‘active learning’ tag
- See Also
-
Links
- “Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”, Hahn et al 2024
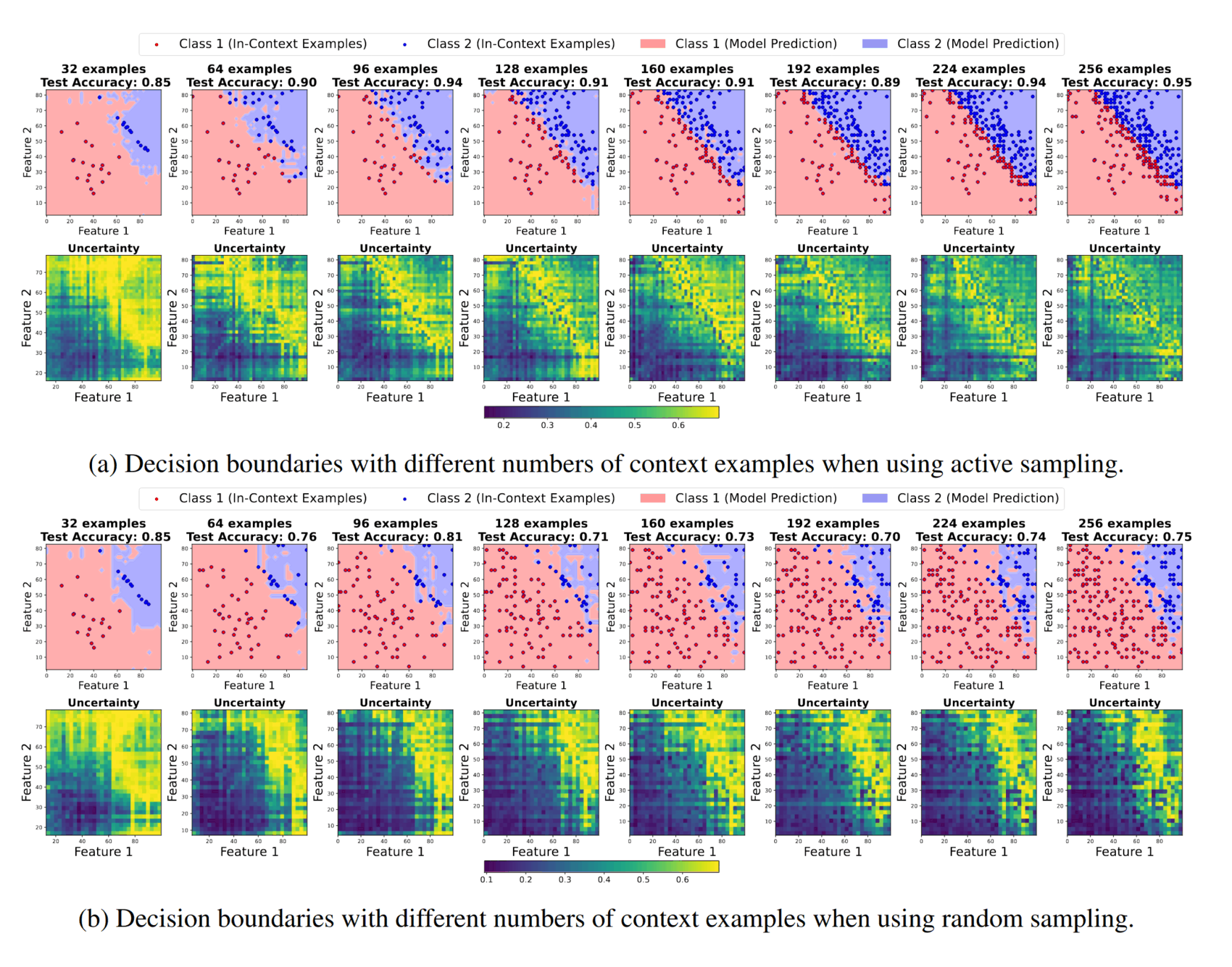
- “Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
- “Beyond Model Collapse: Scaling Up With Synthesized Data Requires Reinforcement”, Feng et al 2024
- “Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge”, Strieth-Kalthoff et al 2024
- “Sparse Universal Transformer”, Tan et al 2023
- “Skill-It! A Data-Driven Skills Framework for Understanding and Training Language Models”, Chen et al 2023
- “AlpaGasus: Training A Better Alpaca With Fewer Data”, Chen et al 2023
- “Instruction Mining: High-Quality Instruction Data Selection for Large Language Models”, Cao et al 2023
- “No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-Based Language Models”, Kaddour et al 2023
- “Estimating Label Quality and Errors in Semantic Segmentation Data via Any Model”, Lad & Mueller 2023
- “Self Expanding Neural Networks”, Mitchell et al 2023
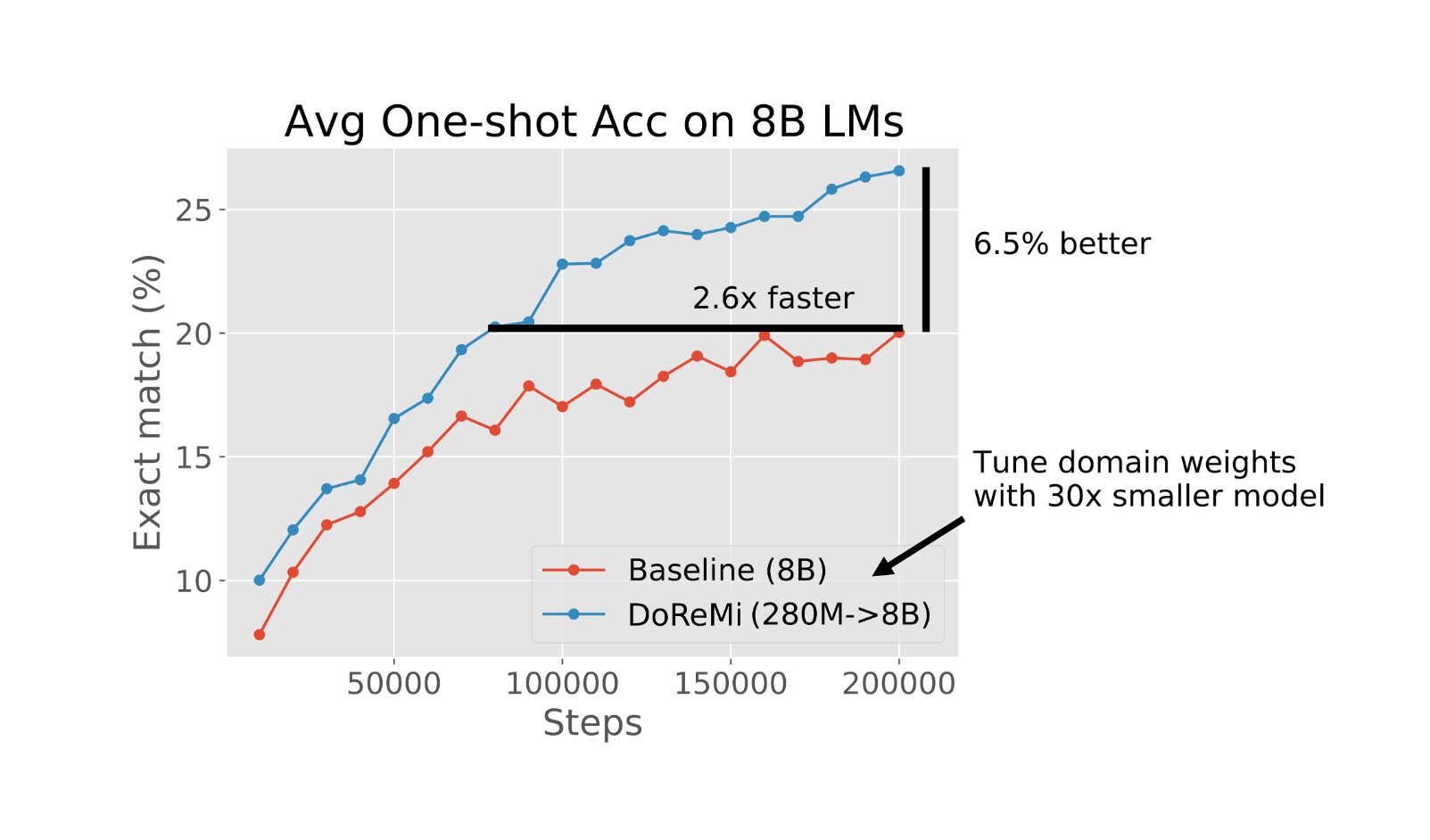
- “DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining”, Xie et al 2023
- “Chatting With GPT-3 for Zero-Shot Human-Like Mobile Automated GUI Testing”, Liu et al 2023
- “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
- “Q2d: Turning Questions into Dialogs to Teach Models How to Search”, Bitton et al 2023
- “Segment Anything”, Kirillov et al 2023
- “Scaling Expert Language Models With Unsupervised Domain Discovery”, Gururangan et al 2023
- “Modern Bayesian Experimental Design”, Rainforth et al 2023
- “Unifying Approaches in Active Learning and Active Sampling via Fisher Information and Information-Theoretic Quantities”, Kirsch & Gal 2023
- “Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula”, Bronstein et al 2022
- “CDCD: Continuous Diffusion for Categorical Data”, Dieleman et al 2022
- “Query by Committee Made Real”, Gilad-Bachrach et al 2022
- “Weakly Supervised Structured Output Learning for Semantic Segmentation”, Vezhnevets et al 2022
- “The Power of Ensembles for Active Learning in Image Classification”, Beluch et al 2022
- “Multi-Class Active Learning for Image Classification”, Joshi et al 2022
- “Multi-Class Active Learning by Uncertainty Sampling With Diversity Maximization”, Yang et al 2022
- “The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes”, Kocsis et al 2022
- “Detecting Label Errors in Token Classification Data”, Wang & Mueller 2022
- “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
- “Bamboo: Building Mega-Scale Vision Dataset Continually With Human-Machine Synergy”, Zhang et al 2022
- “Multi-Task Self-Training for Learning General Representations”, Ghiasi et al 2021
- “Predictive Coding: a Theoretical and Experimental Review”, Millidge et al 2021
- “Dataset Distillation With Infinitely Wide Convolutional Networks”, Nguyen et al 2021
- “Stochastic Batch Acquisition: A Simple Baseline for Deep Active Learning”, Kirsch et al 2021
- “Adapting the Function Approximation Architecture in Online Reinforcement Learning”, Martin & Modayil 2021
- “B-Pref: Benchmarking Preference-Based Reinforcement Learning”, Lee et al 2021
- “Fully General Online Imitation Learning”, Cohen et al 2021
- “When Do Curricula Work?”, Wu et al 2020
- “Dataset Meta-Learning from Kernel Ridge-Regression”, Nguyen et al 2020
- “Dataset Cartography: Mapping and Diagnosing Datasets With Training Dynamics”, Swayamdipta et al 2020
- “BanditPAM: Almost Linear Time k-Medoids Clustering via Multi-Armed Bandits”, Tiwari et al 2020
- “Exploring Bayesian Optimization: Breaking Bayesian Optimization into Small, Sizeable Chunks”, Agnihotri & Batra 2020
- “Small-GAN: Speeding Up GAN Training Using Core-Sets”, Sinha et al 2019
- “A Deep Active Learning System for Species Identification and Counting in Camera Trap Images”, Norouzzadeh et al 2019
- “On Warm-Starting Neural Network Training”, Ash & Adams 2019
- “Accelerating Deep Learning by Focusing on the Biggest Losers”, Jiang et al 2019
- “Data Valuation Using Reinforcement Learning”, Yoon et al 2019
- “BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning”, Kirsch et al 2019
- “BADGE: Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds”, Ash et al 2019
- “Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules”, Ho et al 2019
- “Learning Loss for Active Learning”, Yoo & Kweon 2019
- “A Recipe for Training Neural Networks”, Karpathy 2019
- “ProductNet: a Collection of High-Quality Datasets for Product Representation Learning”, Wang et al 2019
- “End-To-End Robotic Reinforcement Learning without Reward Engineering”, Singh et al 2019
- “Data Shapley: Equitable Valuation of Data for Machine Learning”, Ghorbani & Zou 2019
- “Learning from Dialogue After Deployment: Feed Yourself, Chatbot!”, Hancock et al 2019
- “The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale”, Kuznetsova et al 2018
- “Computational Mechanisms of Curiosity and Goal-Directed Exploration”, Schwartenbeck et al 2018
- “Conditional Neural Processes”, Garnelo et al 2018
- “Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning”, Pang et al 2018
- “More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch”, Calandra et al 2018
- “Fingerprint Policy Optimization for Robust Reinforcement Learning”, Paul et al 2018
- “AutoAugment: Learning Augmentation Policies from Data”, Cubuk et al 2018
- “Optimization, Fast and Slow: Optimally Switching between Local and Bayesian Optimization”, McLeod et al 2018
- “Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks With Existing Applications”, Hadash et al 2018
- “Active Learning With Partial Feedback”, Hu et al 2018
- “Active, Continual Fine Tuning of Convolutional Neural Networks for Reducing Annotation Efforts”, Zhou et al 2018
- “Less Is More: Sampling Chemical Space With Active Learning”, Smith et al 2018
- “The Eighty Five Percent Rule for Optimal Learning”, Wilson et al 2018
- “ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks”, Kim & Choi 2018
- “Learning a Generative Model for Validity in Complex Discrete Structures”, Janz et al 2017
- “Learning by Asking Questions”, Misra et al 2017
- “BlockDrop: Dynamic Inference Paths in Residual Networks”, Wu et al 2017
- “Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent”, Yang et al 2017
- “Classification With Costly Features Using Deep Reinforcement Learning”, Janisch et al 2017
- “Decomposition of Uncertainty in Bayesian Deep Learning for Efficient and Risk-Sensitive Learning”, Depeweg et al 2017
- “Why Pay More When You Can Pay Less: A Joint Learning Framework for Active Feature Acquisition and Classification”, Shim et al 2017
- “Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks”, Jayaraman & Grauman 2017
- “Active Learning for Convolutional Neural Networks: A Core-Set Approach”, Sener & Savarese 2017
- “Interpretable Active Learning”, Phillips et al 2017
- “Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, Sun et al 2017
- “A Tutorial on Thompson Sampling”, Russo et al 2017
- “Learning to Learn from Noisy Web Videos”, Yeung et al 2017
- “Teaching Machines to Describe Images via Natural Language Feedback”, Ling & Fidler 2017
- “Ask the Right Questions: Active Question Reformulation With Reinforcement Learning”, Buck et al 2017
- “BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography”, Wilber et al 2017
- “PBO: Preferential Bayesian Optimization”, Gonzalez et al 2017
- “OHEM: Training Region-Based Object Detectors With Online Hard Example Mining”, Shrivastava et al 2016
- “The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition”, Krause et al 2015
- “LSUN: Construction of a Large-Scale Image Dataset Using Deep Learning With Humans in the Loop”, Yu et al 2015
- “Dropout As a Bayesian Approximation: Representing Model Uncertainty in Deep Learning”, Gal & Ghahramani 2015
- “Just Sort It! A Simple and Effective Approach to Active Preference Learning”, Maystre & Grossglauser 2015
- “Learning With Intelligent Teacher: Similarity Control and Knowledge Transfer”, Vapnik & Izmailov 2015
- “Minimax Analysis of Active Learning”, Hanneke & Yang 2014
- “Algorithmic and Human Teaching of Sequential Decision Tasks”, Cakmak & Lopes 2012
- “Bayesian Active Learning for Classification and Preference Learning”, Houlsby et al 2011
- “Rates of Convergence in Active Learning”, Hanneke 2011
- “The True Sample Complexity of Active Learning”, Balcan et al 2010
- “Active Testing for Face Detection and Localization”, Sznitman & Jedynak 2010
- “The Wisdom of the Few: a Collaborative Filtering Approach Based on Expert Opinions from the Web”, Amatriain et al 2009
- “Learning and Example Selection for Object and Pattern Detection”, Sung 1995
- “Information-Based Objective Functions for Active Data Selection”, MacKay 1992
- “Active Learning Literature Survey”
- “Brief Summary of the Panel Discussion at DL Workshop @ICML 2015”
- “Active Learning”
- “Aurora’s Approach to Development”
- “Active Learning for High Dimensional Inputs Using Bayesian Convolutional Neural Networks”
- “AI-Guided Robots Are Ready to Sort Your Recyclables”
- “When Self-Driving Cars Can’t Help Themselves, Who Takes the Wheel?”
- “How a Feel-Good AI Story Went Wrong in Flint: A Machine-Learning Model Showed Promising Results, but City Officials and Their Engineering Contractor Abandoned It.”
- Sort By Magic
- Wikipedia
- Miscellaneous
- Bibliography
See Also
Links
“Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”, Hahn et al 2024
Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty
“Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
Probing the Decision Boundaries of In-context Learning in Large Language Models
“Beyond Model Collapse: Scaling Up With Synthesized Data Requires Reinforcement”, Feng et al 2024
Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
“Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge”, Strieth-Kalthoff et al 2024
Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge
“Sparse Universal Transformer”, Tan et al 2023
“Skill-It! A Data-Driven Skills Framework for Understanding and Training Language Models”, Chen et al 2023
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models
“AlpaGasus: Training A Better Alpaca With Fewer Data”, Chen et al 2023
“Instruction Mining: High-Quality Instruction Data Selection for Large Language Models”, Cao et al 2023
Instruction Mining: High-Quality Instruction Data Selection for Large Language Models
“No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-Based Language Models”, Kaddour et al 2023
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models
“Estimating Label Quality and Errors in Semantic Segmentation Data via Any Model”, Lad & Mueller 2023
Estimating label quality and errors in semantic segmentation data via any model
“Self Expanding Neural Networks”, Mitchell et al 2023
“DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining”, Xie et al 2023
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
“Chatting With GPT-3 for Zero-Shot Human-Like Mobile Automated GUI Testing”, Liu et al 2023
Chatting with GPT-3 for Zero-Shot Human-Like Mobile Automated GUI Testing
“TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
“Q2d: Turning Questions into Dialogs to Teach Models How to Search”, Bitton et al 2023
q2d: Turning Questions into Dialogs to Teach Models How to Search
“Segment Anything”, Kirillov et al 2023
“Scaling Expert Language Models With Unsupervised Domain Discovery”, Gururangan et al 2023
Scaling Expert Language Models with Unsupervised Domain Discovery
“Modern Bayesian Experimental Design”, Rainforth et al 2023
“Unifying Approaches in Active Learning and Active Sampling via Fisher Information and Information-Theoretic Quantities”, Kirsch & Gal 2023
“Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula”, Bronstein et al 2022
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
“CDCD: Continuous Diffusion for Categorical Data”, Dieleman et al 2022
“Query by Committee Made Real”, Gilad-Bachrach et al 2022
“Weakly Supervised Structured Output Learning for Semantic Segmentation”, Vezhnevets et al 2022
Weakly supervised structured output learning for semantic segmentation
“The Power of Ensembles for Active Learning in Image Classification”, Beluch et al 2022
The Power of Ensembles for Active Learning in Image Classification
“Multi-Class Active Learning for Image Classification”, Joshi et al 2022
“Multi-Class Active Learning by Uncertainty Sampling With Diversity Maximization”, Yang et al 2022
Multi-Class Active Learning by Uncertainty Sampling with Diversity Maximization
“The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes”, Kocsis et al 2022
The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes
“Detecting Label Errors in Token Classification Data”, Wang & Mueller 2022
“RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
RHO-LOSS: Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
“Bamboo: Building Mega-Scale Vision Dataset Continually With Human-Machine Synergy”, Zhang et al 2022
Bamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy
“Multi-Task Self-Training for Learning General Representations”, Ghiasi et al 2021
Multi-Task Self-Training for Learning General Representations
“Predictive Coding: a Theoretical and Experimental Review”, Millidge et al 2021
“Dataset Distillation With Infinitely Wide Convolutional Networks”, Nguyen et al 2021
Dataset Distillation with Infinitely Wide Convolutional Networks
“Stochastic Batch Acquisition: A Simple Baseline for Deep Active Learning”, Kirsch et al 2021
Stochastic Batch Acquisition: A Simple Baseline for Deep Active Learning
“Adapting the Function Approximation Architecture in Online Reinforcement Learning”, Martin & Modayil 2021
Adapting the Function Approximation Architecture in Online Reinforcement Learning
“B-Pref: Benchmarking Preference-Based Reinforcement Learning”, Lee et al 2021
B-Pref: Benchmarking Preference-Based Reinforcement Learning
“Fully General Online Imitation Learning”, Cohen et al 2021
“When Do Curricula Work?”, Wu et al 2020
“Dataset Meta-Learning from Kernel Ridge-Regression”, Nguyen et al 2020
“Dataset Cartography: Mapping and Diagnosing Datasets With Training Dynamics”, Swayamdipta et al 2020
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
“BanditPAM: Almost Linear Time k-Medoids Clustering via Multi-Armed Bandits”, Tiwari et al 2020
BanditPAM: Almost Linear Time k-Medoids Clustering via Multi-Armed Bandits
“Exploring Bayesian Optimization: Breaking Bayesian Optimization into Small, Sizeable Chunks”, Agnihotri & Batra 2020
Exploring Bayesian Optimization: Breaking Bayesian Optimization into small, sizeable chunks
“Small-GAN: Speeding Up GAN Training Using Core-Sets”, Sinha et al 2019
“A Deep Active Learning System for Species Identification and Counting in Camera Trap Images”, Norouzzadeh et al 2019
A deep active learning system for species identification and counting in camera trap images
“On Warm-Starting Neural Network Training”, Ash & Adams 2019
“Accelerating Deep Learning by Focusing on the Biggest Losers”, Jiang et al 2019
Accelerating Deep Learning by Focusing on the Biggest Losers
“Data Valuation Using Reinforcement Learning”, Yoon et al 2019
“BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning”, Kirsch et al 2019
BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning
“BADGE: Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds”, Ash et al 2019
BADGE: Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds
“Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules”, Ho et al 2019
Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
“Learning Loss for Active Learning”, Yoo & Kweon 2019
“A Recipe for Training Neural Networks”, Karpathy 2019
“ProductNet: a Collection of High-Quality Datasets for Product Representation Learning”, Wang et al 2019
ProductNet: a Collection of High-Quality Datasets for Product Representation Learning
“End-To-End Robotic Reinforcement Learning without Reward Engineering”, Singh et al 2019
End-to-End Robotic Reinforcement Learning without Reward Engineering
“Data Shapley: Equitable Valuation of Data for Machine Learning”, Ghorbani & Zou 2019
Data Shapley: Equitable Valuation of Data for Machine Learning
“Learning from Dialogue After Deployment: Feed Yourself, Chatbot!”, Hancock et al 2019
Learning from Dialogue after Deployment: Feed Yourself, Chatbot!
“The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale”, Kuznetsova et al 2018
“Computational Mechanisms of Curiosity and Goal-Directed Exploration”, Schwartenbeck et al 2018
Computational mechanisms of curiosity and goal-directed exploration
“Conditional Neural Processes”, Garnelo et al 2018
“Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning”, Pang et al 2018
Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning
“More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch”, Calandra et al 2018
More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
“Fingerprint Policy Optimization for Robust Reinforcement Learning”, Paul et al 2018
Fingerprint Policy Optimization for Robust Reinforcement Learning
“AutoAugment: Learning Augmentation Policies from Data”, Cubuk et al 2018
“Optimization, Fast and Slow: Optimally Switching between Local and Bayesian Optimization”, McLeod et al 2018
Optimization, fast and slow: optimally switching between local and Bayesian optimization
“Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks With Existing Applications”, Hadash et al 2018
“Active Learning With Partial Feedback”, Hu et al 2018
“Active, Continual Fine Tuning of Convolutional Neural Networks for Reducing Annotation Efforts”, Zhou et al 2018
Active, Continual Fine Tuning of Convolutional Neural Networks for Reducing Annotation Efforts
“Less Is More: Sampling Chemical Space With Active Learning”, Smith et al 2018
“The Eighty Five Percent Rule for Optimal Learning”, Wilson et al 2018
“ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks”, Kim & Choi 2018
ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks
“Learning a Generative Model for Validity in Complex Discrete Structures”, Janz et al 2017
Learning a Generative Model for Validity in Complex Discrete Structures
“Learning by Asking Questions”, Misra et al 2017
“BlockDrop: Dynamic Inference Paths in Residual Networks”, Wu et al 2017
“Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent”, Yang et al 2017
Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent
“Classification With Costly Features Using Deep Reinforcement Learning”, Janisch et al 2017
Classification with Costly Features using Deep Reinforcement Learning
“Decomposition of Uncertainty in Bayesian Deep Learning for Efficient and Risk-Sensitive Learning”, Depeweg et al 2017
Decomposition of Uncertainty in Bayesian Deep Learning for Efficient and Risk-sensitive Learning
“Why Pay More When You Can Pay Less: A Joint Learning Framework for Active Feature Acquisition and Classification”, Shim et al 2017
“Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks”, Jayaraman & Grauman 2017
Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks
“Active Learning for Convolutional Neural Networks: A Core-Set Approach”, Sener & Savarese 2017
Active Learning for Convolutional Neural Networks: A Core-Set Approach
“Interpretable Active Learning”, Phillips et al 2017
“Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, Sun et al 2017
Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
“A Tutorial on Thompson Sampling”, Russo et al 2017
“Learning to Learn from Noisy Web Videos”, Yeung et al 2017
“Teaching Machines to Describe Images via Natural Language Feedback”, Ling & Fidler 2017
Teaching Machines to Describe Images via Natural Language Feedback
“Ask the Right Questions: Active Question Reformulation With Reinforcement Learning”, Buck et al 2017
Ask the Right Questions: Active Question Reformulation with Reinforcement Learning
“BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography”, Wilber et al 2017
BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography
“PBO: Preferential Bayesian Optimization”, Gonzalez et al 2017
“OHEM: Training Region-Based Object Detectors With Online Hard Example Mining”, Shrivastava et al 2016
OHEM: Training Region-based Object Detectors with Online Hard Example Mining
“The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition”, Krause et al 2015
The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition
“LSUN: Construction of a Large-Scale Image Dataset Using Deep Learning With Humans in the Loop”, Yu et al 2015
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
“Dropout As a Bayesian Approximation: Representing Model Uncertainty in Deep Learning”, Gal & Ghahramani 2015
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
“Just Sort It! A Simple and Effective Approach to Active Preference Learning”, Maystre & Grossglauser 2015
Just Sort It! A Simple and Effective Approach to Active Preference Learning
“Learning With Intelligent Teacher: Similarity Control and Knowledge Transfer”, Vapnik & Izmailov 2015
Learning with Intelligent Teacher: Similarity Control and Knowledge Transfer
“Minimax Analysis of Active Learning”, Hanneke & Yang 2014
“Algorithmic and Human Teaching of Sequential Decision Tasks”, Cakmak & Lopes 2012
“Bayesian Active Learning for Classification and Preference Learning”, Houlsby et al 2011
Bayesian Active Learning for Classification and Preference Learning
“Rates of Convergence in Active Learning”, Hanneke 2011
“The True Sample Complexity of Active Learning”, Balcan et al 2010
“Active Testing for Face Detection and Localization”, Sznitman & Jedynak 2010
“The Wisdom of the Few: a Collaborative Filtering Approach Based on Expert Opinions from the Web”, Amatriain et al 2009
The wisdom of the few: a collaborative filtering approach based on expert opinions from the web
“Learning and Example Selection for Object and Pattern Detection”, Sung 1995
Learning and Example Selection for Object and Pattern Detection
“Information-Based Objective Functions for Active Data Selection”, MacKay 1992
Information-Based Objective Functions for Active Data Selection
“Active Learning Literature Survey”
“Brief Summary of the Panel Discussion at DL Workshop @ICML 2015”
Brief Summary of the Panel Discussion at DL Workshop @ICML 2015:
“Active Learning”
“Aurora’s Approach to Development”
“Active Learning for High Dimensional Inputs Using Bayesian Convolutional Neural Networks”
Active Learning for High Dimensional Inputs using Bayesian Convolutional Neural Networks:
“AI-Guided Robots Are Ready to Sort Your Recyclables”
“When Self-Driving Cars Can’t Help Themselves, Who Takes the Wheel?”
When Self-Driving Cars Can’t Help Themselves, Who Takes the Wheel?
“How a Feel-Good AI Story Went Wrong in Flint: A Machine-Learning Model Showed Promising Results, but City Officials and Their Engineering Contractor Abandoned It.”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
curriculum-learning
training-optimization
active-querying
batch-active-learning
information-optimization
Wikipedia
Miscellaneous
-
https://bair.berkeley.edu/blog/2019/06/07/data_aug/:View External Link:
-
https://explosion.ai/blog/prodigy-annotation-tool-active-learning: -
https://github.com/cranmer/active_sciencing/blob/master/README.md: -
https://medium.com/cruise/cruise-continuous-learning-machine-30d60f4c691b -
https://medium.com/pytorch/road-defect-detection-using-deep-active-learning-98d94fe854d -
https://research.google/blog/estimating-the-impact-of-training-data-with-reinforcement-learning/ -
https://www.cs.ox.ac.uk/people/yarin.gal/website/blog_2248.html: -
https://www.probabilistic-numerics.org/assets/ProbabilisticNumerics.pdf#page=3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
-
https://arxiv.org/abs/2412.06771#deepmind: “Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”, -
https://arxiv.org/abs/2406.11233: “Probing the Decision Boundaries of In-Context Learning in Large Language Models”, -
2024-striethkalthoff.pdf: “Artificial Intelligence for Retrosynthetic Planning Needs Both Data and Expert Knowledge”, -
https://arxiv.org/abs/2310.07096#ibm: “Sparse Universal Transformer”, -
https://arxiv.org/abs/2307.08701#samsung: “AlpaGasus: Training A Better Alpaca With Fewer Data”, -
https://arxiv.org/abs/2307.06440: “No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-Based Language Models”, -
https://arxiv.org/abs/2307.05080: “Estimating Label Quality and Errors in Semantic Segmentation Data via Any Model”, -
https://arxiv.org/abs/2305.10429#google: “DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining”, -
https://arxiv.org/abs/2305.07759#microsoft: “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, -
https://arxiv.org/abs/2304.14318#google: “Q2d: Turning Questions into Dialogs to Teach Models How to Search”, -
https://openreview.net/forum?id=UVDAKQANOW: “Unifying Approaches in Active Learning and Active Sampling via Fisher Information and Information-Theoretic Quantities”, -
https://arxiv.org/abs/2206.07137: “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, -
https://arxiv.org/abs/2006.06856: “BanditPAM: Almost Linear Time k-Medoids Clustering via Multi-Armed Bandits”, -
https://arxiv.org/abs/1905.05393: “Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules”, -
https://karpathy.github.io/2019/04/25/recipe/: “A Recipe for Training Neural Networks”, -
https://arxiv.org/abs/1805.09501#google: “AutoAugment: Learning Augmentation Policies from Data”, -
https://arxiv.org/abs/1802.07427: “Active Learning With Partial Feedback”, -
https://arxiv.org/abs/1511.06789#google: “The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition”, -
2015-vapnik.pdf: “Learning With Intelligent Teacher: Similarity Control and Knowledge Transfer”, -
https://projecteuclid.org/journals/annals-of-statistics/volume-39/issue-1/Rates-of-convergence-in-active-learning/10.1214/10-AOS843.full: “Rates of Convergence in Active Learning”, -
2010-balcan.pdf: “The True Sample Complexity of Active Learning”,