‘AI mode collapse’ tag
- See Also
- Gwern
-
Links
- “Entropy of a Large Language Model Output”, Nikkin 2025
- “They Squandered the Holy Grail [Apple Intelligence Reliance on Bing-Style DALL·E 3]”, Iaso 2025
- “Favorite Colors of Some LLMs”, an 2024
- “Hidden Persuaders: LLMs’ Political Leaning and Their Influence on Voters”, Potter et al 2024
- “Do LLMs Estimate Uncertainty Well in Instruction-Following?”, Heo et al 2024
- “SimpleStrat: Diversifying Language Model Generation With Stratification”, Wong et al 2024
- “I Quit Teaching Because of ChatGPT”, Livingstone 2024
- “The 27-Year-Old Billionaire Whose Army Does AI’s Dirty Work: Alexandr Wang’s Scale AI Deploys Gig Workers around the Globe to Shape How the Big AI Models Behave”, Jin 2024
- “Thoughts While Watching Myself Be Automated”, Dynomight 2024
- “Why AI Isn’t Going to Make Art”, Chiang 2024
- “Epistemic Calibration and Searching the Space of Truth”, Lee 2024
- “Are Large Language Models Consistent over Value-Laden Questions?”, Moore et al 2024
- “Pron vs Prompt: Can Large Language Models Already Challenge a World-Class Fiction Author at Creative Text Writing?”, Marco et al 2024
- “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
- “AI Doesn’t Kill Jobs? Tell That to Freelancers: There’s Now Data to Back up What Freelancers Have Been Saying for Months”, Mims 2024
- “What Are the Odds? Language Models Are Capable of Probabilistic Reasoning”, Paruchuri et al 2024
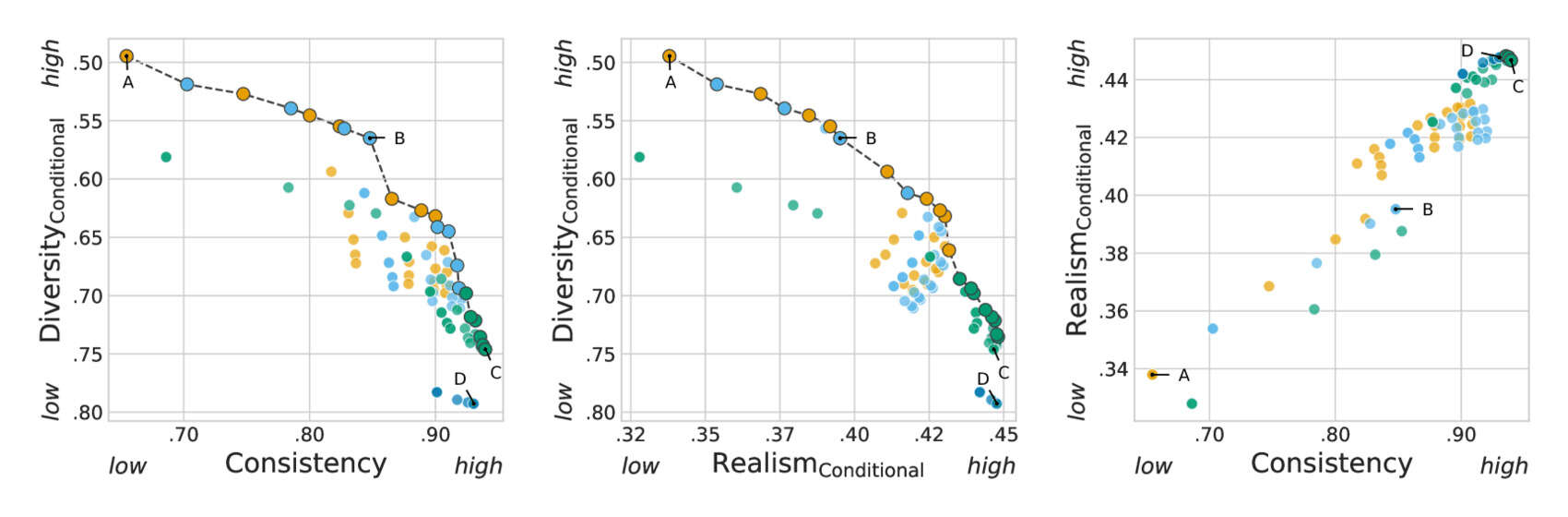
- “Consistency-Diversity-Realism Pareto Fronts of Conditional Image Generative Models”, Astolfi et al 2024
- “Self-Consuming Generative Models With Curated Data Provably Optimize Human Preferences”, Ferbach et al 2024
- “Creativity Has Left the Chat: The Price of Debiasing Language Models”, Mohammadi 2024
- “I Wish I Knew How to Force Quit You”, Life & Rich 2024
- “Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience”, Han et al 2024
- “A Tale of Tails: Model Collapse As a Change of Scaling Laws”, Dohmatob et al 2024
- “The Non-Effect of Sampling Temperature on Problem Solving in GPT-3.5/GPT-4”, Renze & Guven 2024
- “Weaver: Foundation Models for Creative Writing”, Wang et al 2024
- “Does Using ChatGPT Result in Human Cognitive Augmentation?”, Fulbright & Morrison 2024
- “Originality Dies When Being Average Is Easier”
- “Experimental Narratives: A Comparison of Human Crowdsourced Storytelling and AI Storytelling”
- “Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
- “EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”, Paech 2023
- “Generative Artificial Intelligence Enhances Creativity but Reduces the Diversity of Novel Content”, Doshi & Hauser 2023
- “When ‘A Helpful Assistant’ Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models”, Zheng et al 2023
- “The Impact of Large Language Models on Scientific Discovery: a Preliminary Study Using GPT-4”, AI4Science & Quantum 2023
- “A Coder Considers the Waning Days of the Craft: Coding Has Always Felt to Me like an Endlessly Deep and Rich Domain. Now I Find Myself Wanting to Write a Eulogy for It”, Somers 2023
- “When Ruthless Cultural Elitism Is Exactly the Job”, Marchese 2023
- “Does GPT-4 Pass the Turing Test?”, Jones & Bergen 2023
- “Large Language Models Can Replicate Cross-Cultural Differences in Personality”, Niszczota et al 2023
- “Assessing the Nature of Large Language Models: A Caution against Anthropocentrism”, Speed 2023
- “Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
- “I’m a Screenwriter. These AI Jokes Give Me Nightmares”, Rich 2023
- “Can a Chatbot Preach a Good Sermon? Hundreds Attend Church Service Generated by ChatGPT to Find Out”, Grieshaber 2023
- “ChatGPT Is Fun, but It Is Not Funny! Humor Is Still Challenging Large Language Models”, Jentzsch & Kersting 2023
- “The False Promise of Imitating Proprietary LLMs”, Gudibande et al 2023
- “Bits of Grass: Does GPT Already Know How to Write like Whitman?”, Sawicki et al 2023
- “PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits”, Jiang et al 2023
- “Inducing Anxiety in GPT-3.5 Increases Exploration and Bias”, Coda-Forno et al 2023
- “GPT-4 Technical Report § Limitations: Calibration”, OpenAI 2023 (page 12 org openai)
- “GPT-4 Technical Report § Harms of Representation, Allocation, and Quality of Service [Loss of Humor]”, OpenAI 2023 (page 50 org openai)
- “Rewarding Chatbots for Real-World Engagement With Millions of Users”, Irvine et al 2023
- “Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
- “Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
- “RL With KL Penalties Is Better Viewed As Bayesian Inference”, Korbak et al 2022
- “Janus”
- “Aidan Bench Attempts to Measure ‘Big Model Smell’ in LLMs”
- “Introducing V4”, AI 2025
- “Situational Awareness and Out-Of-Context Reasoning § GPT-4-Base Has Non-Zero Longform Performance”, Evans 2025
- “I Finally Got ChatGPT to Sound like Me”, lsusr 2025
- “The Case for More Ambitious Language Model Evals”
- “GPT-3 Catching Fish in Morse Code”
- “Mysteries of Mode Collapse”
- “Mysteries of Mode Collapse”
- “Please Stop Using Mediocre AI Art in Your Posts”
- “What Kind of Writer Is ChatGPT?”
- “The New Poem-Making Machinery”
- l4rz
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Gwern
“Towards Benchmarking LLM Diversity & Creativity”, Gwern 2024
“Commentary on Weaknesses in Midjourney’s New Ranking-Based Personalization Feature”, Gwern 2024
Commentary on weaknesses in Midjourney’s new ranking-based personalization feature
“Why Do Writers Still Underestimate LLMs?”, Gwern 2023
“Novelty Nets: Classifier Anti-Guidance”, Gwern 2024
Links
“Entropy of a Large Language Model Output”, Nikkin 2025
“They Squandered the Holy Grail [Apple Intelligence Reliance on Bing-Style DALL·E 3]”, Iaso 2025
They squandered the holy grail [Apple Intelligence reliance on Bing-style DALL·E 3]
“Favorite Colors of Some LLMs”, an 2024
“Hidden Persuaders: LLMs’ Political Leaning and Their Influence on Voters”, Potter et al 2024
Hidden Persuaders: LLMs’ Political Leaning and Their Influence on Voters
“Do LLMs Estimate Uncertainty Well in Instruction-Following?”, Heo et al 2024
“SimpleStrat: Diversifying Language Model Generation With Stratification”, Wong et al 2024
SimpleStrat: Diversifying Language Model Generation with Stratification
“I Quit Teaching Because of ChatGPT”, Livingstone 2024
“The 27-Year-Old Billionaire Whose Army Does AI’s Dirty Work: Alexandr Wang’s Scale AI Deploys Gig Workers around the Globe to Shape How the Big AI Models Behave”, Jin 2024
“Thoughts While Watching Myself Be Automated”, Dynomight 2024
“Why AI Isn’t Going to Make Art”, Chiang 2024
“Epistemic Calibration and Searching the Space of Truth”, Lee 2024
“Are Large Language Models Consistent over Value-Laden Questions?”, Moore et al 2024
Are Large Language Models Consistent over Value-laden Questions?
“Pron vs Prompt: Can Large Language Models Already Challenge a World-Class Fiction Author at Creative Text Writing?”, Marco et al 2024
“Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets
“AI Doesn’t Kill Jobs? Tell That to Freelancers: There’s Now Data to Back up What Freelancers Have Been Saying for Months”, Mims 2024
“What Are the Odds? Language Models Are Capable of Probabilistic Reasoning”, Paruchuri et al 2024
What Are the Odds? Language Models Are Capable of Probabilistic Reasoning
“Consistency-Diversity-Realism Pareto Fronts of Conditional Image Generative Models”, Astolfi et al 2024
Consistency-diversity-realism Pareto fronts of conditional image generative models
“Self-Consuming Generative Models With Curated Data Provably Optimize Human Preferences”, Ferbach et al 2024
Self-Consuming Generative Models with Curated Data Provably Optimize Human Preferences
“Creativity Has Left the Chat: The Price of Debiasing Language Models”, Mohammadi 2024
Creativity Has Left the Chat: The Price of Debiasing Language Models
“I Wish I Knew How to Force Quit You”, Life & Rich 2024
“Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience”, Han et al 2024
Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience
“A Tale of Tails: Model Collapse As a Change of Scaling Laws”, Dohmatob et al 2024
“The Non-Effect of Sampling Temperature on Problem Solving in GPT-3.5/GPT-4”, Renze & Guven 2024
The Non-Effect of Sampling Temperature on Problem Solving in GPT-3.5/GPT-4
“Weaver: Foundation Models for Creative Writing”, Wang et al 2024
“Does Using ChatGPT Result in Human Cognitive Augmentation?”, Fulbright & Morrison 2024
“Originality Dies When Being Average Is Easier”
“Experimental Narratives: A Comparison of Human Crowdsourced Storytelling and AI Storytelling”
Experimental narratives: A comparison of human crowdsourced storytelling and AI storytelling
“Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
“EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”, Paech 2023
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models
“Generative Artificial Intelligence Enhances Creativity but Reduces the Diversity of Novel Content”, Doshi & Hauser 2023
Generative artificial intelligence enhances creativity but reduces the diversity of novel content
“When ‘A Helpful Assistant’ Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models”, Zheng et al 2023
“The Impact of Large Language Models on Scientific Discovery: a Preliminary Study Using GPT-4”, AI4Science & Quantum 2023
The Impact of Large Language Models on Scientific Discovery: a Preliminary Study using GPT-4
“A Coder Considers the Waning Days of the Craft: Coding Has Always Felt to Me like an Endlessly Deep and Rich Domain. Now I Find Myself Wanting to Write a Eulogy for It”, Somers 2023
“When Ruthless Cultural Elitism Is Exactly the Job”, Marchese 2023
“Does GPT-4 Pass the Turing Test?”, Jones & Bergen 2023
“Large Language Models Can Replicate Cross-Cultural Differences in Personality”, Niszczota et al 2023
Large language models can replicate cross-cultural differences in personality
“Assessing the Nature of Large Language Models: A Caution against Anthropocentrism”, Speed 2023
Assessing the nature of large language models: A caution against anthropocentrism
“Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
Simple synthetic data reduces sycophancy in large language models
“I’m a Screenwriter. These AI Jokes Give Me Nightmares”, Rich 2023
“Can a Chatbot Preach a Good Sermon? Hundreds Attend Church Service Generated by ChatGPT to Find Out”, Grieshaber 2023
Can a chatbot preach a good sermon? Hundreds attend church service generated by ChatGPT to find out
“ChatGPT Is Fun, but It Is Not Funny! Humor Is Still Challenging Large Language Models”, Jentzsch & Kersting 2023
ChatGPT is fun, but it is not funny! Humor is still challenging Large Language Models
“The False Promise of Imitating Proprietary LLMs”, Gudibande et al 2023
“Bits of Grass: Does GPT Already Know How to Write like Whitman?”, Sawicki et al 2023
Bits of Grass: Does GPT already know how to write like Whitman?
“PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits”, Jiang et al 2023
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
“Inducing Anxiety in GPT-3.5 Increases Exploration and Bias”, Coda-Forno et al 2023
“GPT-4 Technical Report § Limitations: Calibration”, OpenAI 2023 (page 12 org openai)
“GPT-4 Technical Report § Harms of Representation, Allocation, and Quality of Service [Loss of Humor]”, OpenAI 2023 (page 50 org openai)
GPT-4 Technical Report § Harms of representation, allocation, and quality of service [loss of humor]
“Rewarding Chatbots for Real-World Engagement With Millions of Users”, Irvine et al 2023
Rewarding Chatbots for Real-World Engagement with Millions of Users
“Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
Discovering Language Model Behaviors with Model-Written Evaluations
“Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
“RL With KL Penalties Is Better Viewed As Bayesian Inference”, Korbak et al 2022
“Janus”
“Aidan Bench Attempts to Measure ‘Big Model Smell’ in LLMs”
“Introducing V4”, AI 2025
“Situational Awareness and Out-Of-Context Reasoning § GPT-4-Base Has Non-Zero Longform Performance”, Evans 2025
Situational Awareness and Out-Of-Context Reasoning § GPT-4-base has Non-Zero Longform Performance
“I Finally Got ChatGPT to Sound like Me”, lsusr 2025
“The Case for More Ambitious Language Model Evals”
“GPT-3 Catching Fish in Morse Code”
“Mysteries of Mode Collapse”
“Mysteries of Mode Collapse”
“Please Stop Using Mediocre AI Art in Your Posts”
“What Kind of Writer Is ChatGPT?”
“The New Poem-Making Machinery”
l4rz
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
ai-humor engagement-issues creative-diversity emotional-intelligence chatbot-experience
creative-ai
model-behaviors
preference-optimization
Miscellaneous
-
https://nostalgebraist.tumblr.com/post/706390430653267968/weve-been-talking-about-the-blandness-of: -
https://nostalgebraist.tumblr.com/post/706441900479152128/novel-writing-chatgpt-vs-code-davinci-002 -
https://nostalgebraist.tumblr.com/post/728556535745232896/claude-is-insufferable:View External Link:
https://nostalgebraist.tumblr.com/post/728556535745232896/claude-is-insufferable -
https://thezvi.wordpress.com/2024/02/27/the-gemini-incident-continues/ -
https://www.astralcodexten.com/p/constitutional-ai-rlhf-on-steroids -
https://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2017.00071/full -
https://www.lesswrong.com/posts/MJyud5Qs6MheDemfE/artifex0-s-shortform?commentId=DzQapZEhTHxtjgbxh: -
https://www.lesswrong.com/posts/t9svvNPNmFf5Qa3TA/mysteries-of-mode-collapse#pfHTedu4GKaWoxD5K -
https://www.lesswrong.com/posts/tbJdxJMAiehewGpq2/impressions-from-base-gpt-4 -
https://www.reddit.com/r/LocalLLaMA/comments/1ftn6s1/all_llms_are_converging_towards_the_same_point/: -
https://www.reddit.com/r/LocalLLaMA/comments/1fuxw8d/just_for_kicks_i_looked_at_the_newly_released/ -
https://www.reddit.com/r/mlscaling/comments/1gyb54z/the_fate_of_gpt4o/ -
https://www.wired.com/story/confessions-viral-ai-writer-chatgpt/:View External Link:
https://www.wired.com/story/confessions-viral-ai-writer-chatgpt/
{kind=link}
{kind=link}
Bibliography
-
https://time.com/7026050/chatgpt-quit-teaching-ai-essay/: “I Quit Teaching Because of ChatGPT”, -
https://dynomight.net/automated/: “Thoughts While Watching Myself Be Automated”, -
https://www.newyorker.com/culture/the-weekend-essay/why-ai-isnt-going-to-make-art: “Why AI Isn’t Going to Make Art”, -
https://arxiv.org/abs/2406.18906: “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, -
https://www.thisamericanlife.org/832/transcript#act2: “I Wish I Knew How to Force Quit You”, -
https://arxiv.org/abs/2402.07043: “A Tale of Tails: Model Collapse As a Change of Scaling Laws”, -
https://arxiv.org/abs/2312.06281: “EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”, -
https://www.nytimes.com/interactive/2023/11/12/magazine/andrew-wylie-interview.html: “When Ruthless Cultural Elitism Is Exactly the Job”, -
https://arxiv.org/abs/2308.03958#deepmind: “Simple Synthetic Data Reduces Sycophancy in Large Language Models”, -
https://time.com/6301288/the-ai-jokes-that-give-me-nightmares/: “I’m a Screenwriter. These AI Jokes Give Me Nightmares”, -
https://arxiv.org/abs/2305.15717: “The False Promise of Imitating Proprietary LLMs”, -
https://arxiv.org/abs/2305.11064: “Bits of Grass: Does GPT Already Know How to Write like Whitman?”, -
https://arxiv.org/pdf/2303.08774#page=12&org=openai: “GPT-4 Technical Report § Limitations: Calibration”, -
https://www.lesswrong.com/posts/t9svvNPNmFf5Qa3TA/mysteries-of-mode-collapse-due-to-rlhf#Inescapable_wedding_parties: “Mysteries of Mode Collapse § Inescapable Wedding Parties”, -
https://arxiv.org/abs/2205.11275: “RL With KL Penalties Is Better Viewed As Bayesian Inference”,