‘retrieval AI’ tag
- See Also
- Gwern
-
Links
- “How We Used GPT-4o for Image Detection With 350 Very Similar, Single Image Classes”, Topalian 2025
- “Jasper and Stella: Distillation of SOTA Embedding Models”, Zhang & Wang 2024
- “Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference”, Warner et al 2024
- “Memory Layers at Scale”, Berges et al 2024
- “Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?”, Yang et al 2024
- “Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models”, Ruis et al 2024
- “Drowning in Documents: Consequences of Scaling Reranker Inference”, Jacob et al 2024
- “Are LLMs Prescient? A Continuous Evaluation Using Daily News As the Oracle”, Dai et al 2024
- “HtmlRAG: HTML Is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems”, Tan et al 2024
- “Long Context RAG Performance of Large Language Models”, Leng et al 2024
- “Inference Scaling for Long-Context Retrieval Augmented Generation”, Yue et al 2024
- “Contextual Document Embeddings”, Morris & Rush 2024
- “Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?”, Lin 2024
- “Masked Mixers for Language Generation and Retrieval”, Badger 2024
- “Hermes 3 Technical Report”, Teknium et al 2024
- “Mixture of A Million Experts”, He 2024
- “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
- “OpenAI’s Colin Jarvis Predicts "Exponential" Advancements in Large Language Model Capabilities during AI Summit London Keynote”, Wodecki 2024
- “State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
- “Retrieval Head Mechanistically Explains Long-Context Factuality”, Wu et al 2024
- “Aligning LLM Agents by Learning Latent Preference from User Edits”, Gao et al 2024
- “Towards Generated Image Provenance Analysis Via Conceptual-Similar-Guided-SLIP Retrieval”, Xia et al 2024
- “FABLES: Evaluating Faithfulness and Content Selection in Book-Length Summarization”, Kim et al 2024
- “Scaling Laws For Dense Retrieval”, Fang et al 2024
- “Long-Form Factuality in Large Language Models”, Wei et al 2024
- “Online Adaptation of Language Models With a Memory of Amortized Contexts (MAC)”, Tack et al 2024
- “RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
- “Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”, Zhai et al 2024
- “Assisting in Writing Wikipedia-Like Articles From Scratch With Large Language Models”, Shao et al 2024
- “RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval”, Sarthi et al 2024
- “RAG vs Fine-Tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture”, Balaguer et al 2024
- “Improving Text Embeddings With Large Language Models”, Wang et al 2023
- “ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent”, Aksitov et al 2023
- “Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models”, Variengien & Winsor 2023
- “Retrieving Conditions from Reference Images for Diffusion Models”, Tang et al 2023
- “Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine”, Nori et al 2023
- “PEARL: Personalizing Large Language Model Writing Assistants With Generation-Calibrated Retrievers”, Mysore et al 2023
- “ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
- “In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
- “SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?”, Jimenez et al 2023
- “Text Embeddings Reveal (Almost) As Much As Text”, Morris et al 2023
- “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
- “ExpeL: LLM Agents Are Experiential Learners”, Zhao et al 2023
- “RAVEN: In-Context Learning With Retrieval-Augmented Encoder-Decoder Language Models”, Huang et al 2023
- “Gzip versus Bag-Of-Words for Text Classification With k-NN”, Opitz 2023
- “Copy Is All You Need”, Lan et al 2023
- “Lost in the Middle: How Language Models Use Long Contexts”, Liu et al 2023
- “LeanDojo: Theorem Proving With Retrieval-Augmented Language Models”, Yang et al 2023
- “Voice Conversion With Just Nearest Neighbors”, Baas et al 2023
- “TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”, Hardt & Sun 2023
- “Landmark Attention: Random-Access Infinite Context Length for Transformers”, Mohtashami & Jaggi 2023
- “WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
- “Long-Term Value of Exploration: Measurements, Findings and Algorithms”, Su et al 2023
- “ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
- “Unlimiformer: Long-Range Transformers With Unlimited Length Input”, Bertsch et al 2023
- “Q2d: Turning Questions into Dialogs to Teach Models How to Search”, Bitton et al 2023
- “CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
- “Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes”, Arora et al 2023
- “Shall We Pretrain Autoregressive Language Models With Retrieval? A Comprehensive Study”, Wang et al 2023
- “MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks”, Kuo et al 2023
- “Mitigating YouTube Recommendation Polarity Using BERT and K-Means Clustering”, Ahmad et al 2023
- “Tag2Text: Guiding Vision-Language Model via Image Tagging”, Huang et al 2023
- “ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, Azerbayev et al 2023
- “Not What You’ve Signed up For: Compromising Real-World LLM-Integrated Applications With Indirect Prompt Injection”, Greshake et al 2023
- “How Does In-Context Learning Help Prompt Tuning?”, Sun et al 2023
- “Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models”, Aksitov et al 2023
- “Large Language Models Are Versatile Decomposers: Decompose Evidence and Questions for Table-Based Reasoning”, Ye et al 2023
- “In-Context Retrieval-Augmented Language Models”, Ram et al 2023
- “Crawling the Internal Knowledge-Base of Language Models”, Cohen et al 2023
- “InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers”, Boytsov et al 2023
- “Why Do Nearest Neighbor Language Models Work?”, Xu et al 2023
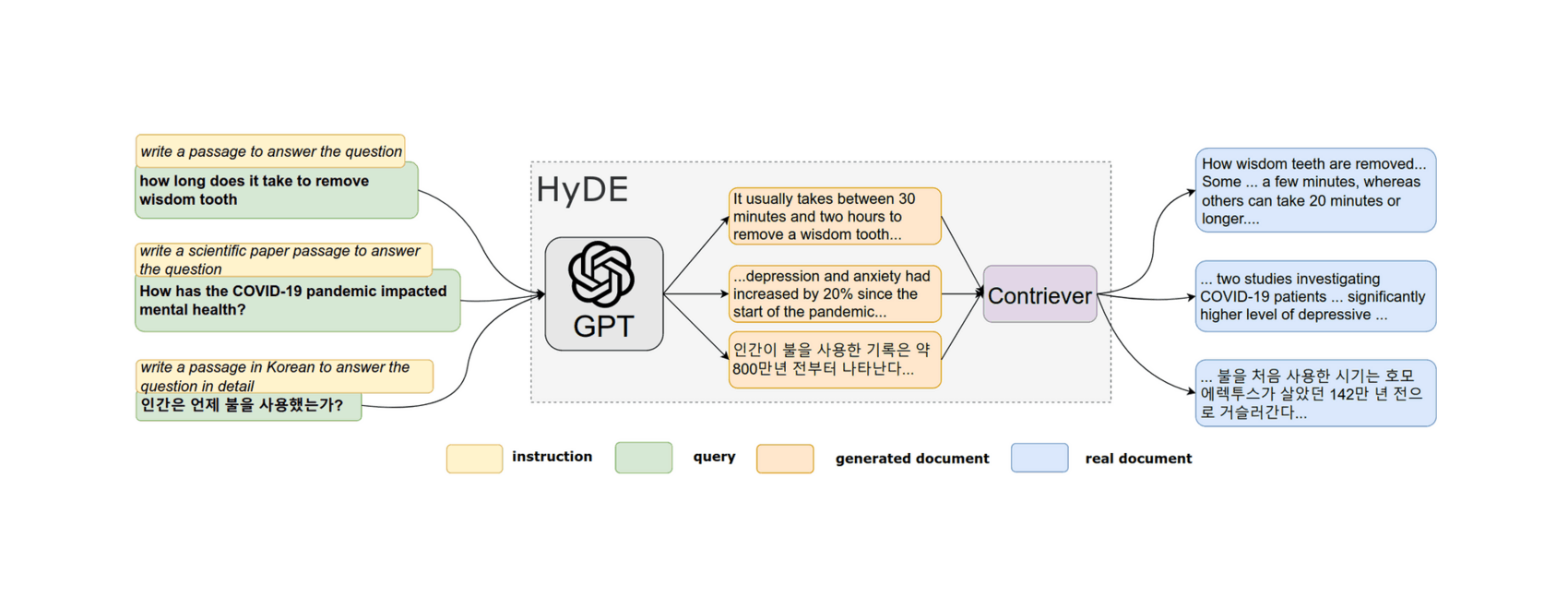
- “Precise Zero-Shot Dense Retrieval without Relevance Labels”, Gao et al 2022
- “Less Is More: Parameter-Free Text Classification With Gzip”, Jiang et al 2022
- “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
- “Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, Wang et al 2022
- “NPM: Nonparametric Masked Language Modeling”, Min et al 2022
- “Retrieval-Augmented Multimodal Language Modeling”, Yasunaga et al 2022
- “GENIUS: Sketch-Based Language Model Pre-Training via Extreme and Selective Masking for Text Generation and Augmentation”, Guo et al 2022
- “TART: Task-Aware Retrieval With Instructions”, Asai et al 2022
- “Large Language Models Struggle to Learn Long-Tail Knowledge”, Kandpal et al 2022
- “RARR: Attributed Text Generation via Post-Hoc Research and Revision”, Gao et al 2022
- “Noise-Robust De-Duplication at Scale”, Silcock et al 2022
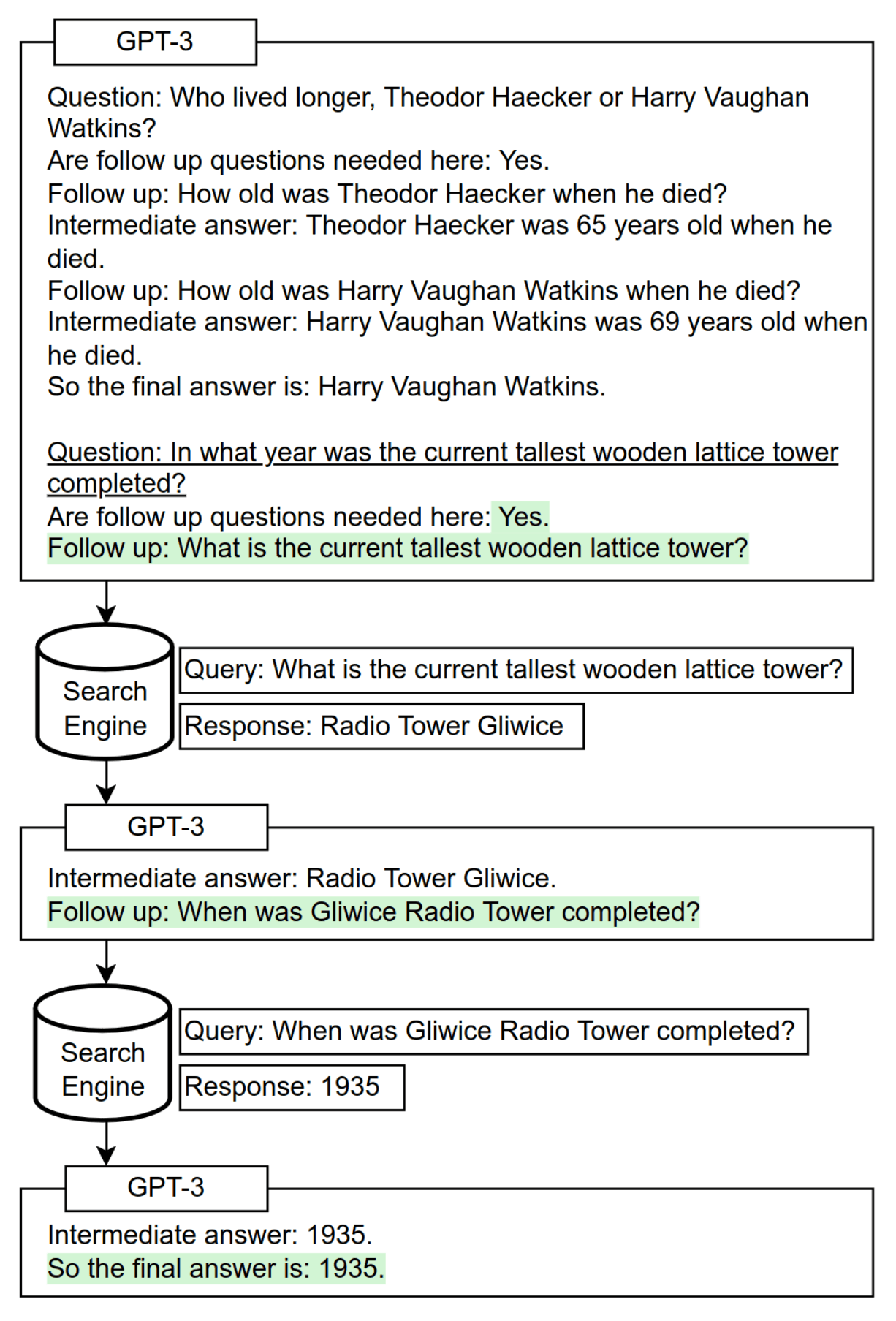
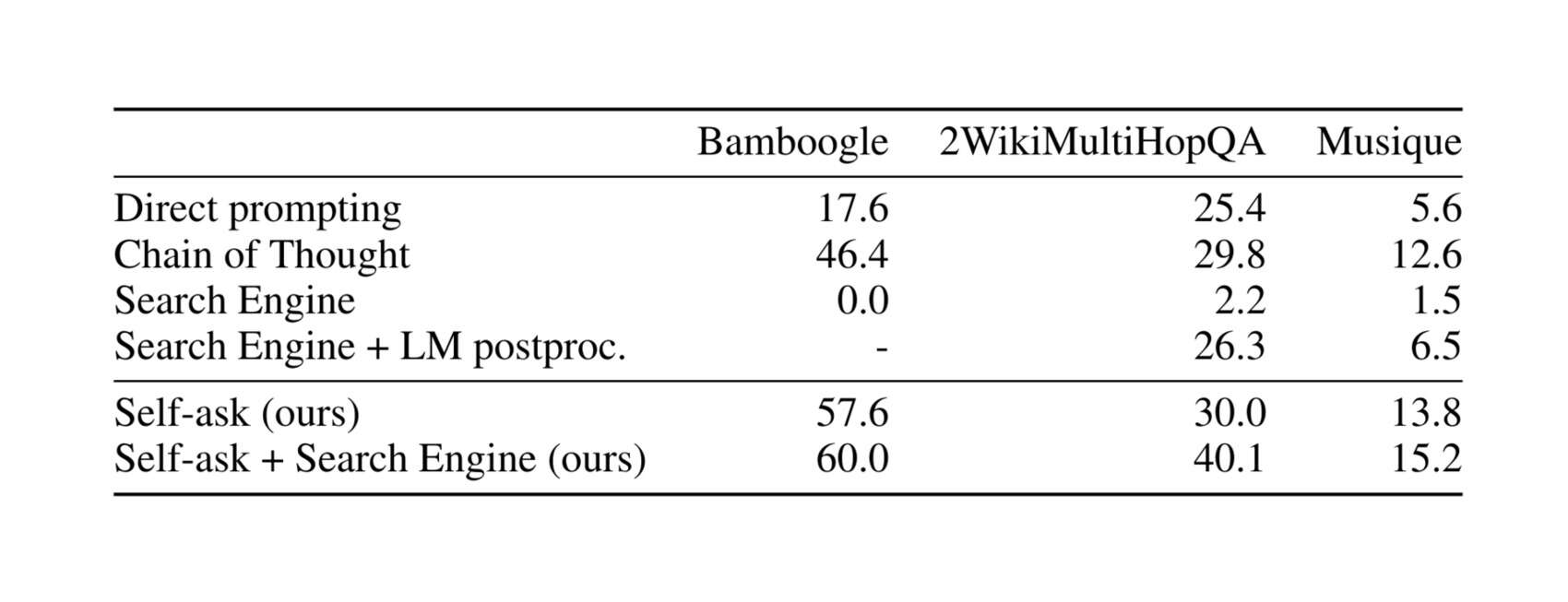
- “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
- “ReAct: Synergizing Reasoning and Acting in Language Models”, Yao et al 2022
- “FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation”, Hofstätter et al 2022
- “Sparrow: Improving Alignment of Dialogue Agents via Targeted Human Judgements”, Glaese et al 2022
- “Generate rather than Retrieve (GenRead): Large Language Models Are Strong Context Generators”, Yu et al 2022
- “Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners”, Su et al 2022
- “Nearest Neighbor Non-Autoregressive Text Generation”, Niwa et al 2022
- “Understanding Scaling Laws for Recommendation Models”, Ardalani et al 2022
- “CorpusBrain: Pre-Train a Generative Retrieval Model for Knowledge-Intensive Language Tasks”, Chen et al 2022
- “RealTime QA: What’s the Answer Right Now?”, Kasai et al 2022
- “Text-Guided Synthesis of Artistic Images With Retrieval-Augmented Diffusion Models”, Rombach et al 2022
- “NewsStories: Illustrating Articles With Visual Summaries”, Tan et al 2022
- “Re2G: Retrieve, Rerank, Generate”, Glass et al 2022
- “Large-Scale Retrieval for Reinforcement Learning”, Humphreys et al 2022
- “A Neural Corpus Indexer for Document Retrieval”, Wang et al 2022
- “Boosting Search Engines With Interactive Agents”, Ciaramita et al 2022
- “Hopular: Modern Hopfield Networks for Tabular Data”, Schäfl et al 2022
- “NaturalProver: Grounded Mathematical Proof Generation With Language Models”, Welleck et al 2022
- “Down and Across: Introducing Crossword-Solving As a New NLP Benchmark”, Kulshreshtha et al 2022
- “PLAID: An Efficient Engine for Late Interaction Retrieval”, Santhanam et al 2022
- “RankGen: Improving Text Generation With Large Ranking Models”, Krishna et al 2022
- “Unifying Language Learning Paradigms”, Tay et al 2022
- “Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis”, Blattmann et al 2022
- “KNN-Diffusion: Image Generation via Large-Scale Retrieval”, Ashual et al 2022
- “Language Models That Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion”, Shuster et al 2022
- “Unsupervised Vision-And-Language Pre-Training via Retrieval-Based Multi-Granular Alignment”, Zhou et al 2022
- “Retrieval Augmented Classification for Long-Tail Visual Recognition”, Long et al 2022
- “Retrieval-Augmented Reinforcement Learning”, Goyal et al 2022
- “Transformer Memory As a Differentiable Search Index”, Tay et al 2022
- “InPars: Data Augmentation for Information Retrieval Using Large Language Models”, Bonifacio et al 2022
- “Text and Code Embeddings by Contrastive Pre-Training”, Neelakantan et al 2022
- “LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
- “Memory-Assisted Prompt Editing to Improve GPT-3 After Deployment”, Madaan et al 2022
- “A Thousand Words Are Worth More Than a Picture: Natural Language-Centric Outside-Knowledge Visual Question Answering”, Gao et al 2022
- “Learning To Retrieve Prompts for In-Context Learning”, Rubin et al 2021
- “Contriever: Towards Unsupervised Dense Information Retrieval With Contrastive Learning”, Izacard et al 2021
- “WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
- “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
- “Large Dual Encoders Are Generalizable Retrievers”, Ni et al 2021
- “You Only Need One Model for Open-Domain Question Answering”, Lee et al 2021
- “Spider: Learning to Retrieve Passages without Supervision”, Ram et al 2021
- “Boosted Dense Retriever”, Lewis et al 2021
- “Improving Language Models by Retrieving from Trillions of Tokens”, Borgeaud et al 2021
- “Human Parity on CommonsenseQA: Augmenting Self-Attention With External Attention”, Xu et al 2021
- “Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
- “LiT: Zero-Shot Transfer With Locked-Image Text Tuning”, Zhai et al 2021
- “Scaling Law for Recommendation Models: Towards General-Purpose User Representations”, Shin et al 2021
- “SPANN: Highly-Efficient Billion-Scale Approximate Nearest Neighbor Search”, Chen et al 2021
- “HTCN: Harmonious Text Colorization Network for Visual-Textual Presentation Design”, Yang et al 2021c
- “Memorizing Transformers”, Wu et al 2021
- “CLOOB: Modern Hopfield Networks With InfoLOOB Outperform CLIP”, Fürst et al 2021
- “One Loss for All: Deep Hashing With a Single Cosine Similarity Based Learning Objective”, Hoe et al 2021
- “SPLADE V2: Sparse Lexical and Expansion Model for Information Retrieval”, Formal et al 2021
- “MeLT: Message-Level Transformer With Masked Document Representations As Pre-Training for Stance Detection”, Matero et al 2021
- “EfficientCLIP: Efficient Cross-Modal Pre-Training by Ensemble Confident Learning and Language Modeling”, Wang et al 2021
- “Contrastive Language-Image Pre-Training for the Italian Language”, Bianchi et al 2021
- “Sentence-T5: Scalable Sentence Encoders from Pre-Trained Text-To-Text Models”, Ni et al 2021
- “Billion-Scale Pretraining With Vision Transformers for Multi-Task Visual Representations”, Beal et al 2021
- “MuSiQue: Multi-Hop Questions via Single-Hop Question Composition”, Trivedi et al 2021
- “Internet-Augmented Dialogue Generation”, Komeili et al 2021
- “SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking”, Formal et al 2021
- “CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”, Fang et al 2021
- “A Multi-Level Attention Model for Evidence-Based Fact Checking”, Kruengkrai et al 2021
- “Towards Mental Time Travel: a Hierarchical Memory for Reinforcement Learning Agents”, Lampinen et al 2021
- “RetGen: A Joint Framework for Retrieval and Grounded Text Generation Modeling”, Zhang et al 2021
- “Not All Memories Are Created Equal: Learning to Forget by Expiring”, Sukhbaatar et al 2021
- “Rethinking Search: Making Domain Experts out of Dilettantes”, Metzler et al 2021
- “SimCSE: Simple Contrastive Learning of Sentence Embeddings”, Gao et al 2021
- “BEIR: A Heterogenous Benchmark for Zero-Shot Evaluation of Information Retrieval Models”, Thakur et al 2021
- “Retrieval Augmentation Reduces Hallucination in Conversation”, Shuster et al 2021
- “TSDAE: Using Transformer-Based Sequential Denoising Autoencoder for Unsupervised Sentence Embedding Learning”, Wang et al 2021
- “NaturalProofs: Mathematical Theorem Proving in Natural Language”, Welleck et al 2021
- “China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model.”, Synced 2021
- “Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
- “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
- “Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers”, Hendricks et al 2021
- “Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup”, Gao et al 2021
- “Constructing A Multi-Hop QA Dataset for Comprehensive Evaluation of Reasoning Steps”, Ho et al 2020
- “Current Limitations of Language Models: What You Need Is Retrieval”, Komatsuzaki 2020
- “Leveraging Passage Retrieval With Generative Models for Open Domain Question Answering”, Izacard & Grave 2020
- “Pre-Training via Paraphrasing”, Lewis et al 2020
- “Memory Transformer”, Burtsev et al 2020
- “M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-Training”, Ni et al 2020
- “System for Searching Illustrations of Anime Characters Focusing on Degrees of Character Attributes”, Koyama et al 2020
- “Open-Retrieval Conversational Question Answering”, Qu et al 2020
- “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, Lewis et al 2020
- “Dense Passage Retrieval for Open-Domain Question Answering”, Karpukhin et al 2020
- “Learning to Scale Multilingual Representations for Vision-Language Tasks”, Burns et al 2020
- “REALM: Retrieval-Augmented Language Model Pre-Training”, Guu et al 2020
- “How Much Knowledge Can You Pack Into the Parameters of a Language Model?”, Roberts et al 2020
- “REALM: Integrating Retrieval into Language Representation Models”, Chang & Guu 2020
- “The Importance of Deconstruction”, Weinberger 2020
- “SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning”, Wang et al 2019
- “Generalization through Memorization: Nearest Neighbor Language Models”, Khandelwal et al 2019
- “OHAC: Online Hierarchical Clustering Approximations”, Menon et al 2019
- “MULE: Multimodal Universal Language Embedding”, Kim et al 2019
- “Language Models As Knowledge Bases?”, Petroni et al 2019
- “Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks”, Reimers & Gurevych 2019
- “Metalearned Neural Memory”, Munkhdalai et al 2019
- “ELI5: Long Form Question Answering”, Fan et al 2019
- “Large Memory Layers With Product Keys”, Lample et al 2019
- “OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge”, Marino et al 2019
- “Dynamic Evaluation of Transformer Language Models”, Krause et al 2019
- “LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game”, Urbanek et al 2019
- “Top-K Off-Policy Correction for a REINFORCE Recommender System”, Chen et al 2018
- “FEVER: a Large-Scale Dataset for Fact Extraction and VERification”, Thorne et al 2018
- “Towards Deep Modeling of Music Semantics Using EEG Regularizers”, Raposo et al 2017
- “Learning to Organize Knowledge and Answer Questions With N-Gram Machines”, Yang et al 2017
- “Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning”, Zhong et al 2017
- “Bolt: Accelerated Data Mining With Fast Vector Compression”, Blalock & Guttag 2017
- “Ask the Right Questions: Active Question Reformulation With Reinforcement Learning”, Buck et al 2017
- “Get To The Point: Summarization With Pointer-Generator Networks”, See et al 2017
- “Neural Episodic Control”, Pritzel et al 2017
- “Improving Neural Language Models With a Continuous Cache”, Grave et al 2016
- “Visual Dialog”, Das et al 2016
- “Scaling Memory-Augmented Neural Networks With Sparse Reads and Writes”, Rae et al 2016
- “Deep Neural Networks for YouTube Recommendations”, Covington et al 2016
- “One-Shot Learning With Memory-Augmented Neural Networks”, Santoro et al 2016
- “Improving Information Extraction by Acquiring External Evidence With Reinforcement Learning”, Narasimhan et al 2016
- “PlaNet—Photo Geolocation With Convolutional Neural Networks”, Weyand et al 2016
-
“
Illustration2Vec: a Semantic Vector Representation of Illustrations”, Masaki & Matsui 2015 - “Neural Turing Machines”, Graves et al 2014
- “Learning Ordered Representations With Nested Dropout”, Rippel et al 2014
- “Learning to Win by Reading Manuals in a Monte-Carlo Framework”, Branavan et al 2014
- “Ukiyo-E Search”, Resig 2013
- “SimHash: Hash-Based Similarity Detection”, Sadowski & Levin 2007
- “This Week’s Citation Classic: Nearest Neighbor Pattern Classification”, Cover 1982
- “Nearest Neighbor Pattern Classification”, Cover & Hart 1967
- “RETRO Is Blazingly Fast”
- “ANN-Benchmarks Is a Benchmarking Environment for Approximate Nearest Neighbor Algorithms Search. This Website Contains the Current Benchmarking Results. Please Visit Https://github.com/erikbern/ann-Benchmarks/ to Get an Overview over Evaluated Data Sets and Algorithms. Make a Pull Request on Github to Add Your Own Code or Improvements to the Benchmarking System.”
- “Find Anything Blazingly Fast With Google's Vector Search Technology”
- “This Anime Does Not Exist, Search: This Notebook Uses the Precomputed CLIP Feature Vectors for 100k Images from TADNE”
- “Differentiable Neural Computers”
- “Binary Vector Embeddings Are so Cool”
- “Understanding the BM25 Full Text Search Algorithm”
- “PaddlePaddle/RocketQA: 🚀 RocketQA, Dense Retrieval for Information Retrieval and Question Answering, including Both Chinese and English State-Of-The-Art Models.”
- “Building a Vector Database in 2GB for 36 Million Wikipedia Passages”
- “Finally, a Replacement for BERT: Introducing ModernBERT”
- “The Illustrated Retrieval Transformer”
- “100M Token Context Windows”
- “The Super Effectiveness of Pokémon Embeddings Using Only Raw JSON and Images”
- “Same Energy”
- “Embedding Paragraphs from My Blog With E5-Large-V2”, Willison 2025
- “European Parliament Revolutionizes Archive Access With Claude AI”, Anthropic 2025
- “WikiCrow”
- “Azure AI Milestone: Microsoft KEAR Surpasses Human Performance on CommonsenseQA Benchmark”
- “Turing Bletchley: A Universal Image Language Representation Model by Microsoft”
- l4rz
- Sort By Magic
- Wikipedia
- Miscellaneous
- Bibliography
See Also
Gwern
“Hierarchical Embeddings for Text Search”, Gwern 2024
“Absolute Unit NNs: Regression-Based MLPs for Everything”, Gwern 2023
“Number Search Engine via NN Embeddings”, Gwern 2024
Links
“How We Used GPT-4o for Image Detection With 350 Very Similar, Single Image Classes”, Topalian 2025
How we used GPT-4o for image detection with 350 very similar, single image classes
“Jasper and Stella: Distillation of SOTA Embedding Models”, Zhang & Wang 2024
“Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference”, Warner et al 2024
“Memory Layers at Scale”, Berges et al 2024
“Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?”, Yang et al 2024
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
“Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models”, Ruis et al 2024
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
“Drowning in Documents: Consequences of Scaling Reranker Inference”, Jacob et al 2024
Drowning in Documents: Consequences of Scaling Reranker Inference
“Are LLMs Prescient? A Continuous Evaluation Using Daily News As the Oracle”, Dai et al 2024
Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle
“HtmlRAG: HTML Is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems”, Tan et al 2024
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
“Long Context RAG Performance of Large Language Models”, Leng et al 2024
“Inference Scaling for Long-Context Retrieval Augmented Generation”, Yue et al 2024
Inference Scaling for Long-Context Retrieval Augmented Generation
“Contextual Document Embeddings”, Morris & Rush 2024
“Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?”, Lin 2024
Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?
“Masked Mixers for Language Generation and Retrieval”, Badger 2024
“Hermes 3 Technical Report”, Teknium et al 2024
“Mixture of A Million Experts”, He 2024
“Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
“OpenAI’s Colin Jarvis Predicts "Exponential" Advancements in Large Language Model Capabilities during AI Summit London Keynote”, Wodecki 2024
“State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
“Retrieval Head Mechanistically Explains Long-Context Factuality”, Wu et al 2024
Retrieval Head Mechanistically Explains Long-Context Factuality
“Aligning LLM Agents by Learning Latent Preference from User Edits”, Gao et al 2024
Aligning LLM Agents by Learning Latent Preference from User Edits
“Towards Generated Image Provenance Analysis Via Conceptual-Similar-Guided-SLIP Retrieval”, Xia et al 2024
Towards Generated Image Provenance Analysis Via Conceptual-Similar-Guided-SLIP Retrieval
“FABLES: Evaluating Faithfulness and Content Selection in Book-Length Summarization”, Kim et al 2024
FABLES: Evaluating faithfulness and content selection in book-length summarization
“Scaling Laws For Dense Retrieval”, Fang et al 2024
“Long-Form Factuality in Large Language Models”, Wei et al 2024
“Online Adaptation of Language Models With a Memory of Amortized Contexts (MAC)”, Tack et al 2024
Online Adaptation of Language Models with a Memory of Amortized Contexts (MAC)
“RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
“Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”, Zhai et al 2024
“Assisting in Writing Wikipedia-Like Articles From Scratch With Large Language Models”, Shao et al 2024
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
“RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval”, Sarthi et al 2024
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
“RAG vs Fine-Tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture”, Balaguer et al 2024
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
“Improving Text Embeddings With Large Language Models”, Wang et al 2023
“ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent”, Aksitov et al 2023
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
“Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models”, Variengien & Winsor 2023
Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models
“Retrieving Conditions from Reference Images for Diffusion Models”, Tang et al 2023
Retrieving Conditions from Reference Images for Diffusion Models
“Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine”, Nori et al 2023
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
“PEARL: Personalizing Large Language Model Writing Assistants With Generation-Calibrated Retrievers”, Mysore et al 2023
PEARL: Personalizing Large Language Model Writing Assistants with Generation-Calibrated Retrievers
“ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
“In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries
“SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?”, Jimenez et al 2023
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
“Text Embeddings Reveal (Almost) As Much As Text”, Morris et al 2023
“FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
“ExpeL: LLM Agents Are Experiential Learners”, Zhao et al 2023
“RAVEN: In-Context Learning With Retrieval-Augmented Encoder-Decoder Language Models”, Huang et al 2023
RAVEN: In-Context Learning with Retrieval-Augmented Encoder-Decoder Language Models
“Gzip versus Bag-Of-Words for Text Classification With k-NN”, Opitz 2023
“Copy Is All You Need”, Lan et al 2023
“Lost in the Middle: How Language Models Use Long Contexts”, Liu et al 2023
“LeanDojo: Theorem Proving With Retrieval-Augmented Language Models”, Yang et al 2023
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
“Voice Conversion With Just Nearest Neighbors”, Baas et al 2023
“TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”, Hardt & Sun 2023
TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models
“Landmark Attention: Random-Access Infinite Context Length for Transformers”, Mohtashami & Jaggi 2023
Landmark Attention: Random-Access Infinite Context Length for Transformers
“WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
“Long-Term Value of Exploration: Measurements, Findings and Algorithms”, Su et al 2023
Long-Term Value of Exploration: Measurements, Findings and Algorithms
“ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
“Unlimiformer: Long-Range Transformers With Unlimited Length Input”, Bertsch et al 2023
Unlimiformer: Long-Range Transformers with Unlimited Length Input
“Q2d: Turning Questions into Dialogs to Teach Models How to Search”, Bitton et al 2023
q2d: Turning Questions into Dialogs to Teach Models How to Search
“CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval
“Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes”, Arora et al 2023
Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
“Shall We Pretrain Autoregressive Language Models With Retrieval? A Comprehensive Study”, Wang et al 2023
Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study
“MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks”, Kuo et al 2023
MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
“Mitigating YouTube Recommendation Polarity Using BERT and K-Means Clustering”, Ahmad et al 2023
Mitigating YouTube Recommendation Polarity using BERT and K-Means Clustering
“Tag2Text: Guiding Vision-Language Model via Image Tagging”, Huang et al 2023
“ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, Azerbayev et al 2023
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics
“Not What You’ve Signed up For: Compromising Real-World LLM-Integrated Applications With Indirect Prompt Injection”, Greshake et al 2023
“How Does In-Context Learning Help Prompt Tuning?”, Sun et al 2023
“Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models”, Aksitov et al 2023
Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models
“Large Language Models Are Versatile Decomposers: Decompose Evidence and Questions for Table-Based Reasoning”, Ye et al 2023
“In-Context Retrieval-Augmented Language Models”, Ram et al 2023
“Crawling the Internal Knowledge-Base of Language Models”, Cohen et al 2023
“InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers”, Boytsov et al 2023
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers
“Why Do Nearest Neighbor Language Models Work?”, Xu et al 2023
“Precise Zero-Shot Dense Retrieval without Relevance Labels”, Gao et al 2022
“Less Is More: Parameter-Free Text Classification With Gzip”, Jiang et al 2022
“One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)
“Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, Wang et al 2022
Text Embeddings by Weakly-Supervised Contrastive Pre-training
“NPM: Nonparametric Masked Language Modeling”, Min et al 2022
“Retrieval-Augmented Multimodal Language Modeling”, Yasunaga et al 2022
“GENIUS: Sketch-Based Language Model Pre-Training via Extreme and Selective Masking for Text Generation and Augmentation”, Guo et al 2022
“TART: Task-Aware Retrieval With Instructions”, Asai et al 2022
“Large Language Models Struggle to Learn Long-Tail Knowledge”, Kandpal et al 2022
“RARR: Attributed Text Generation via Post-Hoc Research and Revision”, Gao et al 2022
RARR: Attributed Text Generation via Post-hoc Research and Revision
“Noise-Robust De-Duplication at Scale”, Silcock et al 2022
“Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)
“ReAct: Synergizing Reasoning and Acting in Language Models”, Yao et al 2022
“FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation”, Hofstätter et al 2022
FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation
“Sparrow: Improving Alignment of Dialogue Agents via Targeted Human Judgements”, Glaese et al 2022
Sparrow: Improving alignment of dialogue agents via targeted human judgements
“Generate rather than Retrieve (GenRead): Large Language Models Are Strong Context Generators”, Yu et al 2022
Generate rather than Retrieve (GenRead): Large Language Models are Strong Context Generators
“Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners”, Su et al 2022
Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners
“Nearest Neighbor Non-Autoregressive Text Generation”, Niwa et al 2022
“Understanding Scaling Laws for Recommendation Models”, Ardalani et al 2022
“CorpusBrain: Pre-Train a Generative Retrieval Model for Knowledge-Intensive Language Tasks”, Chen et al 2022
CorpusBrain: Pre-train a Generative Retrieval Model for Knowledge-Intensive Language Tasks
“RealTime QA: What’s the Answer Right Now?”, Kasai et al 2022
“Text-Guided Synthesis of Artistic Images With Retrieval-Augmented Diffusion Models”, Rombach et al 2022
Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
“NewsStories: Illustrating Articles With Visual Summaries”, Tan et al 2022
“Re2G: Retrieve, Rerank, Generate”, Glass et al 2022
“Large-Scale Retrieval for Reinforcement Learning”, Humphreys et al 2022
“A Neural Corpus Indexer for Document Retrieval”, Wang et al 2022
“Boosting Search Engines With Interactive Agents”, Ciaramita et al 2022
“Hopular: Modern Hopfield Networks for Tabular Data”, Schäfl et al 2022
“NaturalProver: Grounded Mathematical Proof Generation With Language Models”, Welleck et al 2022
NaturalProver: Grounded Mathematical Proof Generation with Language Models
“Down and Across: Introducing Crossword-Solving As a New NLP Benchmark”, Kulshreshtha et al 2022
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
“PLAID: An Efficient Engine for Late Interaction Retrieval”, Santhanam et al 2022
“RankGen: Improving Text Generation With Large Ranking Models”, Krishna et al 2022
RankGen: Improving Text Generation with Large Ranking Models
“Unifying Language Learning Paradigms”, Tay et al 2022
“Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis”, Blattmann et al 2022
Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis
“KNN-Diffusion: Image Generation via Large-Scale Retrieval”, Ashual et al 2022
“Language Models That Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion”, Shuster et al 2022
“Unsupervised Vision-And-Language Pre-Training via Retrieval-Based Multi-Granular Alignment”, Zhou et al 2022
Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment
“Retrieval Augmented Classification for Long-Tail Visual Recognition”, Long et al 2022
Retrieval Augmented Classification for Long-Tail Visual Recognition
“Retrieval-Augmented Reinforcement Learning”, Goyal et al 2022
“Transformer Memory As a Differentiable Search Index”, Tay et al 2022
“InPars: Data Augmentation for Information Retrieval Using Large Language Models”, Bonifacio et al 2022
InPars: Data Augmentation for Information Retrieval using Large Language Models
“Text and Code Embeddings by Contrastive Pre-Training”, Neelakantan et al 2022
“LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
“Memory-Assisted Prompt Editing to Improve GPT-3 After Deployment”, Madaan et al 2022
Memory-assisted prompt editing to improve GPT-3 after deployment
“A Thousand Words Are Worth More Than a Picture: Natural Language-Centric Outside-Knowledge Visual Question Answering”, Gao et al 2022
“Learning To Retrieve Prompts for In-Context Learning”, Rubin et al 2021
“Contriever: Towards Unsupervised Dense Information Retrieval With Contrastive Learning”, Izacard et al 2021
Contriever: Towards Unsupervised Dense Information Retrieval with Contrastive Learning
“WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
WebGPT: Browser-assisted question-answering with human feedback
“WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
WebGPT: Improving the factual accuracy of language models through web browsing
“Large Dual Encoders Are Generalizable Retrievers”, Ni et al 2021
“You Only Need One Model for Open-Domain Question Answering”, Lee et al 2021
“Spider: Learning to Retrieve Passages without Supervision”, Ram et al 2021
“Boosted Dense Retriever”, Lewis et al 2021
“Improving Language Models by Retrieving from Trillions of Tokens”, Borgeaud et al 2021
Improving language models by retrieving from trillions of tokens
“Human Parity on CommonsenseQA: Augmenting Self-Attention With External Attention”, Xu et al 2021
Human Parity on CommonsenseQA: Augmenting Self-Attention with External Attention
“Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
“LiT: Zero-Shot Transfer With Locked-Image Text Tuning”, Zhai et al 2021
“Scaling Law for Recommendation Models: Towards General-Purpose User Representations”, Shin et al 2021
Scaling Law for Recommendation Models: Towards General-purpose User Representations
“SPANN: Highly-Efficient Billion-Scale Approximate Nearest Neighbor Search”, Chen et al 2021
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search
“HTCN: Harmonious Text Colorization Network for Visual-Textual Presentation Design”, Yang et al 2021c
HTCN: Harmonious Text Colorization Network for Visual-Textual Presentation Design
“Memorizing Transformers”, Wu et al 2021
“CLOOB: Modern Hopfield Networks With InfoLOOB Outperform CLIP”, Fürst et al 2021
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
“One Loss for All: Deep Hashing With a Single Cosine Similarity Based Learning Objective”, Hoe et al 2021
One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective
“SPLADE V2: Sparse Lexical and Expansion Model for Information Retrieval”, Formal et al 2021
SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval
“MeLT: Message-Level Transformer With Masked Document Representations As Pre-Training for Stance Detection”, Matero et al 2021
“EfficientCLIP: Efficient Cross-Modal Pre-Training by Ensemble Confident Learning and Language Modeling”, Wang et al 2021
“Contrastive Language-Image Pre-Training for the Italian Language”, Bianchi et al 2021
Contrastive Language-Image Pre-training for the Italian Language
“Sentence-T5: Scalable Sentence Encoders from Pre-Trained Text-To-Text Models”, Ni et al 2021
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
“Billion-Scale Pretraining With Vision Transformers for Multi-Task Visual Representations”, Beal et al 2021
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
“MuSiQue: Multi-Hop Questions via Single-Hop Question Composition”, Trivedi et al 2021
MuSiQue: Multi-hop Questions via Single-hop Question Composition
“Internet-Augmented Dialogue Generation”, Komeili et al 2021
“SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking”, Formal et al 2021
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
“CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”, Fang et al 2021
“A Multi-Level Attention Model for Evidence-Based Fact Checking”, Kruengkrai et al 2021
A Multi-Level Attention Model for Evidence-Based Fact Checking
“Towards Mental Time Travel: a Hierarchical Memory for Reinforcement Learning Agents”, Lampinen et al 2021
Towards mental time travel: a hierarchical memory for reinforcement learning agents
“RetGen: A Joint Framework for Retrieval and Grounded Text Generation Modeling”, Zhang et al 2021
RetGen: A Joint framework for Retrieval and Grounded Text Generation Modeling
“Not All Memories Are Created Equal: Learning to Forget by Expiring”, Sukhbaatar et al 2021
Not All Memories are Created Equal: Learning to Forget by Expiring
“Rethinking Search: Making Domain Experts out of Dilettantes”, Metzler et al 2021
“SimCSE: Simple Contrastive Learning of Sentence Embeddings”, Gao et al 2021
“BEIR: A Heterogenous Benchmark for Zero-Shot Evaluation of Information Retrieval Models”, Thakur et al 2021
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
“Retrieval Augmentation Reduces Hallucination in Conversation”, Shuster et al 2021
Retrieval Augmentation Reduces Hallucination in Conversation
“TSDAE: Using Transformer-Based Sequential Denoising Autoencoder for Unsupervised Sentence Embedding Learning”, Wang et al 2021
“NaturalProofs: Mathematical Theorem Proving in Natural Language”, Welleck et al 2021
NaturalProofs: Mathematical Theorem Proving in Natural Language
“China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model.”, Synced 2021
“Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence (VitaminC)
“ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
“Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers”, Hendricks et al 2021
Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
“Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup”, Gao et al 2021
Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup
“Constructing A Multi-Hop QA Dataset for Comprehensive Evaluation of Reasoning Steps”, Ho et al 2020
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
“Current Limitations of Language Models: What You Need Is Retrieval”, Komatsuzaki 2020
Current Limitations of Language Models: What You Need is Retrieval
“Leveraging Passage Retrieval With Generative Models for Open Domain Question Answering”, Izacard & Grave 2020
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
“Pre-Training via Paraphrasing”, Lewis et al 2020
“Memory Transformer”, Burtsev et al 2020
“M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-Training”, Ni et al 2020
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
“System for Searching Illustrations of Anime Characters Focusing on Degrees of Character Attributes”, Koyama et al 2020
System for searching illustrations of anime characters focusing on degrees of character attributes
“Open-Retrieval Conversational Question Answering”, Qu et al 2020
“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, Lewis et al 2020
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
“Dense Passage Retrieval for Open-Domain Question Answering”, Karpukhin et al 2020
“Learning to Scale Multilingual Representations for Vision-Language Tasks”, Burns et al 2020
Learning to Scale Multilingual Representations for Vision-Language Tasks
“REALM: Retrieval-Augmented Language Model Pre-Training”, Guu et al 2020
“How Much Knowledge Can You Pack Into the Parameters of a Language Model?”, Roberts et al 2020
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
“REALM: Integrating Retrieval into Language Representation Models”, Chang & Guu 2020
REALM: Integrating Retrieval into Language Representation Models
“The Importance of Deconstruction”, Weinberger 2020
“SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning”, Wang et al 2019
SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning
“Generalization through Memorization: Nearest Neighbor Language Models”, Khandelwal et al 2019
Generalization through Memorization: Nearest Neighbor Language Models
“OHAC: Online Hierarchical Clustering Approximations”, Menon et al 2019
“MULE: Multimodal Universal Language Embedding”, Kim et al 2019
“Language Models As Knowledge Bases?”, Petroni et al 2019
“Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks”, Reimers & Gurevych 2019
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
“Metalearned Neural Memory”, Munkhdalai et al 2019
“ELI5: Long Form Question Answering”, Fan et al 2019
“Large Memory Layers With Product Keys”, Lample et al 2019
“OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge”, Marino et al 2019
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
“Dynamic Evaluation of Transformer Language Models”, Krause et al 2019
“LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game”, Urbanek et al 2019
LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game
“Top-K Off-Policy Correction for a REINFORCE Recommender System”, Chen et al 2018
Top-K Off-Policy Correction for a REINFORCE Recommender System
“FEVER: a Large-Scale Dataset for Fact Extraction and VERification”, Thorne et al 2018
FEVER: a large-scale dataset for Fact Extraction and VERification
“Towards Deep Modeling of Music Semantics Using EEG Regularizers”, Raposo et al 2017
Towards Deep Modeling of Music Semantics using EEG Regularizers
“Learning to Organize Knowledge and Answer Questions With N-Gram Machines”, Yang et al 2017
Learning to Organize Knowledge and Answer Questions with N-Gram Machines
“Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning”, Zhong et al 2017
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
“Bolt: Accelerated Data Mining With Fast Vector Compression”, Blalock & Guttag 2017
“Ask the Right Questions: Active Question Reformulation With Reinforcement Learning”, Buck et al 2017
Ask the Right Questions: Active Question Reformulation with Reinforcement Learning
“Get To The Point: Summarization With Pointer-Generator Networks”, See et al 2017
Get To The Point: Summarization with Pointer-Generator Networks
“Neural Episodic Control”, Pritzel et al 2017
“Improving Neural Language Models With a Continuous Cache”, Grave et al 2016
“Visual Dialog”, Das et al 2016
“Scaling Memory-Augmented Neural Networks With Sparse Reads and Writes”, Rae et al 2016
Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes
“Deep Neural Networks for YouTube Recommendations”, Covington et al 2016
“One-Shot Learning With Memory-Augmented Neural Networks”, Santoro et al 2016
“Improving Information Extraction by Acquiring External Evidence With Reinforcement Learning”, Narasimhan et al 2016
Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning
“PlaNet—Photo Geolocation With Convolutional Neural Networks”, Weyand et al 2016
“Illustration2Vec: a Semantic Vector Representation of Illustrations”, Masaki & Matsui 2015
Illustration2Vec: a semantic vector representation of illustrations
“Neural Turing Machines”, Graves et al 2014
“Learning Ordered Representations With Nested Dropout”, Rippel et al 2014
“Ukiyo-E Search”, Resig 2013
“SimHash: Hash-Based Similarity Detection”, Sadowski & Levin 2007
“This Week’s Citation Classic: Nearest Neighbor Pattern Classification”, Cover 1982
This Week’s Citation Classic: Nearest Neighbor Pattern Classification
“Nearest Neighbor Pattern Classification”, Cover & Hart 1967
“RETRO Is Blazingly Fast”
“ANN-Benchmarks Is a Benchmarking Environment for Approximate Nearest Neighbor Algorithms Search. This Website Contains the Current Benchmarking Results. Please Visit Https://github.com/erikbern/ann-Benchmarks/ to Get an Overview over Evaluated Data Sets and Algorithms. Make a Pull Request on Github to Add Your Own Code or Improvements to the Benchmarking System.”
“Find Anything Blazingly Fast With Google's Vector Search Technology”
Find anything blazingly fast with Google's vector search technology:
View HTML (29MB):
/doc/www/cloud.google.com/657bb4da76626fc37d1454bb197b0f5dec00ebd9.html
“This Anime Does Not Exist, Search: This Notebook Uses the Precomputed CLIP Feature Vectors for 100k Images from TADNE”
“Differentiable Neural Computers”
“Binary Vector Embeddings Are so Cool”
“Understanding the BM25 Full Text Search Algorithm”
“PaddlePaddle/RocketQA: 🚀 RocketQA, Dense Retrieval for Information Retrieval and Question Answering, including Both Chinese and English State-Of-The-Art Models.”
“Building a Vector Database in 2GB for 36 Million Wikipedia Passages”
Building a vector database in 2GB for 36 million Wikipedia passages
“Finally, a Replacement for BERT: Introducing ModernBERT”
“The Illustrated Retrieval Transformer”
“100M Token Context Windows”
“The Super Effectiveness of Pokémon Embeddings Using Only Raw JSON and Images”
The Super Effectiveness of Pokémon Embeddings Using Only Raw JSON and Images:
View External Link:
“Same Energy”
“Embedding Paragraphs from My Blog With E5-Large-V2”, Willison 2025
“European Parliament Revolutionizes Archive Access With Claude AI”, Anthropic 2025
European Parliament Revolutionizes Archive Access with Claude AI
“WikiCrow”
WikiCrow:
“Azure AI Milestone: Microsoft KEAR Surpasses Human Performance on CommonsenseQA Benchmark”
Azure AI milestone: Microsoft KEAR surpasses human performance on CommonsenseQA benchmark:
View HTML (37MB):
/doc/www/www.microsoft.com/8312ec6281c2f762a6d932c5023da466a143a533.html
“Turing Bletchley: A Universal Image Language Representation Model by Microsoft”
Turing Bletchley: A Universal Image Language Representation model by Microsoft:
l4rz
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
nlp-advancements math-proofs model-alignment knowledge-representation clustering-techniques ai-tools
recommendation-systems
provenance-analysis
memory-augmented
retrieval-augmented
Wikipedia
Miscellaneous
-
https://ai.meta.com/blog/next-generation-meta-training-inference-accelerator-AI-MTIA/: -
https://aimd.app/blog/2024-01-16-using-ai-to-overengineer-404-pages -
https://ashvardanian.com/posts/python-c-assembly-comparison/: -
https://blog.pgvecto.rs/my-binary-vector-search-is-better-than-your-fp32-vectors: -
https://cookbook.openai.com/examples/tag_caption_images_with_gpt4v -
https://economistwritingeveryday.com/2024/01/07/using-phind-for-academic-references/: -
https://every.to/chain-of-thought/gpt-4-is-a-reasoning-engine: -
https://every.to/chain-of-thought/i-spent-a-week-with-gemini-pro-1-5-it-s-fantastic: -
https://openai.com/blog/introducing-text-and-code-embeddings/ -
https://openai.com/index/new-embedding-models-and-api-updates/ -
https://platform.openai.com/docs/guides/embeddings/use-cases: -
https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/multi_vector/: -
https://simonwillison.net/2024/Apr/17/ai-for-data-journalism/ -
https://til.simonwillison.net/llms/claude-hacker-news-themes: -
https://www.buildt.ai/blog/viral-ripout:View HTML (19MB):
/doc/www/www.buildt.ai/578673ced29982f87eb8e930f5e6d692a44fed4e.html -
https://www.oreilly.com/radar/what-we-learned-from-a-year-of-building-with-llms-part-i/ -
https://www.reddit.com/r/ChatGPT/comments/12a0ajb/i_gave_gpt4_persistent_memory_and_the_ability_to/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
-
https://arxiv.org/abs/2412.09764#facebook: “Memory Layers at Scale”, -
https://arxiv.org/abs/2406.13121#google: “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, -
https://aibusiness.com/nlp/openai-chief-architect-predicts-huge-large-language-model-leaps: “OpenAI’s Colin Jarvis Predicts "Exponential" Advancements in Large Language Model Capabilities during AI Summit London Keynote”, -
https://arxiv.org/abs/2404.15574: “Retrieval Head Mechanistically Explains Long-Context Factuality”, -
https://arxiv.org/abs/2403.18802#deepmind: “Long-Form Factuality in Large Language Models”, -
https://arxiv.org/abs/2402.17152#facebook: “Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”, -
https://arxiv.org/abs/2401.08406#microsoft: “RAG vs Fine-Tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture”, -
https://arxiv.org/abs/2311.16452#microsoft: “Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine”, -
https://arxiv.org/abs/2310.03214#google: “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, -
https://arxiv.org/abs/2306.15626: “LeanDojo: Theorem Proving With Retrieval-Augmented Language Models”, -
https://arxiv.org/abs/2305.18466: “TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”, -
https://arxiv.org/abs/2305.16300: “Landmark Attention: Random-Access Infinite Context Length for Transformers”, -
https://arxiv.org/abs/2305.05665#facebook: “ImageBind: One Embedding Space To Bind Them All”, -
https://arxiv.org/abs/2305.01625: “Unlimiformer: Long-Range Transformers With Unlimited Length Input”, -
https://arxiv.org/abs/2304.14318#google: “Q2d: Turning Questions into Dialogs to Teach Models How to Search”, -
https://arxiv.org/abs/2304.06762#nvidia: “Shall We Pretrain Autoregressive Language Models With Retrieval? A Comprehensive Study”, -
https://arxiv.org/abs/2302.12433: “ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, -
https://arxiv.org/abs/2302.12173: “Not What You’ve Signed up For: Compromising Real-World LLM-Integrated Applications With Indirect Prompt Injection”, -
https://arxiv.org/abs/2212.10496: “Precise Zero-Shot Dense Retrieval without Relevance Labels”, -
https://arxiv.org/abs/2212.09410: “Less Is More: Parameter-Free Text Classification With Gzip”, -
https://arxiv.org/abs/2212.09741: “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, -
https://arxiv.org/abs/2212.03533#microsoft: “Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, -
https://arxiv.org/abs/2212.01349#facebook: “NPM: Nonparametric Masked Language Modeling”, -
https://arxiv.org/abs/2211.12561#facebook: “Retrieval-Augmented Multimodal Language Modeling”, -
https://arxiv.org/abs/2211.08411: “Large Language Models Struggle to Learn Long-Tail Knowledge”, -
https://arxiv.org/abs/2210.08726#google: “RARR: Attributed Text Generation via Post-Hoc Research and Revision”, -
https://arxiv.org/abs/2210.03350#allen: “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, -
https://arxiv.org/abs/2209.01975: “Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners”, -
https://arxiv.org/abs/2207.13061: “NewsStories: Illustrating Articles With Visual Summaries”, -
https://arxiv.org/abs/2207.06300#ibm: “Re2G: Retrieve, Rerank, Generate”, -
https://arxiv.org/abs/2206.05314#deepmind: “Large-Scale Retrieval for Reinforcement Learning”, -
https://openreview.net/forum?id=0ZbPmmB61g#google: “Boosting Search Engines With Interactive Agents”, -
https://arxiv.org/abs/2205.12910#allen: “NaturalProver: Grounded Mathematical Proof Generation With Language Models”, -
https://arxiv.org/abs/2205.05131#google: “Unifying Language Learning Paradigms”, -
https://arxiv.org/abs/2203.13224#facebook: “Language Models That Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion”, -
https://arxiv.org/abs/2201.10005#openai: “Text and Code Embeddings by Contrastive Pre-Training”, -
https://arxiv.org/abs/2112.09118#facebook: “Contriever: Towards Unsupervised Dense Information Retrieval With Contrastive Learning”, -
https://arxiv.org/abs/2112.09332#openai: “WebGPT: Browser-Assisted Question-Answering With Human Feedback”, -
https://openai.com/research/webgpt: “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, -
https://arxiv.org/abs/2112.07899#google: “Large Dual Encoders Are Generalizable Retrievers”, -
https://arxiv.org/abs/2112.04426#deepmind: “Improving Language Models by Retrieving from Trillions of Tokens”, -
https://arxiv.org/abs/2111.11432#microsoft: “Florence: A New Foundation Model for Computer Vision”, -
https://arxiv.org/abs/2111.07991#google: “LiT: Zero-Shot Transfer With Locked-Image Text Tuning”, -
https://arxiv.org/abs/2111.11294: “Scaling Law for Recommendation Models: Towards General-Purpose User Representations”, -
https://arxiv.org/abs/2203.08913#google: “Memorizing Transformers”, -
https://openreview.net/forum?id=qw674L9PfQE: “CLOOB: Modern Hopfield Networks With InfoLOOB Outperform CLIP”, -
https://arxiv.org/abs/2108.08877#google: “Sentence-T5: Scalable Sentence Encoders from Pre-Trained Text-To-Text Models”, -
https://arxiv.org/abs/2107.07566#facebook: “Internet-Augmented Dialogue Generation”, -
https://arxiv.org/abs/2106.11097: “CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”, -
https://arxiv.org/abs/2104.07567#facebook: “Retrieval Augmentation Reduces Hallucination in Conversation”, -
https://syncedreview.com/2021/03/23/chinas-gpt-3-baai-introduces-superscale-intelligence-model-wu-dao-1-0/#baai: “China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model.”, -
https://arxiv.org/abs/2102.05918#google: “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, -
https://www.youtube.com/watch?v=kY2NHSKBi10: “The Importance of Deconstruction”, -
https://arxiv.org/abs/1904.08378: “Dynamic Evaluation of Transformer Language Models”, -
1982-cover.pdf: “This Week’s Citation Classic: Nearest Neighbor Pattern Classification”,