April 2021 News
April 2021 Gwern.net newsletter with links on AI scaling, particularly new East Asian record-breaking work & deep reinforcement learning.
April 2021’s Gwern.net newsletter is now out; previous, March 2021 (archives). This is a collation of links and summary of major changes, overlapping with my Changelog; brought to you by my donors on Patreon.
Writings
-
Better Greek Variable Suggestions (use ϰ, ς, υ, ϖ, Υ, Ξ, ι, ϱ, ϑ, or Π instead)
Links
AI
-
“Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks”, et al 2018; “Perceiver: General Perception with Iterative Attention”, et al 2021 (skinny Transformers applied recurrently; given reinvention, one might ask “is attention, getting too much attention?”, especially given how many Transformer tweaks don’t pan out or have antecedents, indicating a gold rush? Probably not: if the marginal return on this research direction had fallen below that of competitors, we would see those neglected directions invade Transformer topics—while we continue to see the reverse, and many applications as yet untouched by all the new approaches, suggesting that we still don’t pay enough attention)
-
“Z-IL: Predictive Coding Can Do Exact Backpropagation on Any Neural Network”, et al 2021 (scaling local learning rules to ImageNet AlexNet/Resnet & ALE DRL at similar compute cost)
-
“Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates”, 2017 (the lingering mystery of super-convergence, saving 50–90% compute with LRs as high as 20 (!): what is it, why does it work only sometimes, is there any connection to grokking & can it work for large models like GPT-3 given the catapult/tunneling hypothesis?)
-
“Rip van Winkle’s Razor, a Simple New Estimate for Adaptive Data Analysis” (an unusual approach to estimating generalization—by quantifying the information-theoretic simplicity of all the powerful DL research discoveries since 201213ya, into ~1 kilobyte. And yet, what a kilobyte…)
-
“Ambigrammatic Figures”, 2020 (making horrifying StyleGAN faces that can be rotated 180° by projection & then gradient-ascent towards an upside-down face)
-
-
Congratulations to OpenAI on 1 year of GPT-3 & OA API. Has it really only been a year?—it has truly exceeded expectations.
-
Naver announces 204b-parameter Korean-language NN, “HyperCLOVA” (KO; unknown arch although apparently dense, or training-compute or benchmark/loss performance; 650b token training dataset. Who knew Naver was even trying? “And we are here as on a darkling plain / Swept with confused alarms of struggle and flight, / Where ignorant armies clash by night.”)
-
“PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation”, et al 2021 (Zh; Huawei’s GPT-3-200b prototype, trained on indigenous Chinese GPU+DL stack; a partial replication, due to incomplete training on ~43b tokens; the 13b-parameter model checkpoint has been released for download, and they are considering releasing the 200b-parameter model… Ding commentary)
-
New 𝒪(100b)-parameter Transformer models announced at Google I/O ’2021: LaMDA (EN; chatbot), MUM (multimodal multilingual search/translation/Q&A)
-
“PLUG” (Zh): a 27b parameter BERT-like Chinese language model, targeting 200b next (AliBaba followup to StructBERT/PALM)
-
“CogView: Mastering Text-to-Image Generation via Transformers”, et al 2021 (another Chinese DALL·E 1 clone, post-M6: n = 30m text-image pairs—“WuDaoCorpus: the largest Chinese corpus data set, with about 2TB of text and 725 billion Chinese characters”—to train 4b-parameter GPT, models to be released)
-
“VideoGPT: Video Generation using VQ-VAE and Transformers”, et al 2021; “GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions”, et al 2021 (DALL·E 1 for video on Howto100M: VQ-VAE + sparse attention)
-
“Efficient Large-Scale Language Model Training on GPU Clusters”, et al 2021 (Nvidia ‘Megatron-LM’ software for scaling up to 3072 A100 GPUs; allows 1t-parameter models at 502 petaFLOP/s or 50% efficiency, cf. TPU rival, GSPMD, and note et al 2021 estimates GPT-3 at ~3.5m V100 GPU-hours, so OA got ~20% efficiency?); “We expect to see multi-trillion-parameter models by next year, and 100 trillion+ parameter models by 2023” —Nvidia CEO Jensen Huang (subtitles)
-
Mixture-Of-Experts:
-
BAAI’s “Wudao Wensu”: 1.75-trillion parameters & multimodal! (prologue)
-
“Exploring Sparse Expert Models and Beyond”, et al 2021 (1t-parameter hierarchical Switch Transformer trained on 480 V100 GPUs)
-
-
-
-
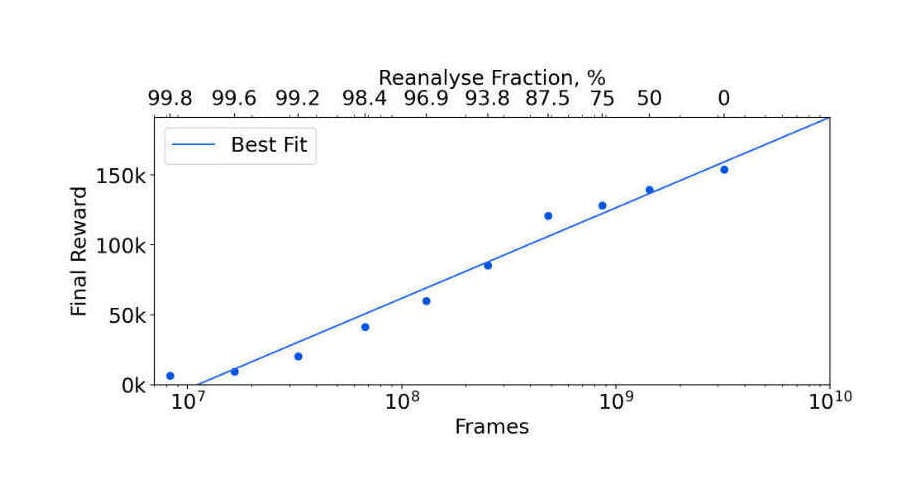
“MuZero Unplugged: Online and Offline Reinforcement Learning by Planning with a Learned Model”, et al 2021 (Reanalyze+MuZero; smooth log-scaling of Ms. Pacman reward with sample size, 107–1010, showing that DRL for arcade games parallels board games)
-
“Decision Transformer: Reinforcement Learning via Sequence Modeling”, et al 2021 (this, incidentally, offers a beautifully simple way of doing preference learning: instead of ranker models & PPO training of baseline models, just prefix the ranking to the sequence and train next-token prediction!)
-
“Sampled MuZero: Learning and Planning in Complex Action Spaces”, et al 2021 (MuZero for continuous domains: DM Control Suite/Real-World RL Suite); “Continuous Control for Searching and Planning with a Learned Model”, et al 2020
-
“Muesli: Combining Improvements in Policy Optimization”, et al 2020 (catching up with original MuZero)
-
“Visualizing MuZero Models”, de et al 2021 (reimplementing & introspecting a MuZero)
-
-
“Scaling Scaling Laws with Board Games”, Jones 2021 (AlphaZero/Hex: highly-optimized GPU implementation enables showing smooth scaling across 6 OOM of compute—2× FLOPS = 66% victory; amortization of training → runtime tree-search, where 10× training = 15× runtime)
-
“Scaling Laws for Language Transfer Learning”, Christina Kim ( et al 2021 followup: smooth scaling for En → De/Es/Zh)
-
“Carbon Emissions and Large Neural Network Training”, et al 2021 (“…choice of DNN/datacenter/processor can reduce the carbon footprint up to ~100–1000×. These large factors make retroactive estimates difficult.”)
-
“How to Train BERT with an Academic Budget”, et al 2021 (BERT in 8 GPU-days—R&D iteration allows finding efficiency; there’s nothing so expensive as demanding research be cheap.1)
{kind=link}
Genetics
Everything Is Heritable:
-
“Precision exercise medicine: understanding exercise response variability”, et al 2019 (“large individual differences in CRF response (range: −33% to +118%) have been observed across the 8 exercise training studies independent of exercise duration”—nothing in psychology, or medicine, makes sense except in the light of individual differences…)
Recent Evolution:
Engineering:
-
“China officially bans CRISPR babies, human clones and animal-human hybrids”? (another blow to attempts to project fears & fantasies onto China)
Politics/Religion
-
Reflecting Sunlight: Recommendations for Solar Geoengineering Research and Research Governance, National 2021 (media)
-
“Improving Public Sector Management at Scale? Experimental Evidence on School Governance India”, 2020
-
“Jay-Z’s 99 Problems, Verse 2: A Close Reading with 4th Amendment Guidance for Cops and Perps”, 2012
Psychology/Biology
-
“Oxylipin biosynthesis reinforces cellular senescence and allows detection of senolysis”, et al 2021
-
“Inside the Secret Sting Operations to Expose Celebrity Psychics”
-
“Cetaceans, sex and sea serpents: an analysis of the Egede accounts of a ‘most dreadful monster’ seen off the coast of Greenland in 1734”, Paxton et al 200520ya (is that a legendary cryptid in your pocket, or are you just happy to see me?)
-
“Building the perfect curse word: A psycholinguistic investigation of the form and meaning of taboo words”, et al 2020
Technology
-
“How Developers Choose Names”, et al 2021 (“Another example concerned the function ‘arrangeFilesByName(files)’. When asked the return value…one suggested the number of files reordered”)
-
“Bringing GNU Emacs to Native Code”, et al 2020 (using libgccjit to make Emacs 2.3× to 42× faster; gccemacs has been merged into Emacs HEAD & will be available soon)
-
“Hosting SQLite databases on Github Pages (or any static file hoster)” (a revolution in static website technology: eg. running a query need download only 54kb of a 670MB database; fulltext site search is just the beginning of the possibilities of this clever use of range requests)
-
“Fontemon: World’s first video game in a font!” (a Pokemon-like CYOA implemented as an OpenType font file; play in browser or text editor—still not quite Turing-complete but definitely the most impressive thing implemented in a font so far)
-
Fontemon is by far the highlight of SIGBOVIK 2021; but also worth noting: “Back to Square One: Superhuman Performance in Chutes and Ladders Through Deep Neural Networks and Tree Search” · “Deep Deterministic Policy Gradient Boosted Decision Trees” · “Lowestcase and uppestcase letters: Advances in derp learning” · “openCHEAT: Computationally Helped Error bar Approximation Tool—Kick-starting Science 4.0” · “The Newcomb-Benford Law, Applied to Binary Data: An Empirical and Theoretic Analysis” · “Inverted Code Theory: Manipulating Program Entropy” (Tenet fans only—possibly inferior to 1991?) · “Build your own 8-bit busy beaver on a breadboard!”
Incidentally, it’s curious that while STEM fields have entire annual issues, journals, & conferences devoted to satire (SIGBOVIK; Arxiv April Fools papers like et al 2017; Special Topics; Manifold; the BMJ Christmas issue; the Ig Nobel Prizes & BAHFest), after asking in several places, I have found no instances in the humanities. (I know of many entertaining papers, like 2008 on waifus, but no regular organized publication, with the possible exception of the annual “Latke-Hamantash Debate”.)
-
Economics
-
“The Kelly Criterion in Blackjack Sports Betting, and the Stock Market”, 2006
-
“The Performance Pay Nobel” (CEO pay as blackbox optimization problem)
-
“The Ocean’s Hot Dog: The Development of the Fish Stick”, Kelly 200817ya (out of nostalgia, I bought some fish sticks for the first time in decades; better than I remembered, even if I had no tartar handy)
Philosophy
-
“The Aesthetics of Smelly Art”, Shiner & Kriskovets 200718ya; “The Odor Value Concept in the Formal Analysis of Olfactory Art”, 2019; “Perfumery as an art form”/notes, Qualia 2020
More on smell: manufacturing: “The Scent of the Nile: Jean-Claude Ellena creates a new perfume”; human smell is better than you think: “Mechanisms of Scent-tracking in Humans”, Porter et al 200619ya (video; see also “Poor Human Olfaction is a 19th Century Myth”, 2017); olfactory white; Kōdō, which unexpectedly appears in Knuth. C. Thi Nguyen’s description of the more bizarre & avant-garde perfumes made me curious enough to nose around & order 39 LuckyScent samplers.
Miscellaneous
-
Sarah Bernhardt (Lions. Lots of lions.)
-
Another thought, looking at ‘Employer Costs for Employee Compensation’ (PDF):
-
“Moore’s Law”: the cost of a transistor halves every ~19 months;
-
“Anti-Moore’s Law”: the cost of a synapse doubles every ~119 years.
-