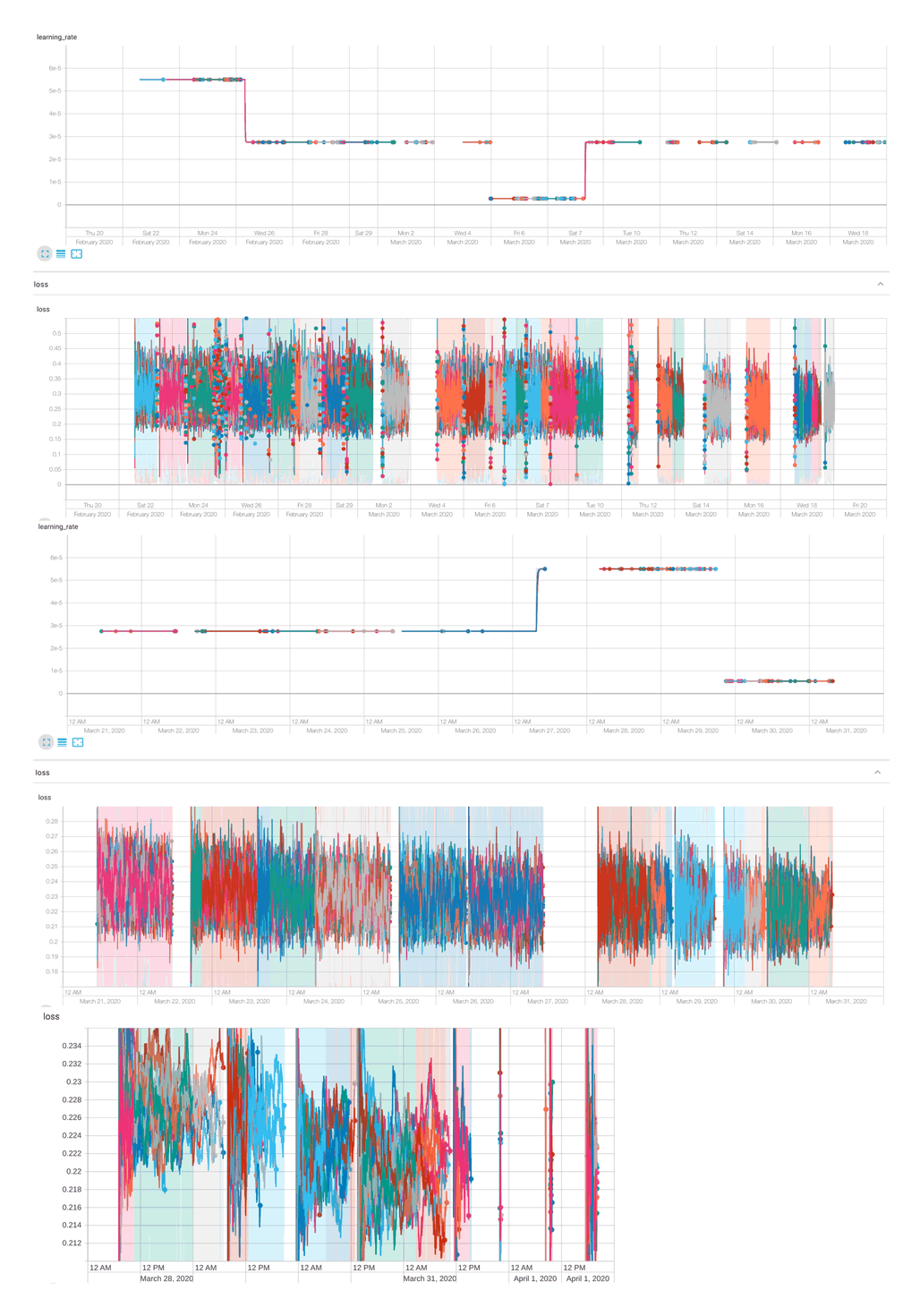
2020-02-20–1m2020-04-01,
Converged—underfit‽ Around 4 April, with the 5k context training apparently fully-converged, we switched back to ‘coreless’ mode and 10k context windows and trained to a loss of ~0.20. It was stable at that loss, without any further decrease, for many steps, so, interestingly, I suspect GPT-2-117M turns out to underfit our MIDI dataset while being able to overfit the earlier smaller ABC datasets. If I had known we’d be able to hit an only loss of 0.2, I would’ve started with a larger model than just GPT-2-117M, and accepted any necessary limits on context window. Since likelihood loss seems to track quality so closely & the final few increments of loss make a big difference perceptually, it’s possible we could’ve done a lot better.
GPT-2-30k Download
The final model was trained for 30,588,051 steps, and is available for download:
-
Rsync mirror:
rsync -v rsync://176.9.41.242:873/biggan/2020-04-12-gwern-gpt-2-117m-midi-30588051.tar.xz ./(475M)
MIDI Generation
Sampling still unsolved—divergence+gibberish. Generating samples from the 10m checkpoint proved unusually tricky, despite nucleus sampling, with high risk of repetition or degeneration into pseudo-English-lyrics/text. A round of data-cleaning to remove that fixed the degeneration into pseudo-English, but left the repetition problem: sampling remains prone to generating hundreds of lines of repeating notes like z8|z8|z8|z8| (which is especially slow once the context window fills up). These repetition traps (so common in likelihood-trained NN models) appear to go on indefinitely in my sampling, and high temperatures/top_p parameters do not break loops. The sheer length of pieces appears to exacerbate the usual issues with repetition—a sampling process which is fine for a few hundred tokens may nevertheless frequently diverge as required lengths approach 10k. (Given that extremely long sequences of z notes are common in the original ABC-MIDI datasets, this suggests that a custom BPE encoding—unlike in my earlier poetry or The Sessions datasets—would be helpful in collapsing these common long sequences down to a few BPEs.)
Failure mode: dropping instruments. Strikingly, pieces tended to be either good or fail entirely, possibly because instrument/tracks are generated one at a time, and syntax errors or early termination of sampling can disable entire instruments, leading to silent tracks and a final music piece which simply repeats endlessly (because the melody & variation would have been provided by a failed or nonexistent later track). To reduce the impact from divergence while trying to avoid truncating potentially-good pieces early, I use the repetition penalty from Nick Walton’s AI Dungeon 2 (itself borrowed from CTRL), and set a 10k length limit on samples (corresponding to the average length of an ABC-encoded MIDI), and generate 10 BPEs at a time to speed things up (1 BPE per step would theoretically give better results but is extremely slow):
python3 src/generate_samples.py --top_p 0.95 --penalty 0.65 --prompt "\nX:" --model_name midi \
--length 10000 --n_ctx 10000 --nsamples 10 --batch_size 1 --step 10 --maxlen 10000MIDI Samples
Because of the sampling fragility, there is little point in providing a dump of random samples to listen to (although I provide a text dump); instead, here are hand-selected samples representing roughly the top 5% of samples. All samples are generated using the default Timidity settings, timings, and soundbanks (eg. no use of harps like Shawn Presser’s modified samples before),
Samples from iteration #10,974,811, loss ~0.22:
-
MIDI sample (2020-03-24); electronica/instrumental -
MIDI sample (2020-03-24); electronica -
MIDI sample (2020-03-24); jazz (particularly nice use of a saxophone track) -
MIDI sample (2020-03-24); classical piano piece -
MIDI sample (2020-03-25); classical fugue-esque harpsichord/organ
From the final models:
-
Big Dataset (notable for its drum+bagpipe-like duet) -
(2020-04-11); fast jazz saxophone piece? -
LMD folk-ish piece (heavy on a woodwind/organ?) -
LMD: catchy ambient-esque piano piece -
Pop MIDI, rapid jazz piano? -
Pop MIDI, almost video-game orchestral-like in parts -
(2020-04-15); LMD piano piece -
LMD piano piece -
LMD slow classical -
Pop MIDI, guitar rock -
Pop MIDI piano -
The Sessions jig -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions (Steve Martland-like?)
-
The Sessions -
The Sessions -
2020-04-18 samples: ABC -
Big Dataset -
Big Dataset -
Big Dataset -
Big Dataset -
Big Dataset -
Big Dataset -
Big Dataset -
Big Dataset -
Big Dataset -
Pop -
Pop -
The Sessions -
The Sessions -
The Sessions -
The Sessions -
The Sessions
Better but frailer. Quality-wise, the MIDI model is capable of much more diverse pieces while still generating good folk music, illustrating the benefits of switching to a much larger dataset. Although the difficulty we had training it means I do not recommend using GPT-2 for such long sequences! (Fortunately, there are many technical solutions to the immediate problem of self-attention’s quadratic cost.) But after the task of training with wide windows is solved, there is not yet any solution to the problem of sampling. It’s hard to not notice that the good MIDI samples are more repetitive than the small ABC samples; this could be due in part to issues in sampling breaking additional voices & leaving the backing tracks (which are supposed to be repetitive), and could also reflect greater repetition in MIDI pieces intended to be several minutes longer as opposed to curated ABC folk music pieces which tend to be quite short (as performers will vary & repeat as necessary while performing), but one must strongly suspect that the sampling process itself is to blame and nucleus sampling is far from a solution. Were we to train a larger or longer model which can model tens of thousands of tokens, how would we sample tens of thousands of tokens from it?
External Links
-
Discussion:
-
TiMidity++ is a strange tool. The man page boasts of builtin Usenet support! Just in case you ever needed to play all MIDI files in a particular newsgroup.↩︎
-
Using the standard GPT-2 BPE encoding of the ABC-compiled versions—although we did discuss making either MIDI or ABC-specific BPE encodings for saving perhaps a quarter of space, it would add complexity for users and we weren’t sure how to create a new BPE encoding.↩︎
-
For example, this motivated OpenAI to develop Sparse Transformers, which tame the scaling by trimming the Transformer attention windows to much smaller than the full window, thereby avoiding the full self-attention quadratic scaling, which enables windows of tens of thousands easily (30k is more than enough to handle most MIDIs), and enables MuseNet to generate MIDIs without a problem. 2020 avoid the window problem by preprocessing MIDI into a custom encoding specialized to single piano tracks which is easier to understand, and switching to Transformer-XL, which has a limited window but adds on recurrency/memory to maintain coherence.↩︎
-
This is surprising because you would estimate that TPUs have 16GB per core and 8 cores, so only 128GB VRAM total. But if you avoid that, and use what we call ‘coreless mode’, both TPUv2 and TPUv3 apparently die at around 300GB. This does not appear to be documented anywhere by Google, even though it’s interesting & surprising & useful.↩︎
-
This is part of how “accidentally quadratic” algorithms can sneak into production systems—quadratic growth is slow enough that for many inputs, fast hardware can still handle it and the software just ‘feels slow’, while for truly exponential growth, it’d immediately hit the wall on realistic inputs and fail.↩︎
-
Amusingly, OpenAI would later take a similar brute force approach in training iGPT: et al 2020.↩︎